
引言:速度的幻象
近二十年来,端到端(E2E)测试一直是软件开发生命周期(SDLC)中成本最高、可靠性最低的环节。传统上,构建一套健壮的测试套件需要投入大量的人力;往往需要资深工程师花费数周的时间,手动将用户流程映射到复杂的测试脚本中。随后出现了 Playwright 和 Cypress 等现代化框架,它们承诺通过在浏览器内模拟交互,弥合代码与用户之间的鸿沟。
然而,在其令人印象深刻的 API 之下,隐藏着一个根本性的架构限制:这些框架优化的是结构正确性,而非感知正确性。它们分析并操作文档对象模型(DOM),而这种结构抽象往往无法准确地反映渲染后的实际效果。仅仅因为代码中存在一个
人们常将 Playwright auto-wait 这样的工具视为一种解决方案,但这并不能消除数据加载竞争条件或布局偏移问题。本质上,自动等待是一种 DOM 稳定性启发式策略:它可以确保节点在交互过程中已挂载、可见且未被移除,但并不能保证事件监听器已完全绑定、异步状态变更已稳定,或者渲染的布局反映了最终的交互状态。在基于 React 和 Next.js 等框架构建的现代 SSR 架构中,从 DOM 的角度看,界面可能看上去是稳定的,但从用户的角度看,它仍可能存在时序不稳定性。
与此同时,该行业正经历着一场彻底的转型。AI 驱动的生成技术彻底消除了创建测试用例的门槛。借助自主代理,团队现在只用几分钟就能生成数十个复杂的测试场景,由此开启了即时测试覆盖的新时代。
然而,这种转变揭示了一个关键的洞见:AI 会放大其构建所依赖的任何抽象层。如果该抽象层在结构上存在脆弱性,AI 就会放大这种结构脆弱性。当 AI 代理通过解析代码而非关注接口来生成测试时,它们会优先考虑“完成路径”,而非构建可靠的测试。如果一个代理生成了 1000 个基于易变 XPath 或随机 CSS 类的测试,这并不会提升你的测试覆盖率;它只不过是自动以 10 倍的速度制造了 1000 个未来的故障点。
这会导致维护工作积压,因为测试机器人缺乏人类用户那种自然的犹豫。人类测试人员会凭直觉等待布局调整稳定下来或页面加载完成,而 AI 测试机器人会优先优化即时执行。它可能会“成功地”点击代码中一个技术上可见、但当前被加载旋转指示器覆盖或被“幽灵交互”窗口遮挡的按钮。核心问题在于,当前工具验证的是代码(结构),而非渲染后的实际效果(感知)和业务结果(意图)。当 AI 加速这种代码层面的测试时,它只会加剧测试脚本与实际用户体验之间的脱节。
本文的核心观点是:要构建一个可靠且高速的自动化未来,我们必须停止扩展以 DOM 为中心的抽象模型,转而建立一种基于感知和意图的新测试范式。
根本原因:感知鸿沟
现代 Web 自动化技术面临的根本性困境,源于机器“解析”应用程序的方式与人类“体验”应用程序的方式之间存在不匹配。这种差异就是所谓的“感知鸿沟”。
结构验证 vs. 感知验证
要理解这种差距,不妨考虑一下下面这个交互模型:
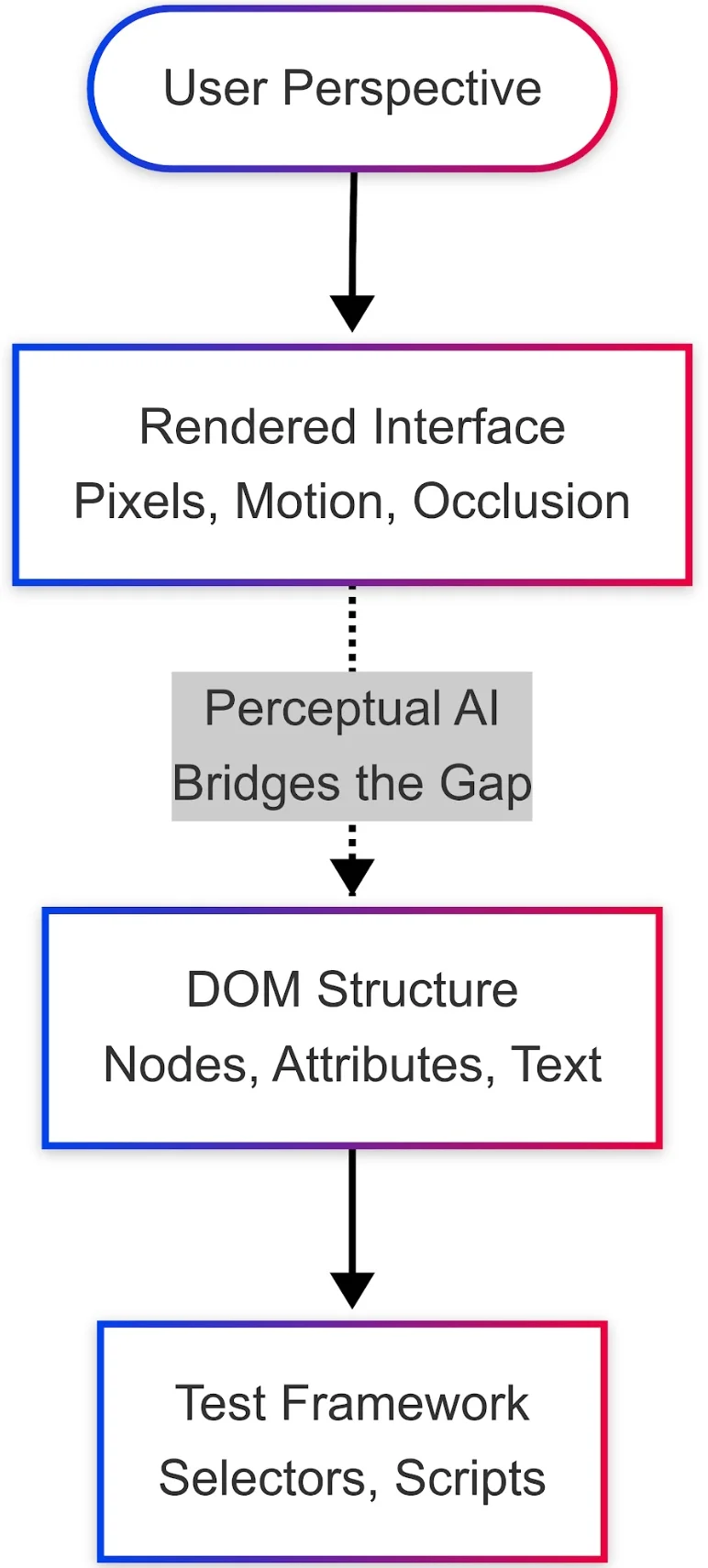
图 1: “架构感知鸿沟”展示了执行框架定位器与实际用户视口体验之间的不同步现象(图片由作者创建)
标准的端到端(E2E)测试框架基于结构验证(底层)。从机器的角度来看,如果某个节点存在且未被显式标记为 display: none ,则验证即告完成。相比之下,人类用户则进行感知验证(顶层)。用户并不关心 CSS 类名,他们关注的是其视觉表现。如果粘性页眉遮挡了按钮,人类会认为界面被阻挡,但机器可能仍会“成功”地点击遮挡层,并针对一个从未完成的操作报告“通过”。
同样,一个带有蓝色文字的蓝色按钮对以 DOM 为中心的脚本来说是“可见”的,但对人类而言却是功能不可见的。
无障碍树错觉
如今,工具能够高保真地“读取”无障碍树(AX Tree),提供诸如“购买按钮”之类的语义标签,而非易失性的 XPath。然而,这可能会给人一种误导性的完整感。在数据加载或 CSS 驱动的状态变更过程中,语义元数据与渲染后的视觉状态之间可能会产生偏差。测试可能在元数据中将按钮识别为“启用”状态,而用户却因为 CSS 滤镜或 React 状态不匹配,看到了一个褪色且无法使用的灰色块。仅依赖元数据而缺乏视觉依据,就像使用一张五年前的地图在城市中导航——数据虽然精确,却已与现实地形不符。
技术危机:视觉不同步危机
现代 Web 架构引入了一种新型的竞争条件:视觉不同步。当用户界面未能准确反映底层应用程序的状态或数据时,就会发生视觉不同步,从而导致音视频不同步、数据过时或界面闪烁等不一致现象。虽然单页应用(SPA)时代,服务器端渲染(SSR)水合过程让这一问题广为人知,但在现代技术栈中,“视觉可用性”与“功能就绪性”之间的差距普遍存在。
同步窗口:已绘制但未启用
无论是由于 React 的初始化、复杂的 CSS 动画序列、延迟加载的字体导致布局偏移,还是动态功能开关延迟评估 UI,结果都一样:浏览器渲染出的画面视觉上看起来已经完整。用户几乎瞬间就看到了按钮,对于结构化测试而言,应用程序似乎已经准备就绪。
然而,这种视觉状态其实处于一种“恐怖谷”之中。这段时间(即“同步窗口”)是应用程序真正稳定下来所需的时间。在事件监听器绑定完成、功能开关解析完毕以及动画结束之前,用户界面实际上只是一个具备交互性外观的假象。
幽灵交互:点击虚空
这种差距导致了“幽灵交互”现象。如果测试在 JavaScript 处理程序挂接之前,或者按钮沿 Z 轴移动的过程中触发了点击事件,该事件就会向上冒泡并消失。应用程序不会做出任何反应。对于标准的端到端测试框架而言,这会被视为一次“成功”的操作(但随后会导致断言失败),从而产生一份“通过”测试的报告,而这些交互在逻辑上从未发生过。
下图展示了视觉就绪与功能就绪之间的差距。当测试在此不稳定的时间窗口内进行交互时,就会发生“幽灵点击”。
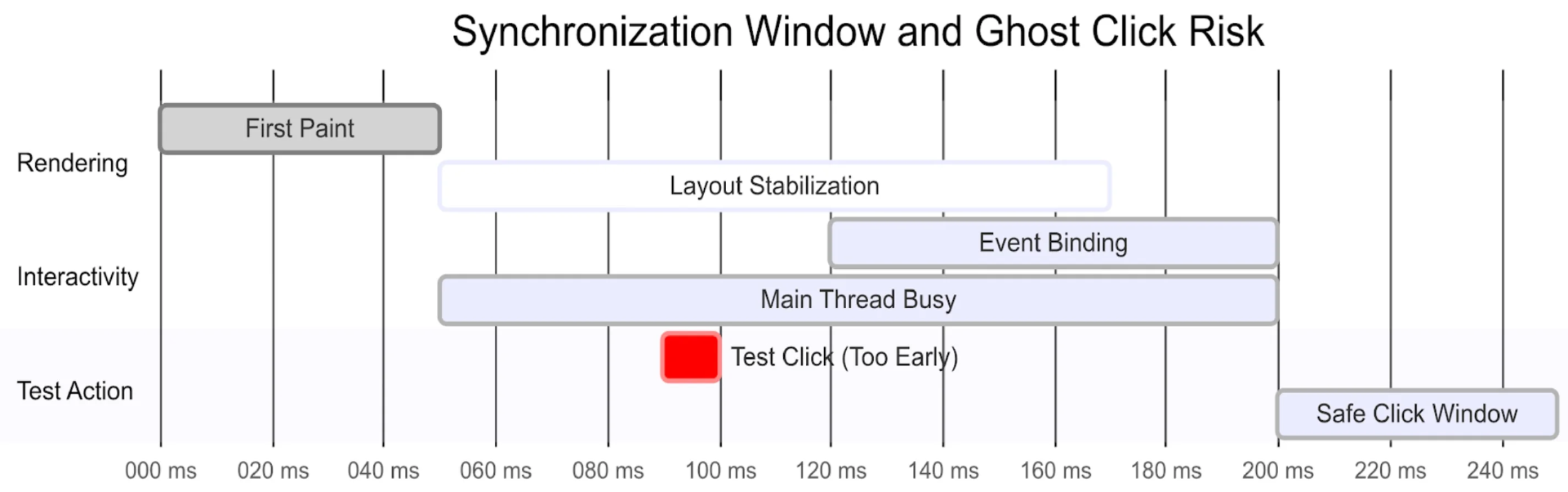
图 2:SPA 加载过程中的“恐怖谷”现象:渲染就绪(paint)状态的达成速度快于主线程功能性事件监听器的注册,从而导致自动化脚本出现了高风险的“幽灵点击”偏差(图片由作者创建)
实战证据:生产中的三种失效模式
有三种具体的故障模式反复成为导致“维护成本”的主要因素:
“幽灵点击”(水合缺口):像 Playwright MCP 这样的高速 AI 工具会识别出“提交”按钮,并在 FCP 之后、监听器挂接之前的一瞬间点击该按钮。由于预期中的导航操作并未发生,所以测试最终失败。虽然交互操作成功了,但断言却失败了。
状态回退竞争(useEffect 陷阱):用户更新一个字段(例如,将 Quantity 从 1 改为 5),随即点击“提交”。在两个步骤之间不到 50 毫秒的时间窗口内,useEffect 钩子被触发,并将本地状态重置为默认值。服务器接收到的便是默认数据,而非用户的输入。
超时螺旋(脆弱点):为了“解决”测试结果不稳定的问题,开发人员将全局超时时间设为 60 秒。这会引发“超时螺旋”,导致测试套件运行极其缓慢,进而掩盖性能退化问题,并使工程师将失败归因于“只是测试结果不稳定”。
实际案例:在进行全局超时和多次本地超时调整后,测试套件的执行时间从 5 分钟延长至 8 分钟(增幅超过 50%)。
实际案例:由于数据加载延迟或布局偏移引发的故障,我们的持续集成管道不得不多次运行,这延缓了构建,并影响了发布速度。
三个验证维度
为了突破现有框架的局限,我们必须针对测试的具体内容建立一个连贯的理论框架。现代 Web 自动化需要验证三个不同的维度:
结构测试用于验证代码是否存在。它会问:“该节点是否已附加到 DOM 上?”这是现有工具的强项,但这还不足以保证可用性。
感知测试用于验证渲染后的可操作性。它提出的问题是:“该元素在视觉上是否可见,人类用户能否通过视觉发现它?”这涉及 Z-index 遮挡、不透明度和对比度等因素。
意图测试用于验证业务结果。它提出的问题是:“此次交互是否实现了功能目标(例如更新数据库或更改应用程序状态)?”这有助于防范幽灵点击和状态回退竞争。
真正的范式转变需要一套能够同时评估这三个维度的测量体系。
迈向基于感知与意图的验证
要摆脱生产力悖论,我们必须停止构建仅测试结构有效性的代理,而要开始构建针对感知和意图进行优化的系统。
1. 感知觉察
真正的可靠性要求代理以渲染出的像素为准,而非 DOM 节点。一个与感知相一致的系统不会依赖于 ID 查询;它会验证“保存”按钮在视觉上是否可见、具有高对比度,而且未被粘性页眉或加载提示框遮挡。
感知觉察意味着系统必须进行以下方面的推理:
视觉遮挡:识别 Z-index 层(如模态框或提示框)何时导致目标无法点击。
对比度与易读性:验证最终用户能否通过视觉识别出某个操作。
空间逻辑:理解按钮的功能通常由它与其他视觉元素的邻近关系决定,而不仅仅取决于其在 HTML 树中的位置。
2. 时序推理
在现代单页应用(SPA)中,就绪状态是一种动态状态,而非二元状态。在进行交互前,基于感知的代理会自然地等待“微闪”消失或布局稳定下来。
时序推理使系统能够感知布局速度。它会监控以下方面:
累计布局偏移(CLS):在元素仍在移动时拒绝交互。
水合状态:通过观察主线程的空闲状态,区分“已绘制”按钮与“已激活”按钮。
状态稳定:识别瞬时加载状态与最终交互状态之间的差异。
3. 意图建模
基于感知和意图的自动化其最先进的能力在于能够提出这样的问题:“哪种操作能从功能上满足这一目标?”传统的脚本会盲目执行硬编码的路径;一旦路径的结构发生变化,它们就会失效。然而,基于意图的代理则能利用目标导向的推理来满足用户意图。
意图建模使代理能够:
处理语义漂移:如果按钮标签从“购买”变为“加入购物车”,那么代理能理解其功能意图保持不变。
遵守安全防护规则:识别高风险警告(例如“这将删除所有数据”),并暂停以等待人工审核,而非通过“自我修复”导致灾难性后果。
验证结果:确保操作结果(即业务目标)已达成,而非仅仅确认点击事件已被触发。
从理论到实践:混合感知管道的实现
为了使基于感知和意图的测试具有可操作性,工程团队无需牺牲 Playwright 或 Cypress 等框架的执行速度。相反,他们可以通过混合感知管道来增强这些框架的功能。
这种方法将浏览器插桩(用于时序稳定性)与智能视觉层(用于语义自愈)相结合。
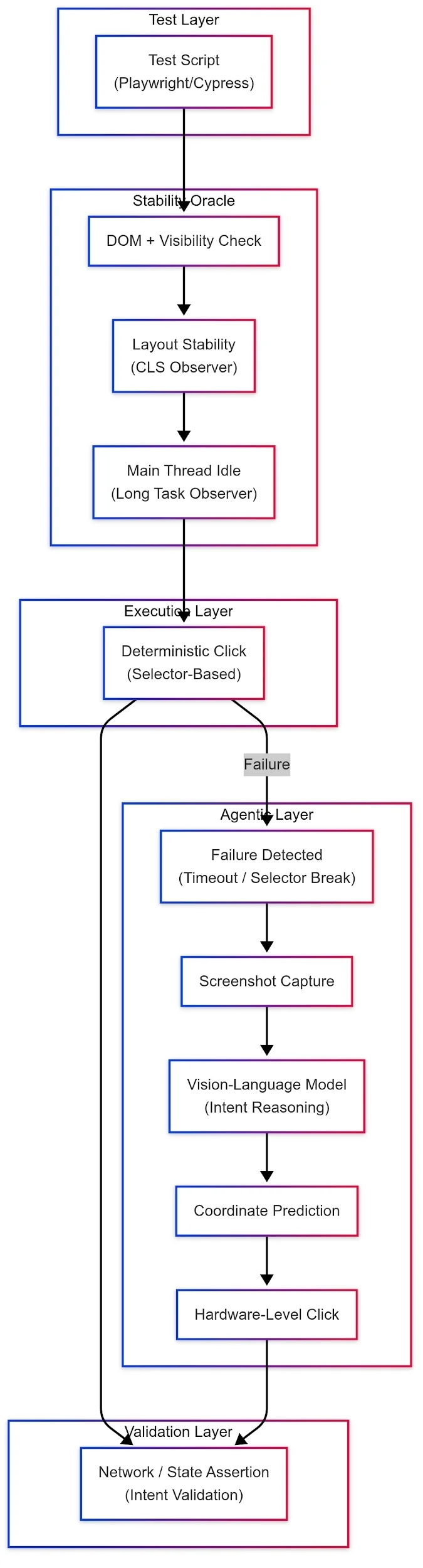
图 3:混合感知管道的系统架构:利用确定性浏览器遥测数据处理常规执行路径,并通过自动化的 LLM 视觉备用方案实现运行时选择器的自愈功能(图片由作者创建)
实例:稳定性预言机 + 代理回退 + 意图验证
步骤一:稳定性预言机(浏览器插桩)
第一步是消除由加载延迟(水合陷阱)引起的“幽灵点击”。我们不再盲目依赖 DOM 的可见性,而是通过注入原生浏览器监控机制来验证界面是否已经准备就绪。
在进行交互之前,框架会轮询 PerformanceObserver ,以确保累计布局偏移(CLS)为零,从而保证在测试点击按钮的瞬间,按钮位置不会发生偏移。
/** typescript **/import { Page } from 'playwright';/*** 仅在元素视觉上已经稳定且可交互时才点击该元素。* 与框架无关:不依赖于单页应用(SPA)特有的全局标志.** 执行的检查:* 1. 元素存在且可见* 2. 布局稳定(累积布局偏移)* 3. 已绑定事件监听器(可点击)* 4. 主线程空闲(浏览器已稳定)** @param page Playwright Page 对象* @param selector 目标元素的 CSS 选择器* @param timeout 以毫秒为单位的最大等待时间(默认 5000)*/export async function clickWhenPerceptuallyStable( page: Page, selector: string, timeout: number = 5000) { // 步骤 1:等待,直到元素存在且可见 const element = page.locator(selector); await element.waitFor({ state: 'visible', timeout }); // 步骤 2:引入布局偏移和长时间任务跟踪 await page.evaluate(() => { if (!window.__clsScore) window.__clsScore = 0; if (!window.__lastLongTaskTime) window.__lastLongTaskTime = 0; new PerformanceObserver(list => { for (const entry of list.getEntries()) { if (!entry.hadRecentInput) window.__clsScore += entry.value; } }).observe({ type: 'layout-shift', buffered: true }); new PerformanceObserver(list => { for (const entry of list.getEntries()) { window.__lastLongTaskTime = entry.startTime; } }).observe({ type: 'longtask', buffered: true }); }); // 步骤 3:等待直到感知稳定 await page.waitForFunction( (selector) => { const elem = document.querySelector(selector); if (!elem) return false; // 元素的可见性与尺寸 const rect = elem.getBoundingClientRect(); const isVisible = rect.width > 0 && rect.height > 0; // 事件监听检查(仅限 Chrome DevTools ) const listeners = (window as any).getEventListeners?.(elem)?.click || []; // 注意:这可能无法检测到委托监听器(例如 React 的合成事件) const hasClickListener = listeners.length > 0; // 布局稳定 const clsScore = (window as any).__clsScore || 0; const stable = clsScore < 0.05; // 主线程空闲启发式算法(近期无长时间运行的任务) const idle = performance.now() - (window as any).__lastLongTaskTime > 100; return isVisible && hasClickListener && stable && idle; }, selector, { timeout } ); // 步骤 4:安全地点击 await element.click();}注意:getEventListeners 仅在基于 Chromium 的环境中可用。在跨浏览器持续集成(CI)管道中,应将其替换为应用程序级的就绪信号或交互探针(例如,模拟点击 + 状态验证)。
步骤二:基于代理的备用方案(视觉-语言模型)
如果因为开发人员将 #btn-checkout 改为 #submit-cart,导致上一步中的选择器失败,那么标准测试就会崩溃。在此,我们引入了代理推理层。
测试不会导致构建失败,而是捕获超时事件,并将视口传递给 GPT-4o 等视觉-语言模型(VLM)。该 VLM 如同人类 QA 工程师,通过对页面做视觉扫描来定位预期操作,并返回精确坐标,从而在运行时“自我修复”测试。
/** typescript **/async function resilientClick(page: Page, selector: string, intent: string) { try { // 快速的确定性路径 await clickWhenPerceptuallyStable(page, selector); } catch (error) { console.warn(`Selector '${selector}' failed. Triggering VLM fallback.`); // 慢速概率路径:视觉模型定位目标 const screenshot = await page.screenshot({ type: 'jpeg' }); const {x, y, confidence, suggestedSelector} = await askVisionModelForTarget(screenshot, intent); // pseudo-code if (confidence < 0.8) { throw new Error(`Could not find target for intent: ${intent}`); } // 在预测的坐标处进行硬件级点击 await page.mouse.click(x, y); // 向 CI/CD 管道报告自愈事件 reportSelfHealingEvent(selector, suggestedSelector); }}步骤三:意图验证
由于备用方案采用了概率性 AI,所以我们必须通过确定性的意图验证来闭环。我们不验证是否点击了特定的按钮,而是验证业务结果是否已经在网络层实现。
/** typescript **/// 确认业务结果,与用户界面无关const apiResponse = await page.waitForResponse('**/api/orders/submit');const responsePayload = await apiResponse.request().postDataJSON();expect(responsePayload.status).toBe('processing');架构权衡与运营约束
从基于 DOM 的确定性测试向混合感知管道的过渡涉及若干策略权衡。我们的实现方案是基于以下架构和运营方面的发现而形成的:
选择性感知与延迟:为最大限度地降低视觉语言模型(VLM)推理中非微不足道的延迟和计算成本,我们放弃了“全程视觉”模型。取而代之,我们采用了选择性视觉策略:常规导航依赖于结构化元数据和交互前的审核(通过性能观察器实现)。而计算成本高昂的视觉推理则严格保留给高价值的端到端流程以及关键验证检查点,在这类场景中,我们优先考虑的是鲁棒性而非执行速度。
感知差距与设计系统锚点:我们发现了一种“感知差距”,即某些元素虽然通过了结构可见性检查,但由于颜色或对比度问题,在功能上仍然不可见。我们通过将代理锚定在标准化设计系统中来缓解这一问题。虽然这提供了必要的渲染保障,但对于布局变化剧烈或基于画布进行大量渲染(例如 WebGL)的应用程序,对高频感知验证的需求会增加,特别是在遮挡检测等空间推理任务中。
实施与迁移工作量:开发 DOM 与像素缓冲区之间的同步层,需要一个小型跨职能团队(测试自动化 + 机器学习工程)集中精力投入约一个财季。为了便于采用该方案且不重构现有的测试套件,我们采用了感知封装策略,即在现有选择器之上叠加视觉验证和 AI 辅助恢复功能,从而实现分阶段部署。
组织采用:一个重大的非技术性障碍在于,如何引导团队从确定性的“通过/失败”断言转向基于信度的结果。我们通过“影子模式”阶段解决了这一问题。在这个阶段,混合系统与现有测试并行运行,而且不作为发布的前置条件。这使得团队能够在将模型推广到正式生产环境之前对模型的可靠性建立起实证信任。
超越简单的“通过/未通过”二元评价:RPS 指标
要解决 AI 的生产力悖论,我们必须改变衡量成功的标准。简单的“通过/未通过”结果是不够的,因为它们无法揭示测试在底层为何通过或失败。
我们提出了“韧性与感知评分”(RPS),这是一个用于评估测试系统的基准框架,旨在评估那些声称能够理解感知与意图(而非仅关注结构信号)的系统。RPS 不依赖于特定的模型架构或工具链,它是一种评估视角,用于判断测试系统是否验证了呈现的现实与业务意图,而非仅仅验证结构上的巧合。
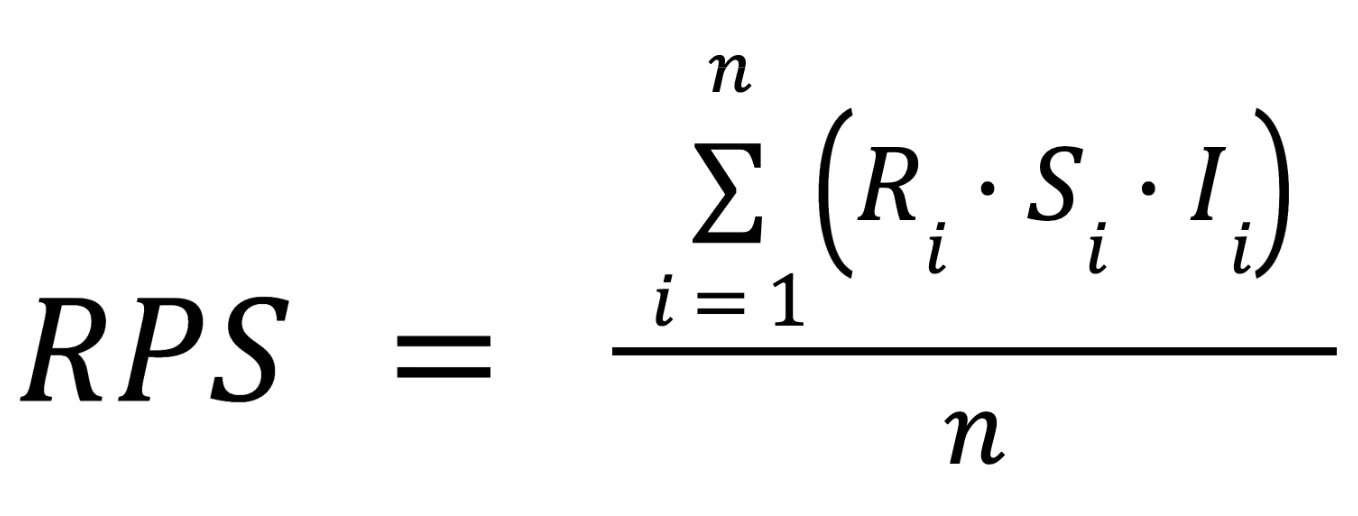
注:乘法形式反映了这样一个事实:任何一个维度的失效都会导致整体可靠性崩溃
R(可靠性):代理与技术环境(水合状态、布局稳定性及 CPU 空闲状态)保持同步的能力。
测量方法:利用 PerformanceObserver 和 layout-shift 条目,监控交互发生前 100 毫秒时间窗口内浏览器的主线程活动及布局速度。
S(语义同步):代理将视觉目标映射到结构元素的能力,而且不受无意图的代码变化所影响。
测量方法:使用变异注入(通过编程方式更改目标的 ID、类或标签),并测量代理在识别同一功能目标时的视觉信心。
I(意图对齐):指代理的行为与预期业务结果的契合程度,以及对安全防护措施的遵守程度。
测量方法:执行状态预言机检查——在交互结束后立即验证应用程序的最终状态(例如 Redux 存储、API 有效载荷或数据库副作用)。
结论:验证结果,而非代码
AI 生产力悖论是我们开展这项研究的必要契机。它揭示了一个事实:扩展脆弱的结构化抽象只会增加技术债务。为了构建一个可靠的 Web 自动化未来,我们必须在采用 RPS 等度量框架的同时,结合基于感知和意图的测试方法。
关键在于,基于感知测试可以通过多种方式实现,包括使用视觉模型、浏览器插桩、混合观察器或代理推理层。这种范式转变并非旨在取代 Playwright 或 Cypress 等框架,而是为了增强我们的验证逻辑,从而真正看到用户看到的内容。
自动化从来就不是为了验证 HTML 节点而存在的。它的初衷是确保软件能够满足用户的需求。随着 AI 加速软件开发进程,整个行业必须超越对结构一致性的验证,开始验证感知现实和功能意图。只有这样,自动化才能真正测试用户的实际体验。
原文链接:https://www.infoq.com/articles/solving-ai-productivity-paradox-test-automation/




