
前天,在 X 上,有网友称 AWS、谷歌云、Azure 和 Cloudflare 同一时间发生了中断。
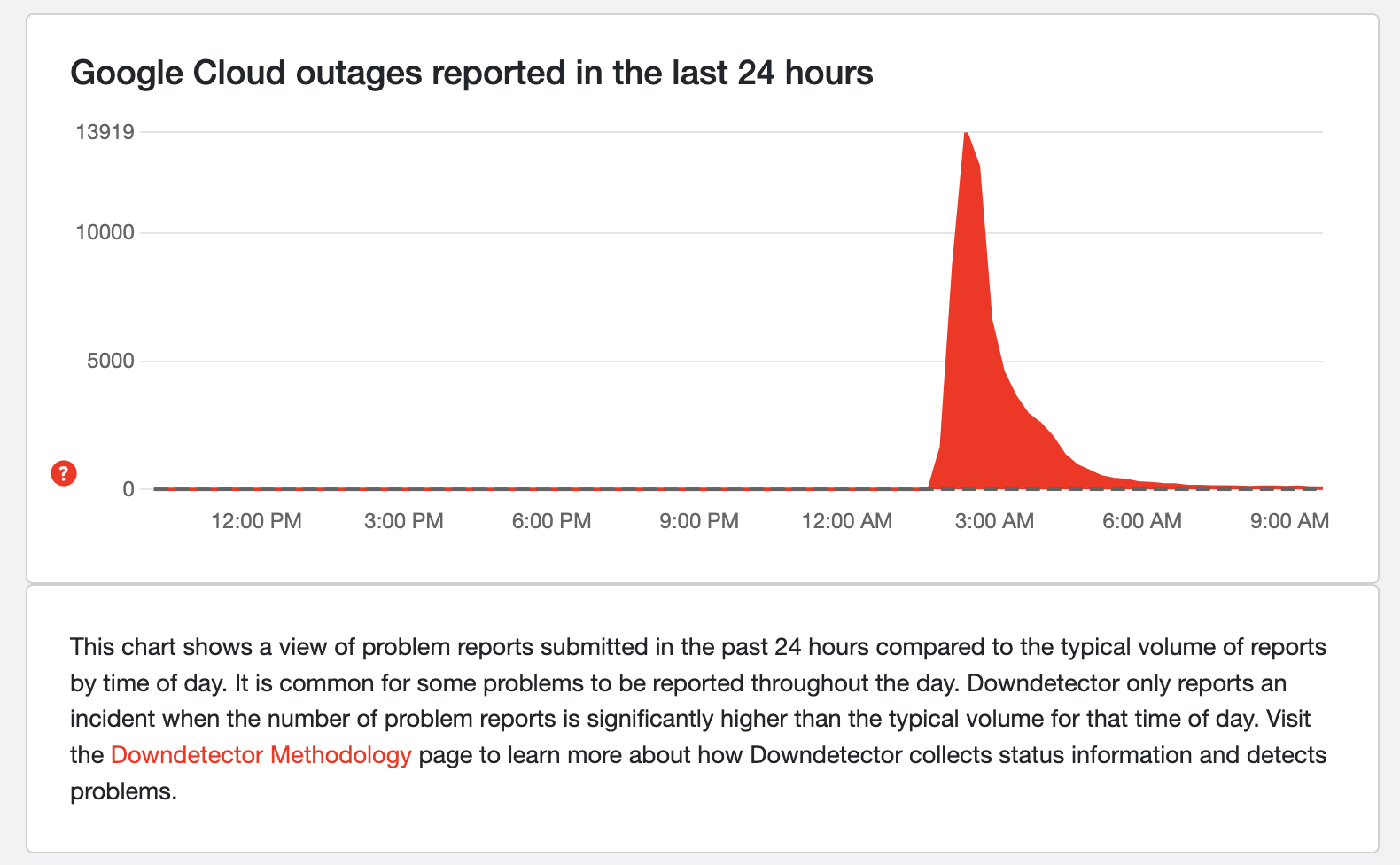
宕机追踪网站 Down Detector 网站显示,太平洋夏时令时间上午 11:30 左右,Google Cloud 报告了超过 13000 起事件。
截至周四太平洋夏时令上午 11:49,云计算巨头微软 Azure 在 Down Detector 上记录了约 1000 份中断报告,到太平洋时间下午 12:49,报告数量下降到 251 份。
差不多同一时间,AWS 在 Down Detector 上记录了约 5000 份中断报告。
但微软和 AWS 其状态页面显示没有问题。
据 Down for Everyone 网站数据显示,Character AI 于周四太平洋夏时令上午 11:19 已收到约 4000 份中断报告。
此外,ChatGPT 的创建者 OpenAI 表示,它遇到了一些与单点登录“和其他登录方式”相关的问题。该公司在一篇社交媒体帖子中表示,其“工程团队正在努力缓解这些问题”。此外,有网友曝出 Claude Sonnet 4(Cursor)和 Gemini Pro 也出现了很多错误。
谷歌云服务全球瘫痪 3 小时
在所有中断服务中,谷歌云服务在全球范围内宕机最严重,导致谷歌旗下和第三方应用程序以及平台等许多其他服务出现一系列中断。
当时,宕机追踪网站 Down Detector 的峰值开始飙升。Down Detector 网站显示,太平洋夏时令时间上午 11:30 左右,Google Cloud 报告了超过 13000 起事件,不过到下午早些时候,这一数字已大幅下降。
谷歌表示,由于身份和访问管理服务(IAM)问题,GCP(谷歌云平台)的多个产品受到影响,包括 Gmail、 Google Calendar、Google Chat、Google Cloud Search、Google Docs、Google Drive、Google Meet、Google Tasks 以 及 Google Voice。多个 Workspace 产品也遇到了服务问题。
谷歌云的状态页面显示: “我们的多款 GCP 产品遇到了服务问题” ,并指出服务中断始于太平洋夏时令时间上午 10:51。“我们的工程团队正在继续调查此问题。”

十几分钟后,谷歌表示,客户“仍在遭受不同程度的影响”,工程师正在努力恢复服务,但公司尚未确定修复的预计时间。

随后,经过快速的修复,太平洋夏时令下午 12 点 41 分,谷歌在谷歌云状态页面上表示,“我们的工程师已经找到了根本原因并采取了适当的缓解措施。虽然我们的工程师已确认除 us-central1 之外的所有位置的底层依赖关系均已恢复,但我们注意到,客户在各个 Google Cloud 产品上仍会受到不同程度的影响。所有相关工程团队均已积极参与并致力于服务恢复。我们还没有全面恢复服务的预计到达时间。我们将在太平洋夏令时间 2025 年 6 月 12 日星期四 13:30 之前提供最新详细信息。”

太平洋夏时令下午 14:00 点时,谷歌又在谷歌云状态页面上更新了最新进展。
谷歌表示:“我们已在 us-central1 和美国多个地区针对该问题实施了缓解措施,并看到了恢复的迹象。我们已收到来自内部监控和客户的确认,表明谷歌云产品在多个地区也正在恢复,在 us-central1 和美国多个地区也出现了一些恢复的迹象,”谷歌云表示,预计恢复将在一小时内完成。

太平洋夏时令下午 15:16 ,谷歌云表示:“截至太平洋夏令时间 13:45,大多数 Google Cloud 产品已完全恢复。”
但仍然有一部分产品没有恢复服务,包括 Google Cloud Dataflow: 由于积压问题正在逐步清除,客户在使用 Dataflow 操作时可能会遇到延迟;Vertex AI 在线预测:客户在使用 Model Garden 中的某些模型时可能会继续遇到 5xx 错误增多的情况;个性化服务健康:个性化服务健康的更新延迟,我们建议客户继续使用云服务健康仪表板进行更新。
到了太平洋夏时令下午 18:27,谷歌云表示,所有服务均已恢复正常。

在主要服务经历了近三个小时的大规模瘫痪后,不少企业因谷歌云的宕机受到了严重影响。
Shopify、Cloudflare 成严重“受灾区”
具体而言,除了谷歌旗下应用和服务外,还有谁受到了严重影响?
电子商务软件供应商 Shopify 是谷歌云的主要客户,是这次宕机受影响最严重的企业之一。他们在 X 上的一篇帖子中表示,“已意识到一个影响多项服务的问题”。
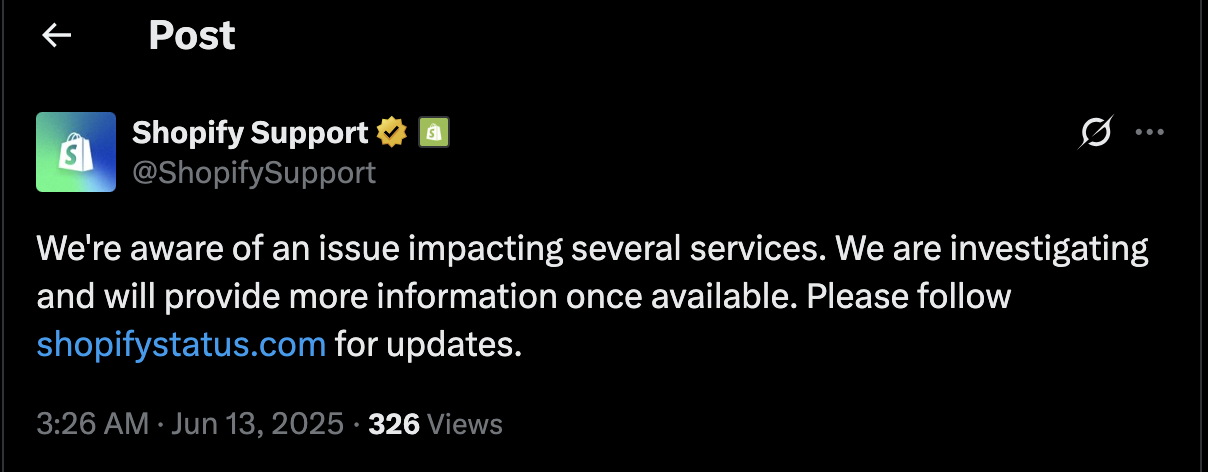
太平洋夏时令下午 2:15 刚过,Shopify 的 Down Detector 报告数量激增,从那以后就一直存在问题,在最初的中断发生后很长时间内,报告仍在持续涌入。
从那时起,Shopify 的访问量就一直在稳步下降,尽管在谷歌平台基本恢复之后,Shopify 的问题也花了更长时间才得以解决。
此次 Shopify 瘫痪持续了大约 3 个小时,但此后的颓势还持续了几个小时。
Cloudflare 也被谷歌“害惨了”。
Cloudflare 的一位发言人在接受媒体采访时表示:“这是一次谷歌云中断。Cloudflare 的少数服务使用谷歌云,因此受到了影响。我们预计它们很快就会恢复。Cloudflare 的核心服务并未受到影响。”
至于更具体的中断原因,Cloudflare 在发布到 Cloudflare 状态页面的更新中,他们将其“关键 Workers KV 服务”的故障归咎于“关键依赖的第三方服务中断”。
也就是说,由于关键依赖的第三方发生服务中断,所以某些依赖 KV 服务存储和传播信息的 Cloudflare 产品就无法使用了。
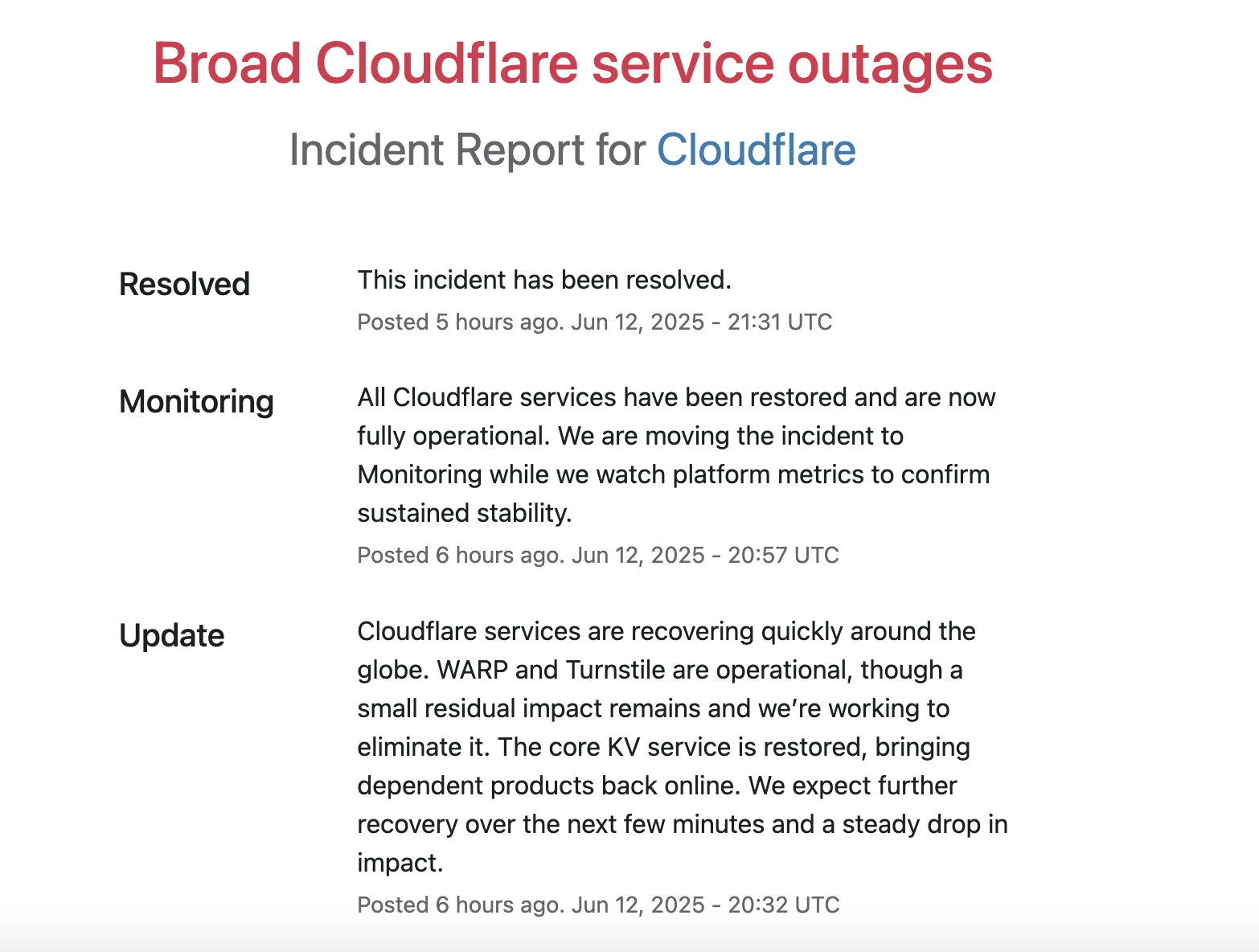
有趣的是,Cloudflare 在太平洋夏令时间 11:19 发布了有关其自身问题的消息,这表明它在谷歌向客户通报其问题之前就已经感受到了影响。
太平洋夏令时间 12:12,Cloudflare 报告称“服务开始恢复”,但警告称,“随着系统处理重试和缓存被填满,我们预计受影响的服务仍会出现间歇性错误。”
Cloudflare 于太平洋时间下午 1:57(世界协调时间 UTC 20:57)在其状态网页上表示,“所有 Cloudflare 服务已恢复,现已全面投入运营”。
该公司表示,将继续“关注平台指标,以确保持续稳定”。
Cloudflare 称,自中断服务起,受到影响的 Cloudflare 服务包括 Access、WARP、Realtime、Workers AI、Stream、Cloudflare 仪表板的部分内容和 AutoRAG。
Cloudflare 是一家主要的网络安全和内容分发网络提供商。周四,该公司股价下跌了 5%。
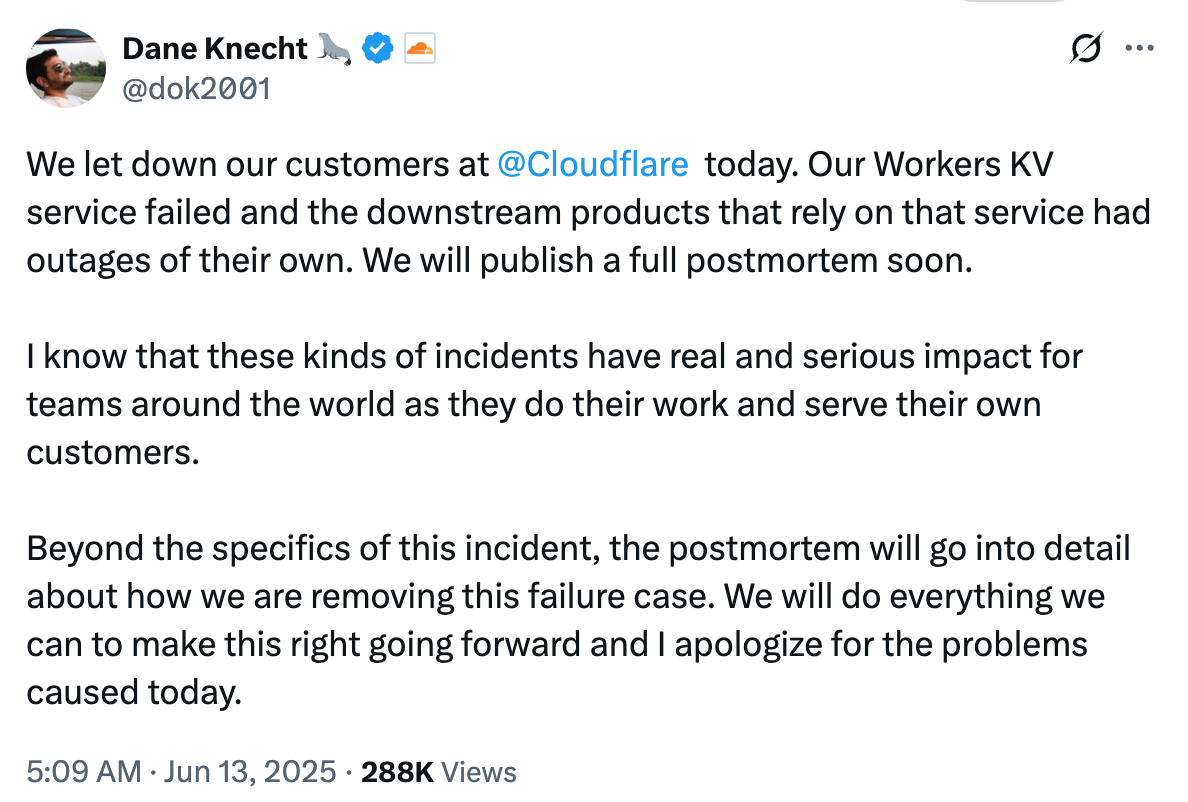
刚刚,Cloudflare CTO Dane Knecht 在 X 发帖就此次中断事件向客户致歉,并表示将很快发布完整的事后分析报告。
“我们让 Cloudflare 客户失望了 。我们的 Workers KV 服务发生故障,依赖该服务的下游产品也出现了故障。我们将很快发布完整的事后分析报告。
我知道,此类事件对于世界各地的团队开展工作和服务客户而言,有着真实而严重的影响。
除了此次事件的具体细节外,事后分析还将详细说明我们如何移除此故障案例。我们将竭尽全力纠正此问题,并对今天造成的问题深表歉意。”
为什么会宕机?
谷歌此次宕机事件影响范围非常广,多家软件服务公司和 AI 企业受到影响。因此谷歌此次宕机发生的原因成为了公众关注的重点,并在 Hacker News、X 等平台上引发热议。
在 Hacker News 上,有用户猜测,是谷歌一个名为 Chemist 的服务出现了故障。
“看起来是谷歌的一项名为 Chemist 的服务出现了故障。该服务负责检查多项关键策略,包括项目状态、激活状态、滥用状态、计费状态、服务状态、位置限制、VPC 服务控制以及 SuperQuota 等。这一故障完全解释了用户遇到的 ‘可见性检查(API)失败’ 和 ‘无法加载策略’ 错误提示,同时也导致了大量相关服务受到影响。”
有网友对上述观点表示赞同,“多个互联网服务都瘫痪了,不仅仅是 GCP。Chemist 服务可能主要受到外部影响,所以故障才会蔓延到其内部的 GCP 网络服务。”
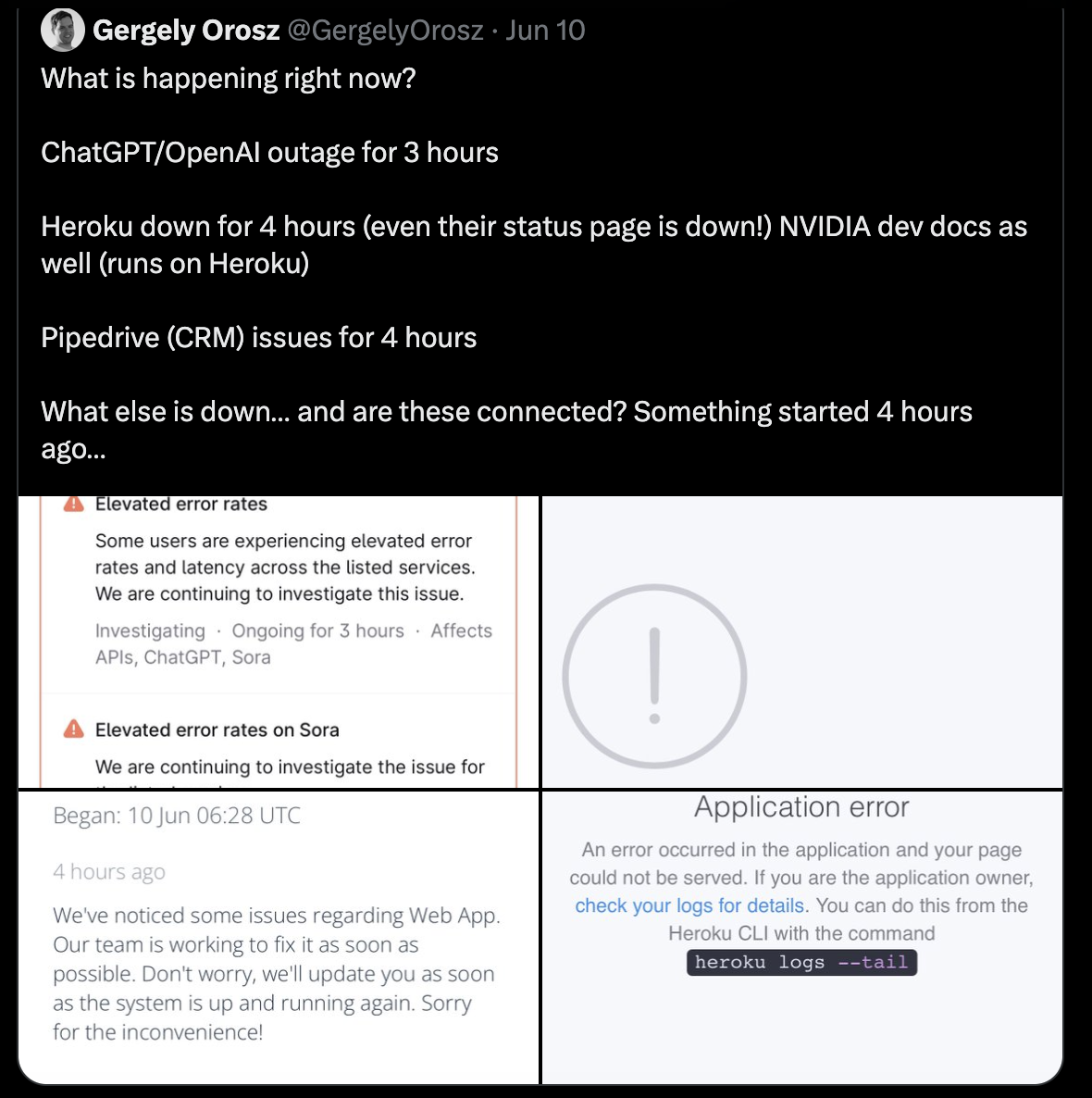
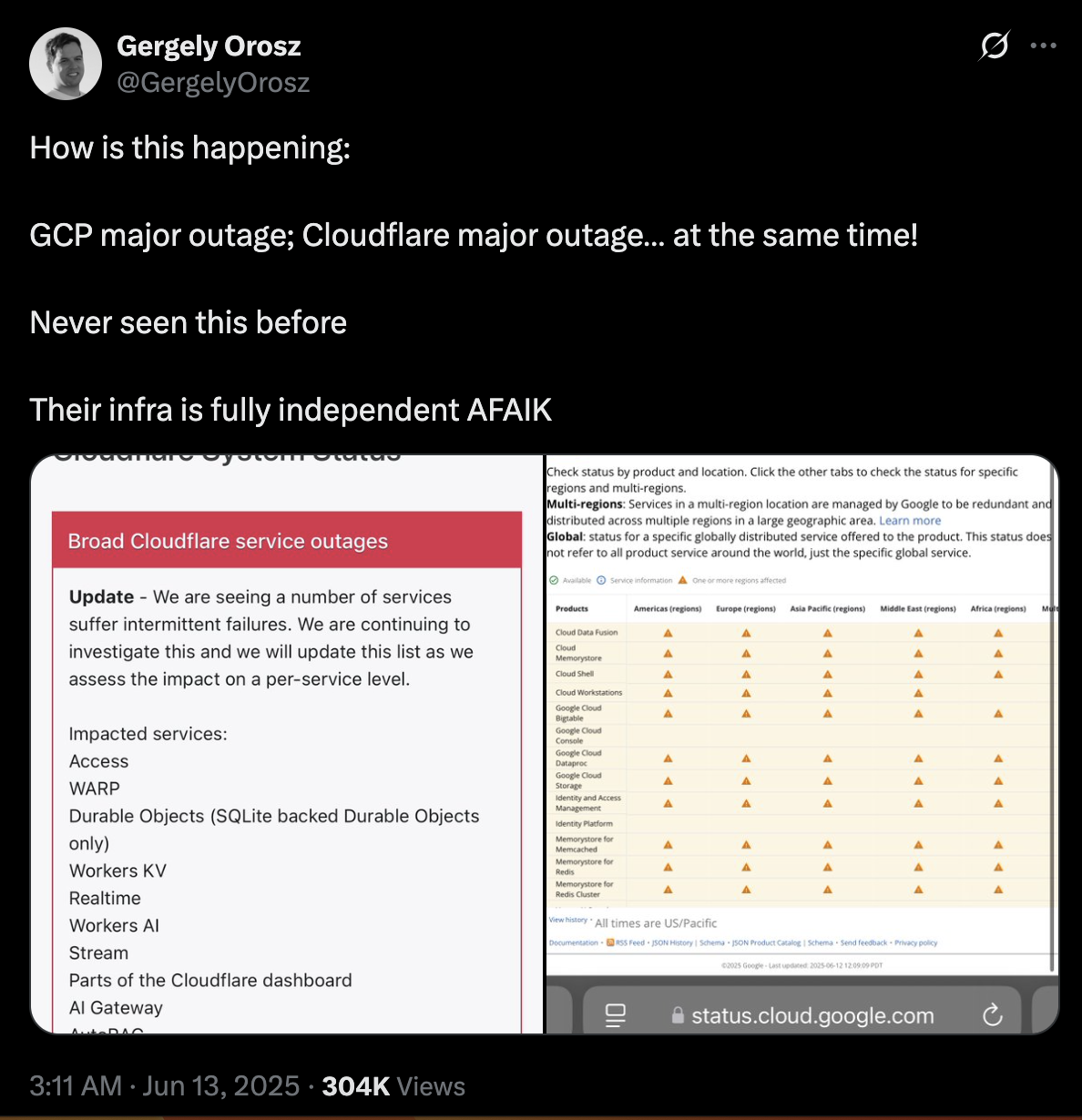
在 X 上,Uber 前员工 Gergely 在谷歌宕机的两天就发现了不正常,他发现多个平台和服务出现了不同程度的服务中断。
“ChatGPT/OpenAI 宕机 3 小时;Heroku 宕机 4 小时(连状态页面都宕机了!);NVIDIA 开发文档也宕机了(运行在 Heroku 上);Pipedrive (CRM) 问题 4 小时;还有什么宕机了……这些有什么关联吗?4 小时前就出事了……”
在 GCP 和 Cloudflare 同时宕机后他也表示不可思议。
“Cloudflare 真是令人惊讶。他们从来没出过宕机事故:整个基础设施都设计得非常有弹性,而且 DDoS 攻击也能轻松应对。但现在 GCP 严重宕机和 Cloudflare 严重宕机同时发生!之前从未见过这种情况。据我所知,他们的基础设施完全独立。”
对于谷歌此次中断造成其他公司服务瘫痪一事,《The Register》认为,这是由多米诺骨牌效应引发的:谷歌服务中断,Cloudflare 也随之瘫痪,最终 Cloudflare 的客户也陷入困境。
此外,除了对谷歌云宕机的原因和带来的影响的讨论外,还有用户表示,如果不是此次谷歌和 Cloudflare 同时宕机,人们怎么会想到,Cloudflare 对谷歌云的依赖会这样大。
“这确实非常令人惊讶,许多与大型云提供商竞争的 CF 产品,竟然如此依赖 GCP。”
也有用户表示,这种情况其实也正常,底层基础设施供应商们之间都是相互依赖的。
“全球约有 20-25 家核心 IaaS 提供商,它们之间很可能存在某种程度的相互依存关系。从 Cloudflare 的立场来看,他们显然将此视为行业常态。而本次事件的事后分析,正是为了验证和确保这种依赖关系的可控性。”
还有人对这种大型云厂商之间的相互依赖表示担忧:
“有一天,Cloudflare 将依赖于 GCP,GCP 将依赖于 Cloudflare,AWS 将依赖于两者之一的在线状态,而 Cloudflare 也将依赖于 AWS,互联网将崩溃,没有人知道如何重新启动它。”
在 Hacker New 评论区还出现了一条有意思的网友调侃,“这时候真的太需要人工智能出场了”!
2025 年 6 月 12 日发生宕机前 be like:“AI,有没有搞错?噗!AI 一整个就是个幻觉中心,它们永远取代不了我!”
2025 年 6 月 12 日发生宕机后 be like:“你说啥,不能靠 AI 啦?你真当我们是牛马啊!”

又是降本增效来“背锅”?
由托马斯·库里安 (Thomas Kurian) 领导的云计算部门近年来一直是谷歌增长最快的部门之一,并受益于市场对人工智能产品和服务的需求。
但此次宕机事件对谷歌来说是一个不小的挫折,该公司正试图在云基础设施领域与规模更大的竞争对手亚马逊网络服务 (AWS) 和微软 Azure 保持同步。
谷歌的状态页面显示,此次事件已导致其在美国、欧洲和亚洲的 13 个云服务出现问题。其他似乎遭遇中断的网络服务包括 AWS 的 Twitch,CoreWeave 的 Weights & Biases、Elastic、GitLab、LangChain,微软的 GitHub、Replit 和 Intuit 的 Mailchimp。
据 CNBC 二月份报道, Alphabet 一直在大幅削减开支,对销售、客户体验、内部交易和市场推广团队进行裁员。
上周,有消息称,谷歌已向其美国多个部门的员工推出自愿离职计划。
这引发了人们对其是否会为了削减成本而进一步裁员的担忧。据 CNBC 报道,这项“自愿离职计划”面向多个关键领域的员工,包括知识与信息(K&I)、中央工程、市场营销、研究和传播。据报道,拥有约 2 万名员工的 K&I 团队于去年 10 月进行了重组,之后谷歌高管尼克·福克斯接任该团队负责人。
据知情人士和 CNBC 看到的内部信件称,一些受影响员工的职位将被转移到印度和墨西哥城。
该公司确认,这些调整包括在美国其他地区和海外整合或开放职位。该公司补充说,云计算部门最大的员工队伍仍然在美国,这一点不会改变。
裁员人数尚不清楚,但该公司表示裁员人数很少,并且该公司将继续招聘关键的销售和工程职位。
参考链接:
https://status.cloud.google.com/incidents/ow5i3PPK96RduMcb1SsW#2c2sBHWU84yPDJ8y1ar4
https://www.tomsguide.com/news/live/spotify-down-live-updates-6-12-outage
https://news.ycombinator.com/item?id=44260810
https://www.cnbc.com/2025/06/12/google-cloud-and-other-internet-services-are-reporting-outages.html




