
你可能想不到,企业每年在云上花掉千万、上亿元预算里,有相当一部分其实都在打水漂。
因为云计算服务器里的内存,被大规模、系统性地浪费掉了。
值得注意的是,在云服务器里,内存几乎决定了一台机器能跑多快、撑多久、能养多少“租客”(应用、微服务、Pod 等),是影响业务性能、稳定性和成本的关键资源。
也就是说,现在有个普遍的问题:企业付出了高昂的内存成本,但其中大量资源却处于长期闲置状态。
Cast AI 发布的 2025 Kubernetes 成本基准报告显示,云资源利用率依然偏低,其中平均内存利用率仅为 23%。

与此同时,用户对内存的请求量,普遍比实际分配量高 40%–65%,造成了 “高预留、低使用” 现象——企业在为从未真正用上的内存持续付费。
而腾讯云服务器操作系统 TencentOS Server 中,有一个堪称 “服务器省内存神器” 的重要内核能力:悟净,一个面向云原生场景的多级内存卸载体系,有效提升企业的内存利用效率。
具体而言,TencentOS Server 是腾讯云打造的 Linux 服务器操作系统,也就是一套专门给服务器跑的“电脑系统”,TencentOS Server V4(以下简称 TS4) 是它的最新一代版本。
随着 TS4 的发布,悟净迎来了一次“大升级”:它不再只是一组分散的内核优化,而是演化为一套完整的多级内存卸载体系——包含 UMRD 主动回收、MGLRU 热度识别、重构后的 SWAP、Cgroup 级 ZRAM 隔离、多级设备卸载等一整套机制。
如果说之前的悟净像是一系列“内存优化能力”,那么 TS4 上的悟净已经成长为一个 “智能内存管理引擎”:
引入 UMRD(主动回收守护进程);
全面采用并优化 MGLRU,热度识别更精准;
重构 SWAP 分配器(进入 Linux 6.14 主线),性能提升 400%;
首次实现 per-cgroup 级 ZRAM 隔离(容器友好);
支持 多级卸载路径(压缩 → SSD → CXL)。
效果提升也非常直观:不仅能进一步显著节省内存,整机节省率最高可达到 88%;在真实业务中,转码场景的 OOM(内存溢出)次数下降了 86%,Serverless 节点因内存紧张导致的 nodelost 事件也减少了 90%。
一、云时代的内存难题 & 悟净给出的巧解
要真正弄懂悟净的价值,我们得先来具体看看它的诞生背景、以及它要解决什么问题。
1、云时代,Linux 内存管理为什么逐渐“跟不上节奏”?
这里再简单回顾一下:悟净,是 TS4 系统中的一个面向云原生场景的多级内存卸载体系;而 TS4,是一套基 Linux 内核研发的服务器操作系统。
其实问题的关键不在于“是不是 Linux”,而在于:云,已经彻底改变了“内存”的角色。
在传统单机时代,内存主要关注 “够不够用”, 只要程序不 OOM、机器不抖,内存多一点少一点的影响并不致命。
但在云时代,内存变成了一种持续计费、决定实例规格、直接影响节点数量的核心成本资源——而且规模一放大,浪费就会被成百上千倍地放大。
举个直观的例子:在 Kubernetes(可以理解成一个“云上调度和管家系统”)里,为了保险起见,一个 Pod(Kubernetes 里运行应用的最小单位)可能会多报几 GB 的内存 request,这看起来问题不大;但当成千上万个 Pod 同时这么“往大了报数”时,结果往往是:
节点装不下,被迫多开机器;
实际用不满,却要为整块内存长期付费;
成本上去了,利用率却没上来。
用一句来说,云时代的内存不再只是性能资源,而是一项需要被精细经营的“成本与容量资产”。
而 Linux 默认的内存管理思路,仍然更像一个单机自救系统:假设机器是“独占的”;假设内存层级简单;假设压力是偶发的、短时的。
但这套假设,在云原生、多租户、容器密集部署的现实面前,开始频繁失效。
具体来说,Linux 内存管理长期存在的五个结构性矛盾,在云环境里被全面放大了:
回收逻辑偏被动:内存平时“睁一只眼闭一只眼”,压力真正上来时才紧急回收,结果就是高峰期抖动、长尾延迟明显;
冷热判断过于粗糙:传统 LRU 只能大致区分“最近用过”和“没那么常用”,很容易在压力下误伤真正的热数据,引发卡顿;
Swap 机制历史包袱重:设计初衷并非面向高并发、大内存、云服务器场景,容易碎片化、效率低,在现代负载下越来越“吃力”;
ZRAM 只有压缩,没有隔离:容器之间共用压缩池,谁先用、谁多用,很难说清楚,多租户环境下容易相互干扰;
缺乏真正的多级分层能力:数据该放内存、压缩内存、SSD 还是新型内存设备,系统缺乏统一、智能的调度逻辑,只能“要么全留、要么全扔”。
这些问题叠加在一起,最终演化成大家在云上最熟悉的几种“症状”:内存利用率长期偏低、延迟抖动频发、资源被浪费,而 OOM 却依然随时可能发生。
2、TS4 悟净:不是单点优化,而是做了一套内存管理组合方案
也正是在这样的背景下,TS4 的悟净并不是去修补 Linux 内存管理里的某一点,而是 重新梳理了一整条内存管理链路。
从“什么时候该回收、回收多少”,到“回收哪些页、往哪儿放”,再到“多租户之间如何互不干扰”......
悟净,正在努力尝试把内存从“被动应急资源”,重新拉回到“可预测、可调度、可运营的系统能力”。
它主要由五大核心部分构成:
UMRD 用户态智能大脑: 结合 PSI 和 Cgroup 指标预判压力,提前回收,告别被动清理;
MGLRU 多代冷热判断: 用更细的分层方式识别访问频率,精准挑出冷数据,减少误回收;
重构 Swap 系统: 换上轻量索引,支持大页,提升 IO 能力,让 Swap 变回可用扩展内存;
per-cgroup ZRAM: 把压缩池按容器隔离开来,谁用多少一清二楚,不再互相抢;
透明多级卸载: 根据数据冷热自动安排去向:CXL、ZRAM、SSD 各司其职,性能和空间兼得。
这套组合拳,让 Linux 的内存管理具备了主动判断、精准回收、按层存放、隔离可控的能力。
在实际业务上,效果也非常直接:同样的内存能撑起更大的业务规模,资源利用率明显提升;高峰期的抖动更少,OOM 事件显著减少。
另外,容器之间的边界清晰了,多租户场景更可控;同时也为 CXL、ZRAM、SSD 等新技术的叠加利用打下基础,高密度部署与成本优化更有空间。
总而言之,悟净解决的并不仅仅是“省了多少内存”,而是让内存真正成为云时代可以被精细调度和运营的系统资源。
二、TS4 悟净 :五项突破,重塑内存管理
前文提到 TS4 中的悟净有五大重要升级,下面来具体看看。
1、主动式回收能力:引入 UMRD(核心升级),解决回收时机与回收量问题
内存回收本身并不可怕,真正麻烦的是,回收“来早了”伤性能,回收“来晚了”就可能 OOM。
在 Linux 默认机制中,内存回收主要依赖水位线触发。简单说就是:内存还“看起来够用”时,系统基本不动;一旦逼近临界点,才开始集中回收。
这种方式在单机时代尚且能用,但在云环境下问题会被明显放大,因为多租户、容器混部、高峰叠加,压力往往不是“突然一下”,而是逐步积累、局部爆发。
等到水位线真正触发时,回收动作往往已经来不及,只能“猛刹车”,带来延迟抖动,甚至直接触发 OOM。
UMRD 的引入,正是为了解决这一层问题:把“是否该回收、该回收多少”这件事,从被动触发,变成可提前判断、可持续调节的过程。
具体来说,UMRD 是一个运行在用户态的内存回收守护进程,它并不直接替内核“动手清内存”,而是持续观察系统和各个业务的状态,帮助内核做更合理的回收决策。
它重点关注两类信息:
一类是 PSI(内存压力信号):这是一种用来统计“应用因为等内存而被卡住了多久”的指标。如果系统开始频繁出现“明明有任务要跑,却在等内存”的情况,就说明压力已经在累积,这是应该提前介入回收的信号;
另一类是 Workingset(工作集)相关信息:简单来说,就是“哪些内存页是真的在被反复使用”。UMRD 会结合每个 Cgroup 的工作集大小和页面类型分布,估算在不明显影响业务的前提下,最多能回收多少冷内存。
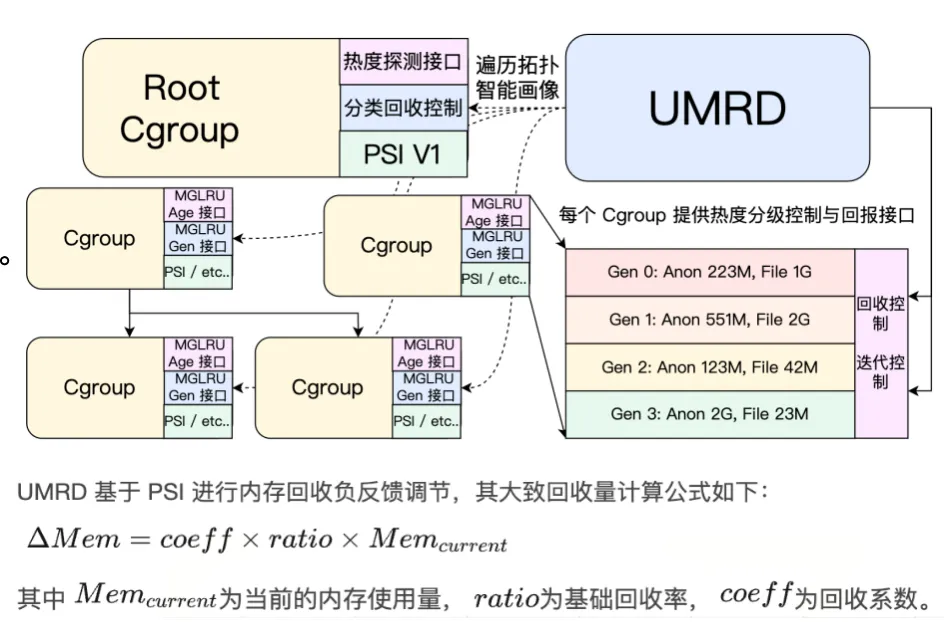
基于这些信息,UMRD 会采用一种负反馈式的回收策略:当压力较轻时,回收动作温和、分散;当压力逐步上升时,回收力度也随之调整;如果回收开始影响业务,策略可以及时放缓甚至暂停。
整个过程不是“一次性清空”,而是边观察、边调整、边回收,尽量把内存压力化解在“业务还能感知之前”。
另一个关键点在于,UMRD 是纯用户态设计。 这使得回收策略、参数调整和场景适配不必频繁改动内核本身,更容易针对不同业务形态、不同部署环境做差异化配置,也更方便和云平台、调度系统进行联动。
从效果上看,引入 UMRD 后,内存回收不再只是“临界时刻的自救手段”,而是变成了一种可以提前介入、节奏可控的常态化系统能力。
这也为后续更精细的冷热识别、多级卸载以及容器级隔离,打下了一个稳定的基础。
2、冷内存识别精度提升:完整适配并优化 MGLRU
“回不回收”只是第一步,“回收谁”才真正决定性能表现。
传统 LRU 只能粗略地区分活跃页与非活跃页,在云原生和容器密集场景下,很容易误回收仍有访问价值的页面,造成频繁换入、延迟上升。
悟净在 TS4 中完整适配并深度优化了 MGLRU(Multi-Gen LRU)机制。
MGLRU 会基于页面访问历史,把内存页划分为多个“世代”,从而形成更细粒度的冷热分层,使系统能够更准确地识别长期未被访问的冷内存,优先回收真正“沉睡”的页面。
业界调研和腾讯云内部实践均发现,应用为了性能普遍采用内存密集策略,匿名页与文件缓存页中都存在不少的冷内存,而 MGLRU 正是更高效识别这部分内存的关键基础能力。
3、完全重写 Swap 分配器:为大内存与多级卸载打基础
在云环境中,Swap 不再只是“兜底机制”,而是内存扩展和成本优化的重要组成部分。但 Linux 旧有的 Swap 分配逻辑,在大内存、高并发场景下容易出现碎片化、效率下降等问题。
悟净对 Swap 分配器进行了系统性重构。
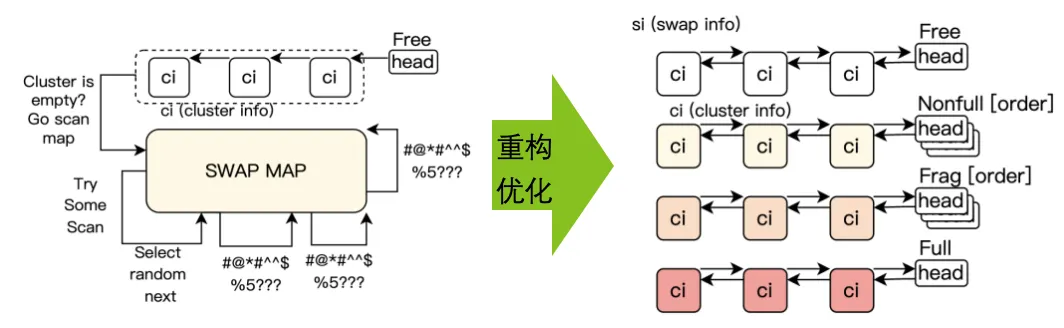
重点包括:
重写分配路径,SWAP 设备并发吞吐量提高 400%;
更好地支持大页和多设备场景,为 ZRAM、SSD 等多级卸载提供基础;
引入 Swap Table,压缩和整合冗余元数据,降低 Swap 本身对内存的额外消耗。
这些改动,使 Swap 在现代服务器和云负载下,能够更稳定地承担“冷内存后备”的角色,而不再成为新的性能瓶颈。
4、实现 per-cgroup ZRAM:容器级压缩隔离,对云原生很关键
ZRAM(内存压缩)在云环境中具有很高的性价比,但原生实现下,多个容器往往共享同一个压缩池,容易出现“相互挤占”的问题。
悟净在 TS4 中引入 per-cgroup ZRAM 能力,把压缩内存的使用边界明确到容器级别:每个 Cgroup 使用多少压缩内存都有清晰边界,避免某个负载过度使用压缩资源,影响其他业务。
腾讯云团队强调,容器场景对宿主机资源提出了更极致的利用要求,而 Cgroup 级别的内存隔离和可观测性,是云原生场景下 OS 能力的重要组成部分。
5、多级卸载能力(ZRAM → SSD → CXL),让内存真正“分层使用”
最后,TS4 的悟净并不假设“冷内存只有一个去处”。
在 TS4 中,悟净支持透明的多级内存卸载路径:根据数据冷热程度和设备性能差异,内存页可以被逐级卸载到 ZRAM、SSD,甚至 CXL 等新型内存 / 互联设备上。
这种分层方式的目标并不是简单“挤出内存”,而是在性能、容量与成本之间取得更优平衡——尽量把仍有访问价值的数据放在更快的层级,把真正冷的数据沉降到更便宜的介质,从而最大化整体设备利用率,同时控制性能损失。
腾讯云团队也提到,随着多级资源利用能力逐步成熟,操作系统在内存层级管理上的优势正在被进一步释放。
三、实战效果:OOM 显著下降,稳定性大幅提升
技术升级最终要看实际落地效果。TS4 版悟净在腾讯百万级服务器的实测数据,在内存节省、系统稳定性、混部能力 上都有精彩表现。
先看一个最直观的数字:悟净让腾讯整体节省了 33% 的内存。
目前,悟净已覆盖腾讯 200+ 万台服务器,管理着超过 3500+ 万核 CPU ,超 20PB 的“内存海”。然后,在业务完全不停机的前提下,悟净硬是从这 20PB+ 里挤出 7PB+。
这省出的 7PB+ 内存什么概念?相当于 32 万台 64GB 服务器的整机内存,如果换算成成本,大约是 8.4 亿人民币,足以抵得上一个数据中心的规模。
更关键的是,这 7PB+ 节省里,有 3.5PB+ 并不是从那些相对容易回收的缓存里“抠”出来的,而是来自业界公认最难下手的区域 “匿名页内存”。
操作系统的内存主要分为两类:一类是有 “备份” 的文件页,属于 “好动、好收拾” 的内存;另一类就是匿名页,它没有备份,存放的是程序正在运行的关键数据,不能删、不能乱压、不能乱动,一旦操作失误,程序会直接崩溃。因此,匿名页长期被视为内存管理的 “禁区”。
但悟净偏偏就在这里挤出了 3.5PB+。节省目标达成度达到 193%,远超预期。
而支撑这份成果的核心,是悟净重构的 “超卖” 能力:从底层技术到平台落地,再到最严苛场景验证,形成了一套让 “一台机器跑更多业务” 的完整闭环。
所谓 “超卖”,本质是让服务器 “看起来比实际更大”,用相同硬件承载更多业务 。这是云平台降本增效的核心抓手,但行业长期困于 “不敢超、超不稳”。悟净用三层逻辑打通了这一堵墙。
第一层是底层超卖能力:悟净的底层能力核心在于一套“找得到、卸得安、用得好”的内存收纳术,像一位专业的“智能整理师”。
它通过 PSI、Working Set 与 MGLRU 三套感知机制协同判断真正的冷数据,然后分级卸载:稍冷的压入 ZRAM、更冷的放到 SSD、几乎不用的归档到更低层级存储。配合虚拟视图机制,业务看到的仍是一整块连续内存,但底层实际早已完成“瘦身”。
这为上层调度层提供了最关键的前提:可用空间不仅大,而且稳。
第二层是平台级云超卖:悟净并非只停留在底层优化,它进一步把腾出的空间真正“用起来”。
悟净的智能调度模块 Crane 正是在做这件事。它会实时分析节点的负载、压缩空间和业务优先级,把腾出的空间分配给更适合的服务。
相比原生内存系统 K8s“有空位就塞”的调度方式,Crane 会先判断哪些服务适合“合租”,再划好负载红线,让一台机器既能多跑业务,又能稳住不乱。
在实际大规模混部场景中,这带来了非常直观的提升,单节点能稳定容纳 4 个 Pod,装箱率从原本的 1:3 变成 1:4,等于白赚出 33% 的空间,一台服务器能顶过去 1.3 台的用量。
这套能力,也是悟净核心的混部能力的体现,解决了行业长期“不敢混”、“混了就乱”的痛点。
第三层是 Redis 超卖的终极验证:如果说云超卖是 “常规考试”,而“Redis 超卖”则是这一能力在最严苛业务上的一次实战检验。Redis 对内存延迟和稳定性极其敏感,过去几乎被视为“不可超卖区”,一旦出问题就是事故。
但悟净通过精准的冷数据管理,不仅为 Redis 节省 30%+ 内存,还能让高峰期延迟更稳了。这意味着悟净的安全超卖能力已经经受住了最苛刻场景的验证。
如果说超卖是 “让一台机器跑更多”,降配就是 “让业务用更少机器跑”,两者共同指向一个核心:帮企业省大钱。
过去业务需要 8GB 内存才能安心运行,现在用 4G 内存加悟净的 “内存收纳术”,就能装下同样多的数据,用着一样流畅,硬件成本直接砍半。
还有更多实战数据:
转码业务:内存规格从 30C30G 砍到 30C15G,硬件成本直省 50%;同时 OOM 降低 86%,转码效率完全不受影响;
图片存储业务:即使流量暴涨 270%,仍能省 75.7% 内存,业务失败率下降了 92.8%,CPU 和磁盘读写完全没波动。
别人一降配就卡、不稳,悟净却能在降配的同时把成本降下来、稳定性还往上提。更能体现技术分量的,是它在最容易翻车的 Serverless 场景里依然稳得住。
技术的价值,最终要落到 “业务不崩” 上。悟净不仅能省成本、提效率,还直接攻克了 Serverless 场景的行业痛点 “NodeLost”,即服务器突然 “掉线罢工”。
Serverless 是扩得快,但崩得也快。尤其是内存瞬间被打满的时候,节点会直接失联,引发级联调度和大面积业务失败。这是长期困扰行业的顽疾,过去很难根治。
而悟净的提前卸载机制,让节点在压力到来前就 “轻装上阵”,从源头避免内存爆点。最终,腾讯 TKE Serverless 的 NodeLost 从日均 12000 + 次降至 3000 次以内,降幅达 90%。这波下来,Serverless 最大的隐患被拔掉了。
技术影响力上,悟净的核心研发者拿下 Linux Kernel SWAP 子模块 Maintainer 权限,意味着腾讯在内存管理的内核级技术上拥有了话语权,成为行业标准的参与者和制定者。
说到底,悟净不是优化,是重做内存管理的一次机会。不是工具,而是一套让企业,省钱、省心、跑得更稳的增长引擎。
百万台服务器的验证说明,悟净这套体系不仅能顶住业务压力,还能把资源真正用满。企业不再被内存瓶颈牵着走,利用率上来了,成本降下去了,业务规模也更容易向前推。
这正是技术落地的终极意义 。
参考链接:
https://www.tencentcloud.com/zh/document/product/213/40223
https://cloud.tencent.com.cn/developer/article/2365144
https://cloud.tencent.com.cn/developer/article/2294351?policyId=1004




