
Discord 详细介绍了他们如何在单 GPU 训练达到极限后,重建其机器学习平台。通过在 Ray 和 Kubernetes 上实现标准化、引入一条命令即可操作的集群 CLI,以及使用 Dagster 和 KubeRay 自动化工作流,公司将分布式训练变成了一项日常操作。这些改进让大型模型能够实现每日重训,并带来了关键广告排序指标 200% 的提升。
随着企业自研模型在规模和更新频率上不断增长,Uber、Pinterest、Spotify 等公司也开始发布类似的工程报告。这些报告都描述了从手动、由团队自管的 GPU 设置,向共享、可编程的平台迁移的过程,这些平台强调一致性、可观测性和更快的迭代速度。
Discord 的转变从团队各自按照开源示例创建 Ray 集群开始,他们为每个工作负载手动修改 YAML 文件。这导致了配置漂移、所有权不清晰以及 GPU 使用不一致。平台团队的目标是通过标准化集群创建和管理方式,使分布式机器学习变得可预测。
最终的平台以 Ray 和 Kubernetes 为核心,但其关键在于其上层抽象。通过一个 CLI,工程师只需指定高层参数即可请求集群,该工具会基于经过审查的模板生成运行 Ray 所需的 Kubernetes 资源。这消除了团队理解底层集群配置的需求,同时确保调度、安全和资源策略一致地应用。
训练工作流被整合到 Dagster 中,Dagster 与 KubeRay 交互,在流水线中创建和销毁 Ray 集群。过去需要手动设置的任务现在都通过统一的编排层来运行,集群生命周期也由系统自动管理。
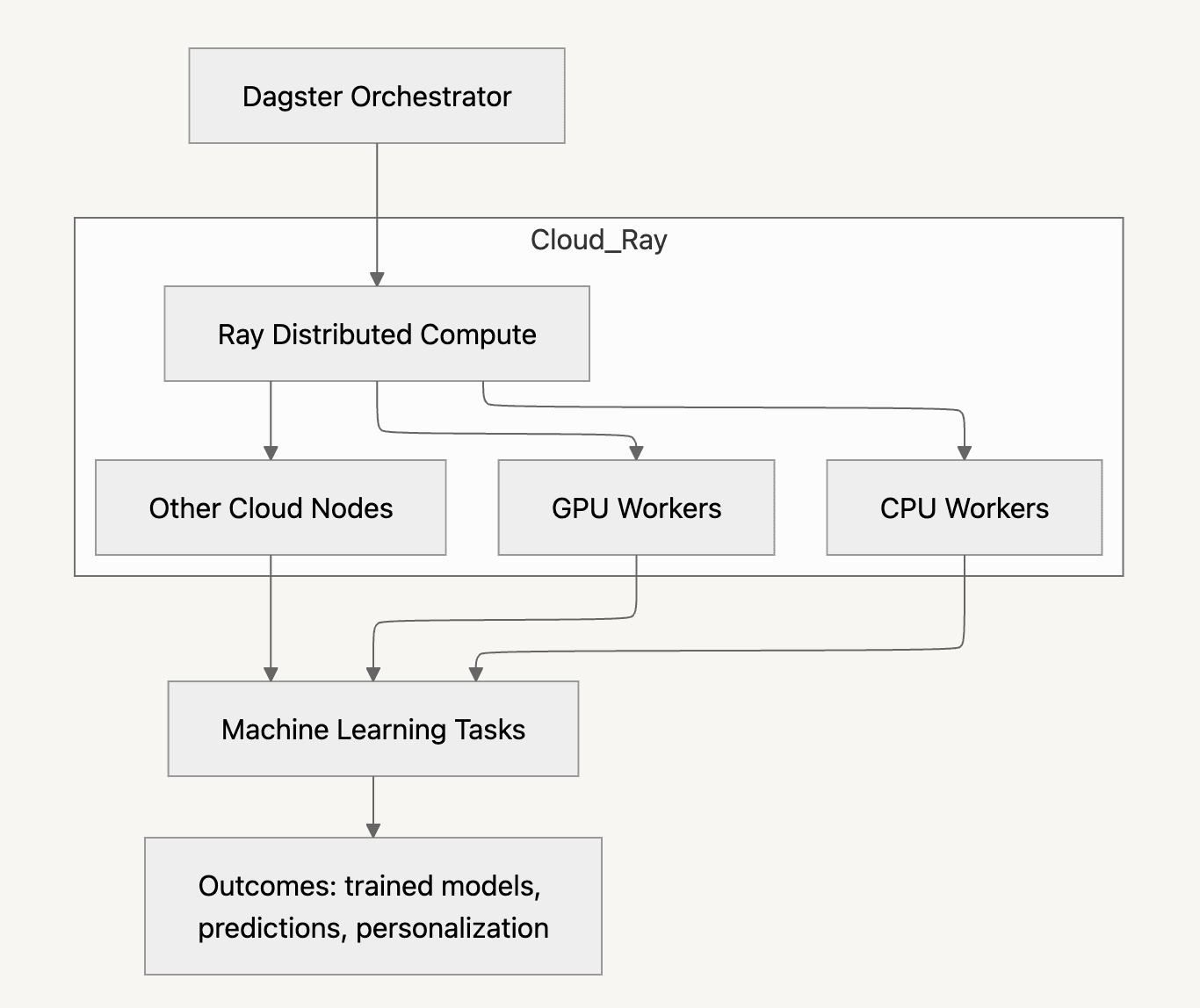
Discord 还构建了名为 X-Ray 的 UI,用于展示活跃集群、作业日志和资源使用情况。这些组件使分布式训练不再是一次性、特制化的搭建流程,而成为可预测的工作流。
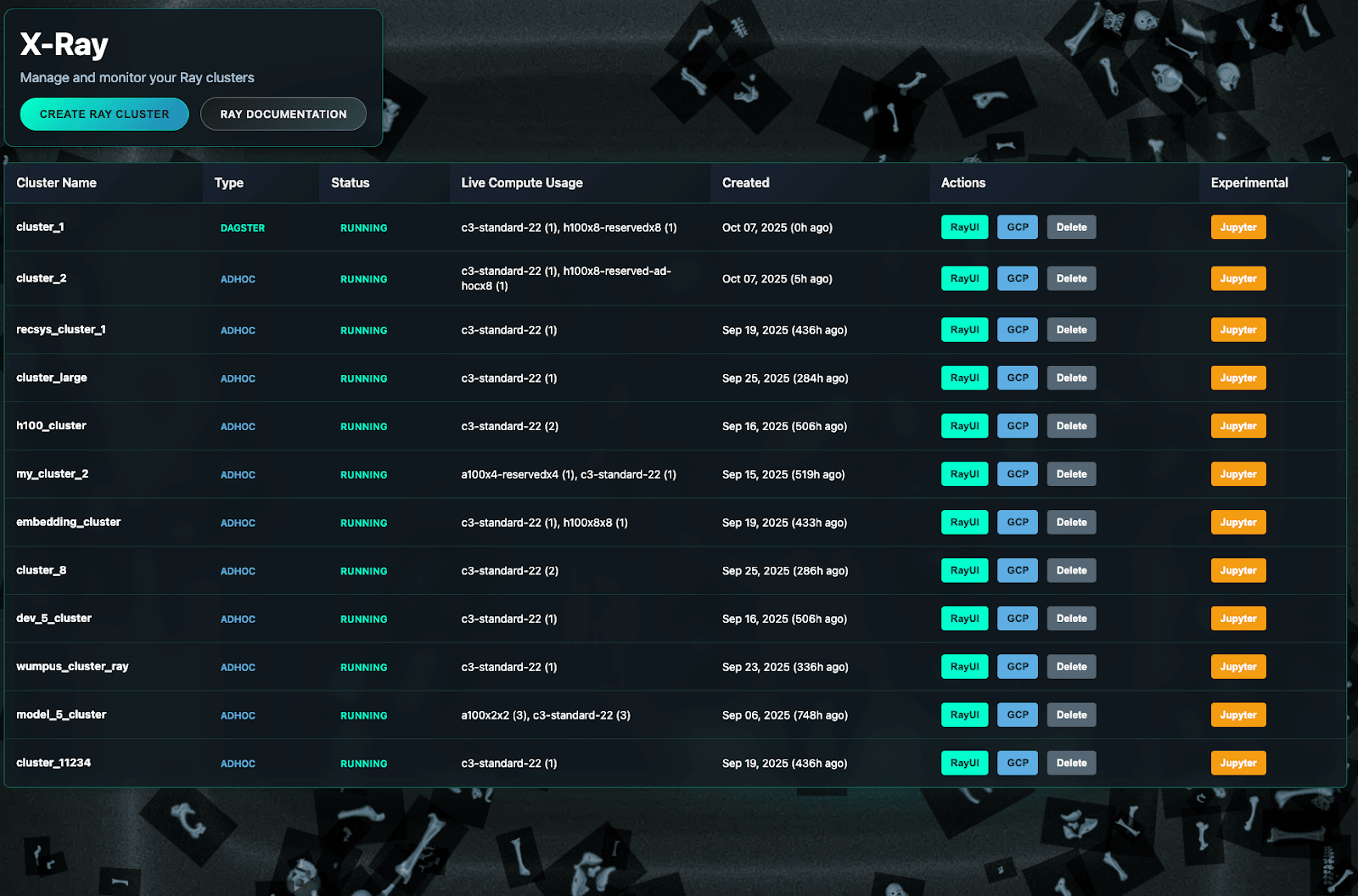
据 Discord 介绍,该平台使大型模型能够进行每日训练,也让工程师更容易采用分布式技术。各团队能够引入新的训练框架,而无需平台团队的直接参与。这些改进带来了可衡量的产品收益,包括更好的广告相关性。
也有其他组织描述了类似的转型。Uber 将 Michelangelo 平台的部分组件迁移到基于 Kubernetes 的 Ray 上,报告了更高的吞吐量和 GPU 利用率。Pinterest 构建了一个管理集群生命周期并集中日志和指标的 Ray 控制平面,减少了机器学习工程师的运维负担。Spotify 创建了一个基于 GKE 的“Spotify-Ray”环境,用户可以通过 CLI 或 SDK 启动 Ray 集群,从而统一实验和生产工作流。
不过,也有关于内部机器学习平台局限性的警示案例。今年早些时候,CloudKitchens 的一篇文章指出,其第一代基于 Kubernetes 的系统变得过于复杂,简单的 ML 作业启动时间超过十分钟,而基于 Bazel 的工作流也给 Python 用户带来了持续的维护负担。
总体来看,这些案例表明业界正逐步转向具有更清晰抽象和更可预测工作流的共享机器学习平台。平台可以加速迭代,并提供更可靠的分布式计算资源,但也可能带来架构和维护方面的权衡。
原文链接:




