
PagerDuty是一个事件管理平台,被成千上万的组织用来提醒他们系统上的问题,它在 2025 年 8 月 28 日遭遇了一次重大的服务中断。在一份全面的服务中断报告中,该公司详细说明了问题的范围、对客户的影响,以及如何防止故障再次发生。
这次事件中断或延迟了对 PagerDuty 美国服务区域客户接收传入事件的处理。严重的服务降级影响了 PagerDuty 超过 9 个小时。在高峰期,大约 95%的事件在 38 分钟内被拒绝,18%的创建请求在 130 分钟内产生了错误。
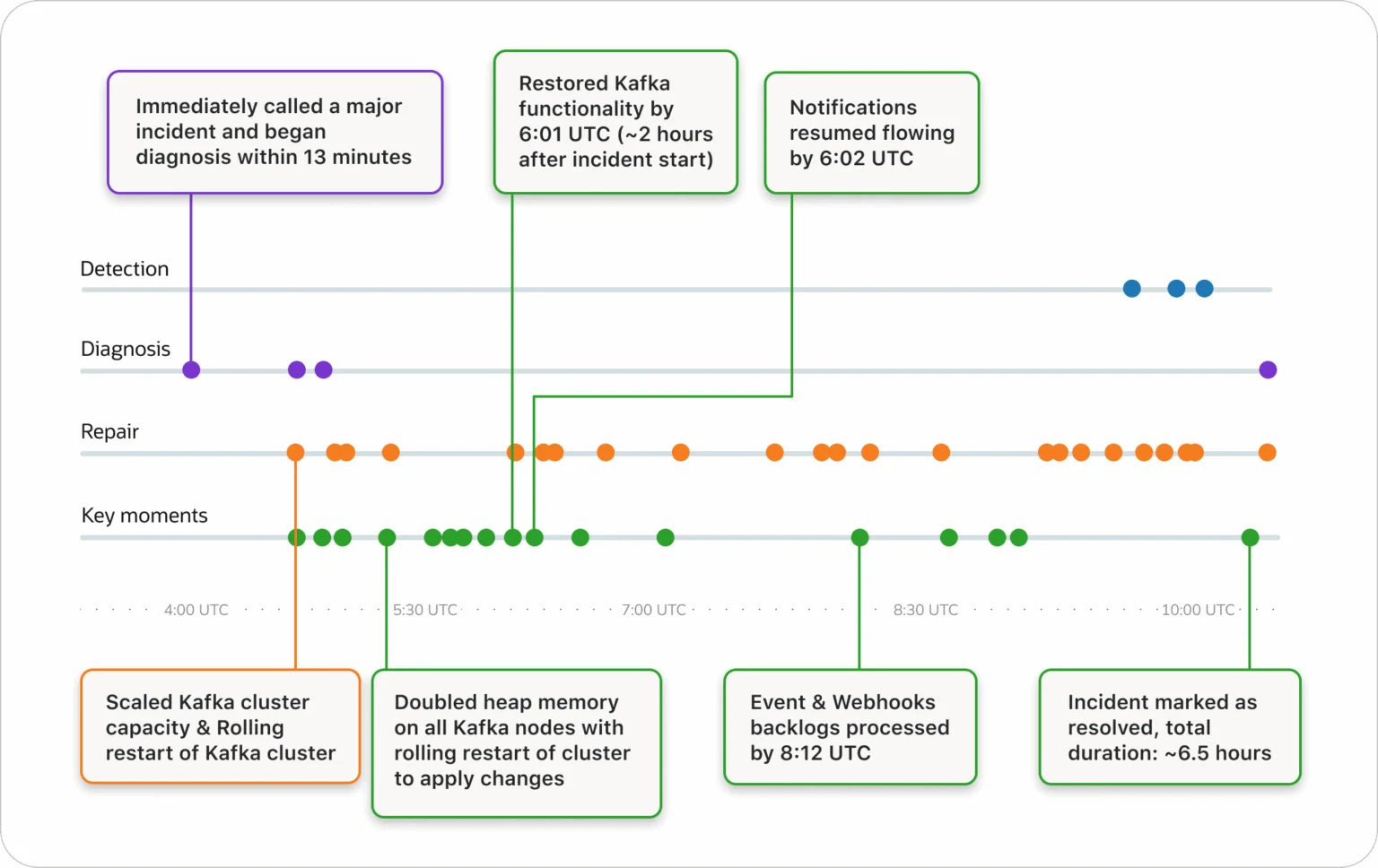
根据服务中断报告,原因是在推出一项新功能时出现了一个缺陷,该功能旨在改善 API 和密钥使用的审计和日志记录。随着增量推出进程的进行,PagerDuty 的 Kafka 集群的使用量错误地超过了系统的容量。
由于上述功能的逻辑错误,每个 API 请求都实例化了一个新的 Kafka 生产者,而不是使用单个 Kafka 生产者来产生消息。
报告解释说,PagerDuty 对如何使用pekko-connectors-kafka Scala库的解释导致了这个编码错误。报告详细说明了额外负载的范围:“Kafka 最终在高峰时每小时追踪了近 420 万个额外的生产者,这比我们通常的新生产商数量高出 84 倍。”它继续解释了 Kafka 如何开始抖动,然后耗尽可用的 JVM 堆,导致集群的级联故障。
由于我们的许多系统都依赖于 Kafka,这种减速会蔓延开来,服务最终完全失去了与 Kafka 交互的能力。
这在依赖 Kafka 进行通信的其他服务中引起了连锁反应,因为它们无法连接到 Kafka 集群。这增加了服务中断的影响和恢复情况所需的时间。公司承认,“级联故障本质上很难预测,一个服务中的小问题可能会以系统图上不明显的方式波及到其他服务。”
更具有讽刺意味的是,这一事件影响了一个主要的事件管理平台,由于 PagerDuty 工作人员起草的更新没有出现在公共状态页面上,导致了外部沟通的延迟。进一步增加客户的混乱,因为这种“元故障”意味着他们无法在服务中断期间获得更新。
PagerDuty 并不是最近唯一遭受长时间停机的事件管理平台,Opsgenie 的客户在 2022 年就经历了14天的停机。
社区的反应显示了现代组织对可靠事件管理系统的重视,Reddit 上的一位用户解释了服务中断期间缺乏系统可见性造成的压力:“今天应该是工作的大日子。相反,我因为 PagerDuty 崩溃而被客户责骂……你有没有在值班时感觉自己就像瞎了一样?”用户 Vimda 随后建议为所有系统增加冗余:“总是有一个备用警报系统,即使是手动分类。”用户 Twirrim 对此表示赞同,他深思熟虑地认为监控工具本身也需要监控,并指出:“单点故障是可靠性的最大敌人。有时它们是不可避免的(例如,成本过高),所以你必须考虑‘如果出了问题怎么办’。”
除了详细的服务中断时间线和原因外,PagerDuty 还列出了一些未来的改进和承诺,以避免任何重复的情况,包括扩大他们自己的监控,特别是在 JVM 和 Kafka 层面,并实施更严格的变更管理护栏,以便工程师仍然可以快速工作,但增加了安全性。
社区的反应证实了所有组织都需要确保自己的系统和流程具有弹性,通过有意识地确保在第三方中断的情况下有冗余和备份计划。PagerDuty 自己的服务中断报告和未来的改进计划反映了一种强大且心理上安全的文化。
PagerDuty 的持续学习文化意味着我们从这样的事件中变得更强大——无论是在我们的技术还是我们的团队中。
原文链接:




