
一款“反直觉”的产品,往往最能折射一个产业的真实需求。
3 月 25 日,硅心科技(aiXcoder)发布了一款专为「代码变更应用」场景设计的高性能、轻量级模型 aiX-apply-4B。
基准测试结果显示,在 20 多种主流编程语言及 Markdown 等多类型文件格式的测试中,aiX-apply-4B 的平均准确率达到 93.8%,超越 Qwen3-4B 基座模型 62.6%的准确度,甚至高于千亿级大模型 DeepSeek-V3.2。同一任务场景下,aiX-apply 模型算力成本约为 DeepSeek-V3.2 的 5%,推理速度则提升 15 倍,仅需一张消费级显卡即可在企业部署。
同一代码变更应用任务场景下,对比 aiX-apply 模型与 DeepSeek-V3.2 推理速度
当全行业还在卷参数、卷通用能力时,这家北大系 AI Coding 赛道创企早已将目光投向了更深水区的问题——在企业研发算力有限的背景下,AI 到底该如何赋能智能化软件开发?
为什么是 4B 小模型?因为企业的算力“就这么多”
随着 OpenClaw 等智能体框架的普及,企业 AI 应用正从单次模型调用走向多智能体协作。一个复杂任务的完成往往需要 10 到 50 次模型调用,并发场景下的 Token 消耗更是达到传统模式的数倍甚至数十倍。
这一变化直接加剧了企业的算力压力。尤其对于金融、通信、能源、航天等关键领域企业来说,私有化部署的算力“就这么多”且极其宝贵——每一次额外的模型调用,都在消耗本就紧张的算力资源,推高延迟的同时挤占并发能力。当多智能体协作成为常态,如何控制算力成本成为企业面临的核心挑战之一。
公有云“烧”Token 的模式无法满足企业数据安全需求,私有化部署千亿级、万亿级大模型成本高昂且容易导致算力空转浪费。如何将有限算力实现最优配置,让每一份算力都能落到最需要的研发场景中去,是行业亟待解决的核心问题。
正是在这样的行业背景下,aiXcoder 推出更适合企业私有化部署的 aiX-apply-4B 轻量级模型,服务于代码变更应用场景。这一场景的核心挑战在于,需要将模型生成的不规整、碎片化的代码片段,精准、无损地应用到原始文件中,同时严格保持缩进、空白符、上下文的一致性,不牵动其他代码、避免引入新问题。
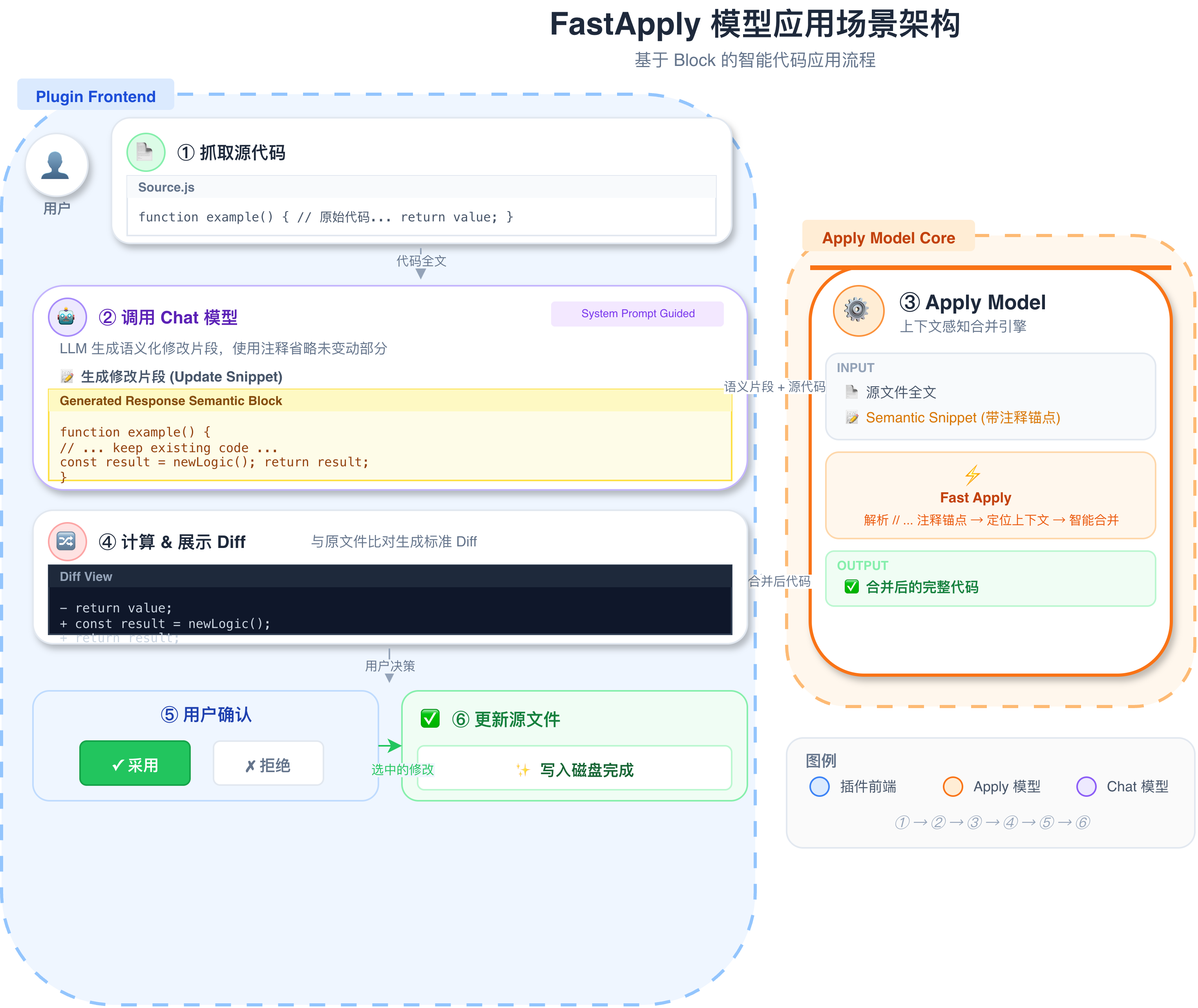
aiX-apply-4B 模型架构
据了解,为了贴合真实企业研发应用场景,确保模型应用效果,aiXcoder 结合真实企业场景下的代码提交记录构建了 aiX-apply-4B 模型的训练数据集,基于高性能强化学习框架开展模型训练,并纳入了对各种边界情况的考虑。
在统一的测试方法与多维度评估体系下,这个 4B 参数小模型凭借一系列的创新训练方法,在代码变更应用这一场景中实现了超越千亿级大模型的表现:
在准确率方面,测试结果显示,在覆盖 20 余种编程语言及文件类型的 1600 余条测试集上,aiX-apply 表现优于同量级模型 Qwen3-4B(准确率 62.6%),更与参数规模相差一百多倍的 DeepSeek-V3.2(准确率 92.5%)比肩。
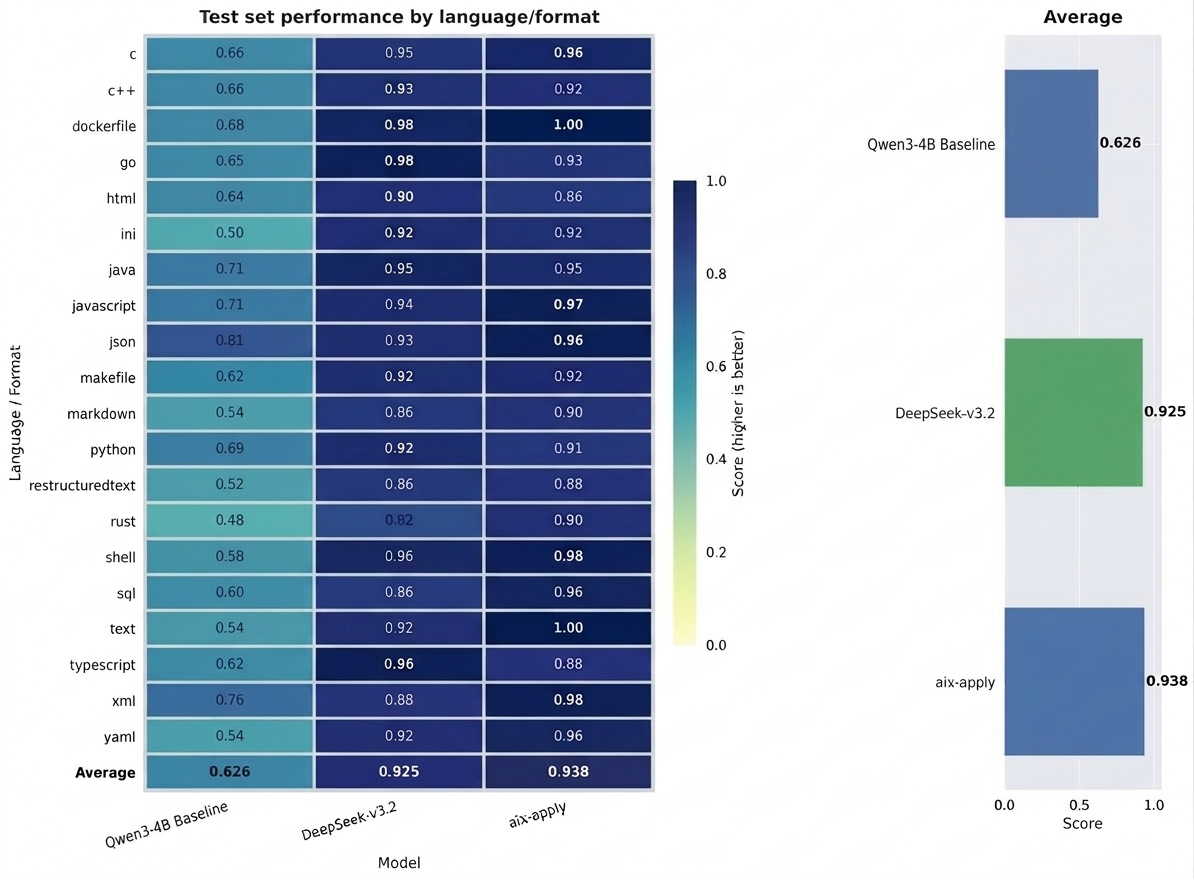
基准测试对比
在推理效率方面,aiXcoder 引入自适应投机采样技术,极大压缩了端到端延迟。企业级生产环境实测显示,aiX-apply-4B 推理速度每秒可达 2000 tokens,在单张 RTX 4090 消费级显卡上即可高效运行;而对比模型 DeepSeek-V3.2 则需要八卡 H200 高端集群部署。综合不同的硬件部署成本与推理速度综合对比,aiX-apply-4B 仅用 DeepSeek-V3.2 约 5%的算力成本,实现了 15 倍的效率提升。
在泛化能力方面,aiX-apply 模型展现出了媲美 DeepSeek V3.2 的准确性和稳定性。无论是面对超长代码文件的精确编辑,还是在训练数据中占比极低甚至未显式出现的编程语言场景下,aiX-apply 模型都保持了良好的范式泛化能力,充分验证了其在真实企业级开发环境中的实用价值。
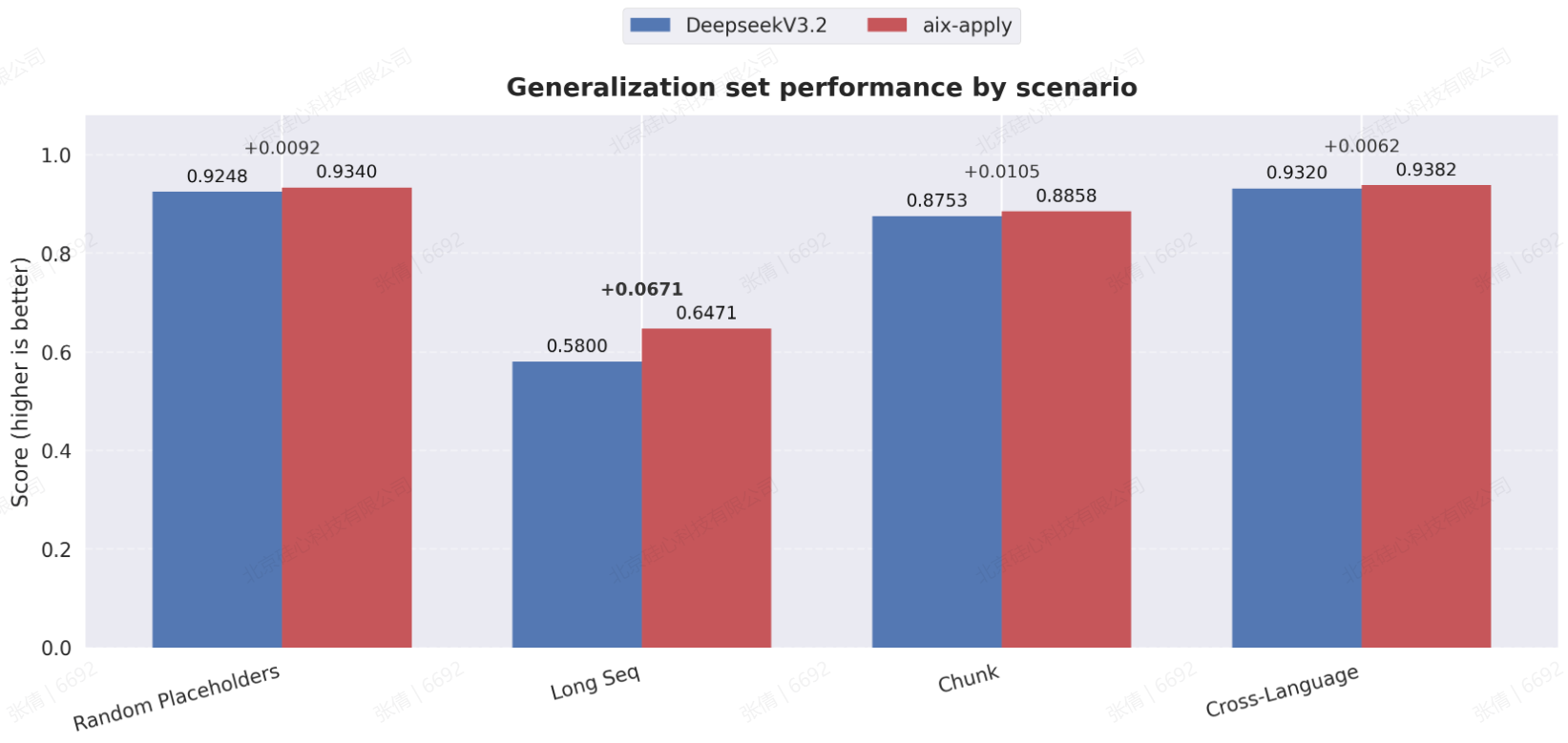
泛化性能力测试对比
“大模型+小模型”协同,最大化释放有限算力价值
事实上,aiX-apply-4B 模型并不是 aiXcoder 发布的针对研发场景定义的第一款小模型,早在 2024 年 aiXcoder 团队就已推出参数量为 7B 的代码补全小模型,能够精准预测开发者意图,专为开发者日常编码的高频场景设计。
据介绍,基于“场景定义模型”这一理念,aiXcoder 已构建起覆盖多个研发关键环节的小模型矩阵,并创新提出“大模型+小模型”协同架构,让“通才”大模型与“专才”小模型各司其职、优势互补:通用大模型聚焦复杂意图理解、代码逻辑分析、修改方案制定等需要深度推理的工作,发挥其智能优势;而垂直场景小模型则承接高频工程任务,以轻量化特性实现快速、精准执行。
这种架构设计可以让企业的有限算力得到分层利用:小模型支持专项场景任务的高效完成,节约出更多算力用于大模型的复杂推理。由此,避免了高端算力的浪费,充分释放企业有限算力价值。




