
神经网络正在推动最强大的人工智能系统,但我们仍无法真正“读懂”它们是如何得出答案的。“可解释性”,仍然是 AI 最大的黑箱。
昨天,OpenAI 开源了一种新模型 Circuit-Sparsity,参数只有 0.4B,99.9% 的权重为 0。这种极端稀疏的结构,让内部计算结构第一次呈现出一种接近“电路图”的清晰感,而不是传统 Transformer 那种密密麻麻、缠成一团的黑箱。对于可解释性研究来说,这是一个更容易“下手”的形态。
什么是可解释性?本质是试图回答一个简单问题:我们能不能看懂模型是怎么推理的。
目前主流的可解释性路线有两条,一条是链式思维,让模型自己“写下思维过程”,很好用,但模型随时可能瞎编。另一条是机理可解释性,从最底层的权重和神经元开始,一点点拆模型,试图逆向工程出它的内部算法。这条路很扎实,但面对 GPT-4 和 GPT-5 这种量级,就像从 DNA 推导整个人类行为,难度可想而知。
OpenAI 选择从另一个方向切入,既然难以拆解复杂的大模型,不如从源头入手,将其设计为“可拆解”的形态。Circuit-Sparsity 采用的是 GPT-2 风格架构,但在训练时做了一个关键调整——强行把绝大多数权重固定为 0,让模型“原生稀疏”。
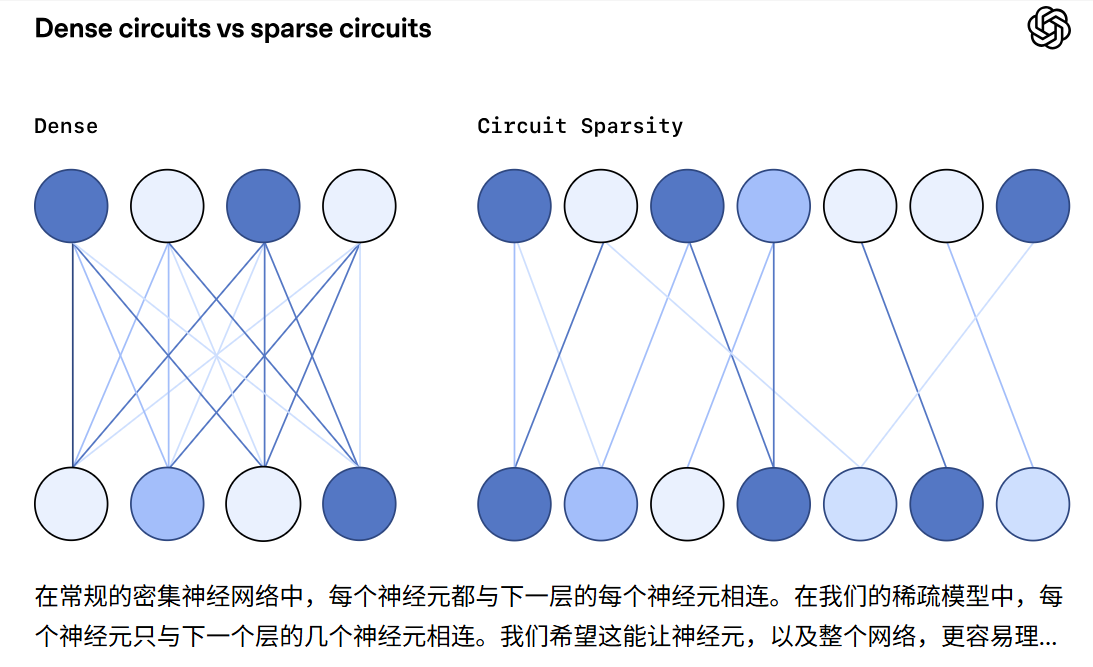
稠密模型中,一个神经元可能和成千上万个节点相连,但在这种极致稀疏的模型里,几乎所有连接都被砍掉,只留下最必要的那几条。神经元之间的关系因此变得简单、明确,像是一块块职能分明的小电路板。
为了看看这种结构是否真的更容易解释,研究团队设计了一些非常基础的测试,例如判断一个字符串该以单引号还是双引号结尾,推断 Python 变量的类型,或者判断一行代码是否应以冒号收尾。接着,研究人员用剪枝的方法,从模型中“挖出”完成这些任务的最小电路——只保留模型实际在用的节点和连接,把其他部分全部关闭,看模型是否还能完成任务。
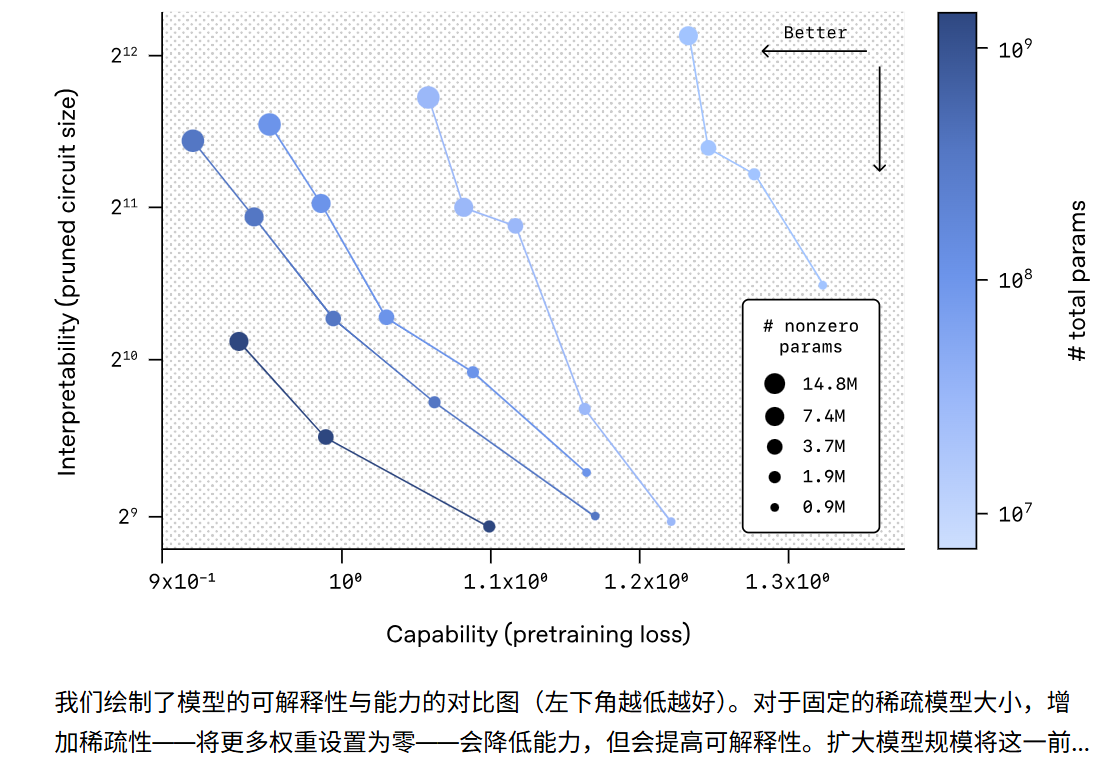
结果是干净得有些出乎意料:同样的任务,稀疏模型的电路只有稠密模型的 1/16 大小;关键节点少得可数,删掉任何一个模型就立刻失败;而在某些任务上,完整的推理流程甚至只依赖两个 MLP 神经元和一个注意力头,像手写算法一样直给。
研究者还注意到一个规律:稀疏度越高,电路越干净,可解释性越强;而增大模型规模,则可以在保持稀疏结构的前提下维持较高能力。这说明“大但稀疏”的模型可能是可解释性与性能之间更好的平衡点。
当然,稀疏 Transformer 目前并不能直接替代 GPT-4 或 GPT-5。论文非常坦率地指出,稀疏模型的训练和推理速度比稠密模型慢 100 到 1000 倍,因为现有 GPU、TPU 都是为密集矩阵设计的。再加上人工解读电路仍然非常耗时,这种模型短期内不可能成为前沿大模型的架构基础。
但它有一个更重要的意义:它可以作为可解释性研究的“模型生物学实验体”。研究人员可以先在这种干净、小型、可读的模型中搞清楚 Transformer 的底层规律,再尝试迁移到真正的前沿大模型上。这带来了两条新的研究路线:一种是从密集模型中直接提取稀疏电路,不需要重新训练;另一种是让稀疏结构变得更高效,使它从研究工具逐渐走向工程实践。
OpenAI 想让未来的大模型摆脱“不可拆解”的黑箱属性,使每一步计算过程都像电路图一样清晰可追溯。Circuit-Sparsity 或许只是这一探索路上的一块踏脚石,它不一定会成为主流方案,但足以改变讨论的方向。




