
DoorDash 构建了一套模拟 + 评估的“飞轮”体系,用于加速基于大语言模型(LLM)的客服聊天机器人开发与测试。借助这一系统,工程师可以在几分钟内运行数百场模拟对话,大幅缩短实验迭代周期。通过该框架验证的一系列上下文工程优化,在上线前将幻觉率降低了约 90%。
DoorDash 在一篇领英博文中指出:
在将大模型客服系统投入生产之前,最根本的挑战是如何验证其可靠性:当一个聊天机器人每次回答都可能不同,你该如何测试它?
传统客服自动化通常依赖确定性的决策树流程。用户根据菜单选项或关键词进入预设路径,这种模式使开发者能够通过常规测试验证变更效果。而大模型 Agent 处理的是自然对话,这意味着即使只是对提示词、上下文或后端集成做出微小调整,也可能在不同对话路径上产生不可预测的结果。
为了解决这一问题,DoorDash 构建了一套离线实验框架,将大模型驱动的“客户模拟器”与自动化评估系统结合在一起。模拟器可以生成多轮对话,尽可能还原真实客服场景。它会基于历史客服记录提取用户意图、对话流程以及行为模式。同时,订单查询、退款流程等后端依赖也通过模拟服务 API 进行复现,从而构建出接近真实业务运行状态的测试环境。
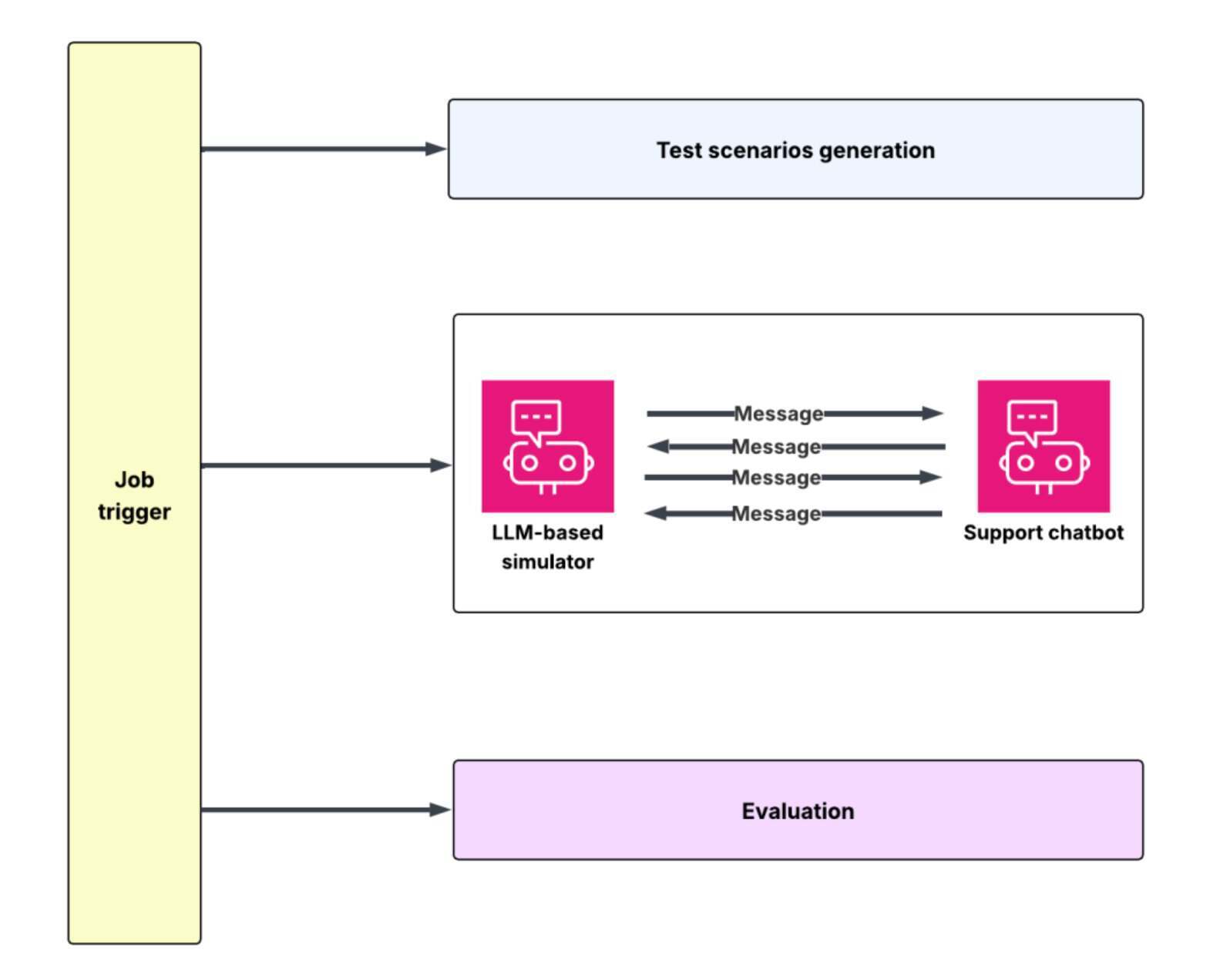
模拟的工作流概览 (来源:DoorDash 博客)
在模拟的环境中,一个大模型扮演客户角色,而生产版本的聊天机器人则像真实交互中那样作出回应。模拟器会根据机器人的回答动态调整对话进程,例如澄清自己的请求、表达不满情绪,或反复提出问题。与此同时,自动评估框架会依据预设策略和指标对结果进行分类和打分,例如合规性、幻觉率、语气表现以及任务完成准确度等。模拟与评估共同构成一个持续运转的开发闭环:工程师可以定位失败案例、补充评估规则,并生成更多针对性模拟对话。在部署之前,新的提示策略、检索方式或上下文优化方案都可以通过数百轮对话测试进行验证。
这一飞轮机制还帮助团队解决了上下文窗口过载导致的幻觉问题。早期的上线经验显示,大量原始事件和日志输出可能误导聊天机器人,导致字段理解错误或提出不合规的建议。工程师因此设计了一个“二元幻觉指标”,并基于真实失败案例构建测试场景。在不断迭代过程中,团队引入了一个 case state 层,用于对工具调用历史进行结构化整理,从而为聊天机器人提供更清晰的上下文。借助模拟器,他们可以快速测试不同上下文组织方式和提示策略,迅速暴露潜在失败模式并验证改进效果。
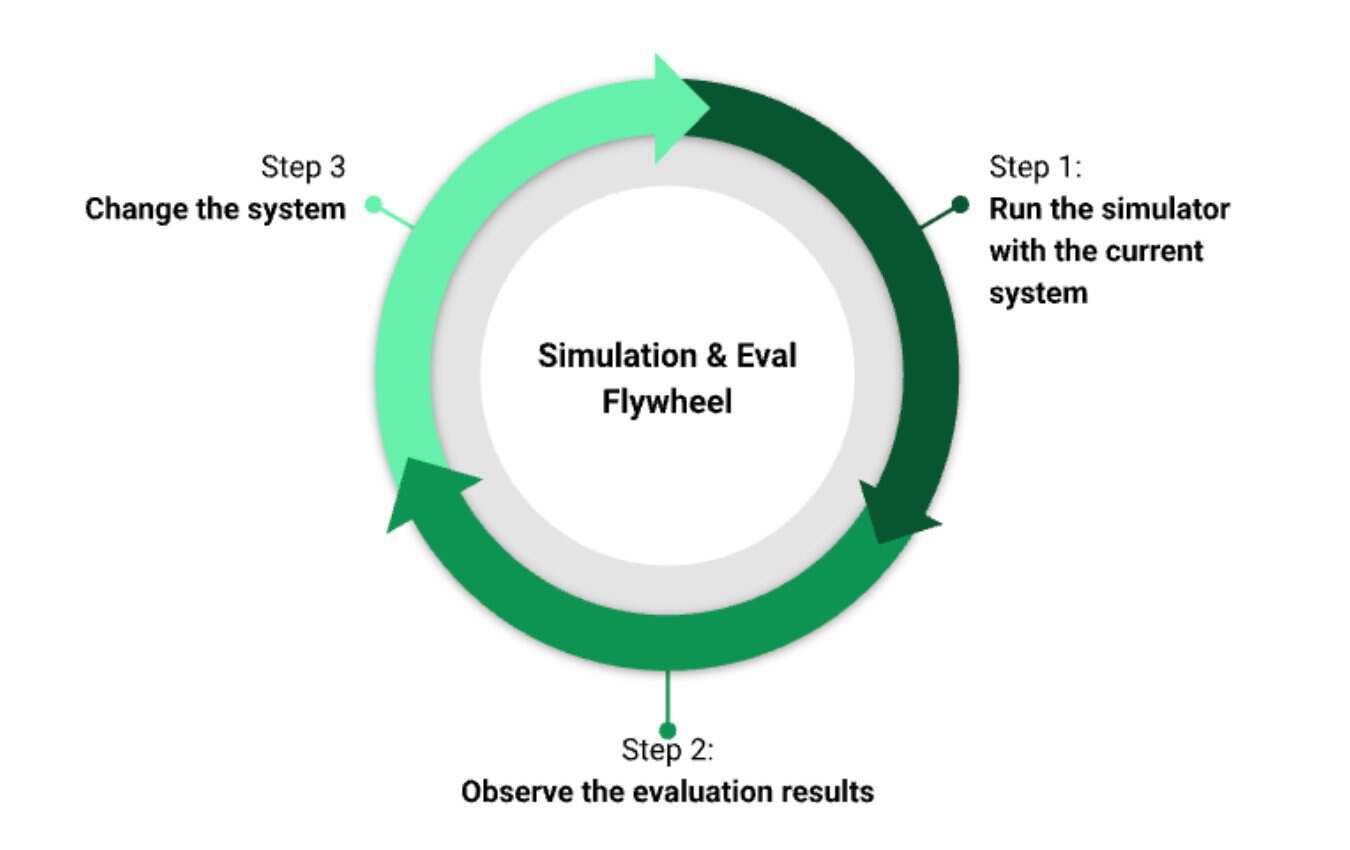
模拟加评估的飞轮(来源:DoorDash 博文)
DoorDash 的飞轮流程遵循一条清晰的从问题到上线的工程路径。工程师首先识别真实用户问题,这些通常来自人工分析客服案例或早期模拟结果。随后,他们构建“大模型做评委”评估模块来检测特定的失败模式,并通过与人工判断对齐来校准准确性。一旦评估机制足够可信,模拟器便会生成代表当前系统状态的大量对话,由评估系统识别其中的失败点。工程师则负责分析错误,调整提示词、上下文处理或工具输出,并不断迭代,直到评估通过率达到可接受水平。
在最终部署之前,团队还会通过完整评估套件验证多种安全护栏,例如幻觉检测、语气评估和问题分类能力,以确保这些改进在真实线上流量中同样有效。




