
Airbnb 的工程团队推出了Mussel v2,这是对其内部键值引擎的一次彻底重构,旨在统一流式处理和批量摄取,同时简化运维并扩展到更大的工作负载。据报道,新系统能够维持每秒超过 100,000 次流式写入,支持超过 100TB 的表,p99 读取延迟在 25 毫秒以下,并且能够批量摄取数十 TB 的数据,使调用团队能够专注于产品创新而不是管理数据管道。
早期版本的Mussel v1为 Airbnb 的内部数据服务提供了动力,但随着数据量和产品集成的增加,其局限性日益显现。它的静态哈希分区设计运行在Amazon EC2上,并通过Chef脚本进行管理。独立的批处理和流式路径增加了运维开销,并使得确保一致性变得很困难。
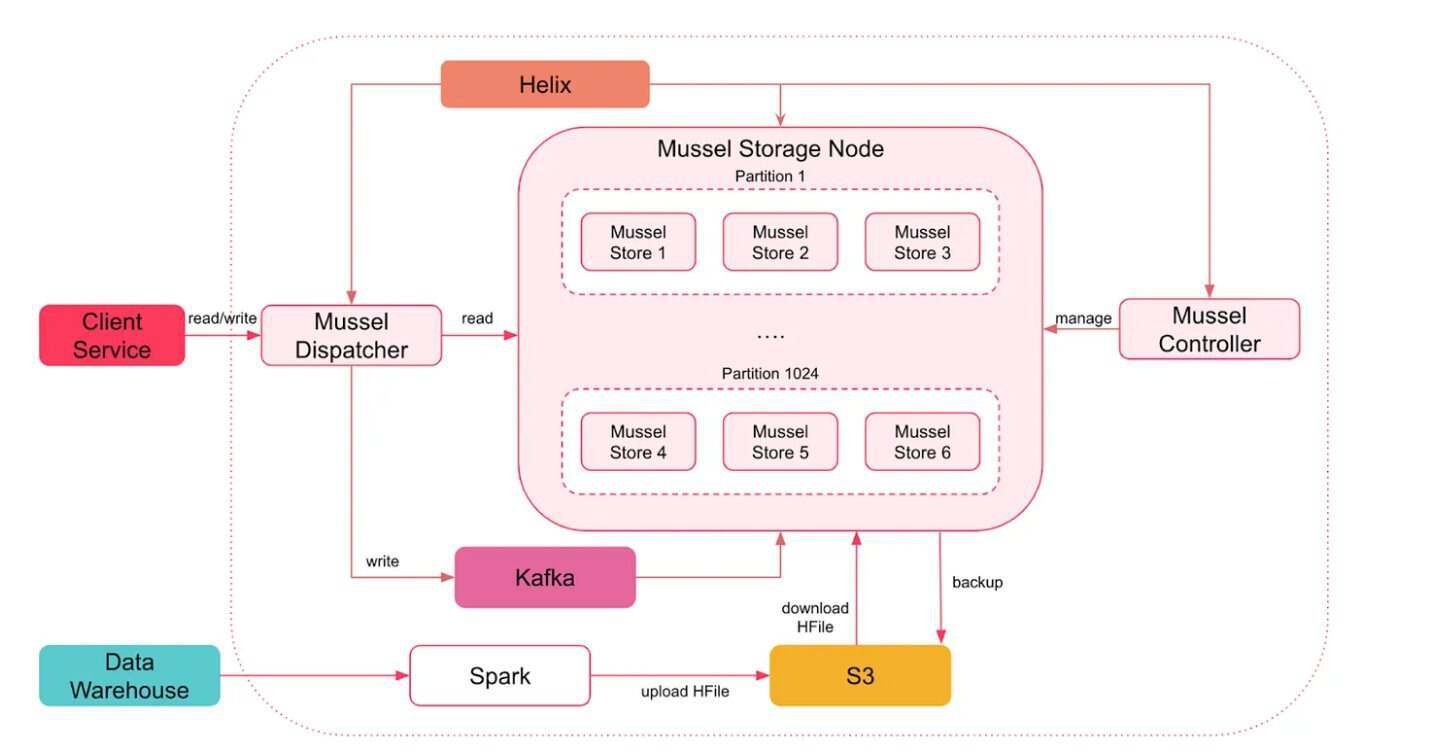
Mussel V1 架构(图片来源:Airbnb工程博客)
Mussel v2 通过将 NewSQL 后端与Kubernetes原生控制平面结合,解决了这些限制,提供了对象存储的弹性、低延迟缓存的响应性以及现代服务网格的可操作性,所有这些都集成在一个单一平台上。系统使用 Kubernetes 清单和自动部署,动态范围分片与预分割以缓解热点问题,以及命名空间级别的配额和仪表板以提高成本透明度。调度器(Dispatcher)层是无状态的,并且可以水平扩展,能够路由客户端 API 调用,处理重试,并支持双重写入和影子读取模式以促进迁移。
写入首先会被持久化到Kafka中以确保持久性,下游的重放器(Replayer)和写入调度器(Write Dispatcher)组件按顺序将它们应用到后端数据库。批量加载会继续通过 Airbnb 的数据仓库来使用Airflow作业和 S3 暂存,保留了合并或替换的语义。工程团队还引入了一个拓扑感知的过期服务,将数据命名空间分片成基于范围的子任务,由多个工作者并发处理。过期记录会基于调度进行并行删除,以限制对实时查询的影响,而写入密集型表使用最大版本限制和有针对性的删除。根据团队的说法,这些增强功能在保持 v1 保留功能的同时,提高了效率、透明度和可扩展性。
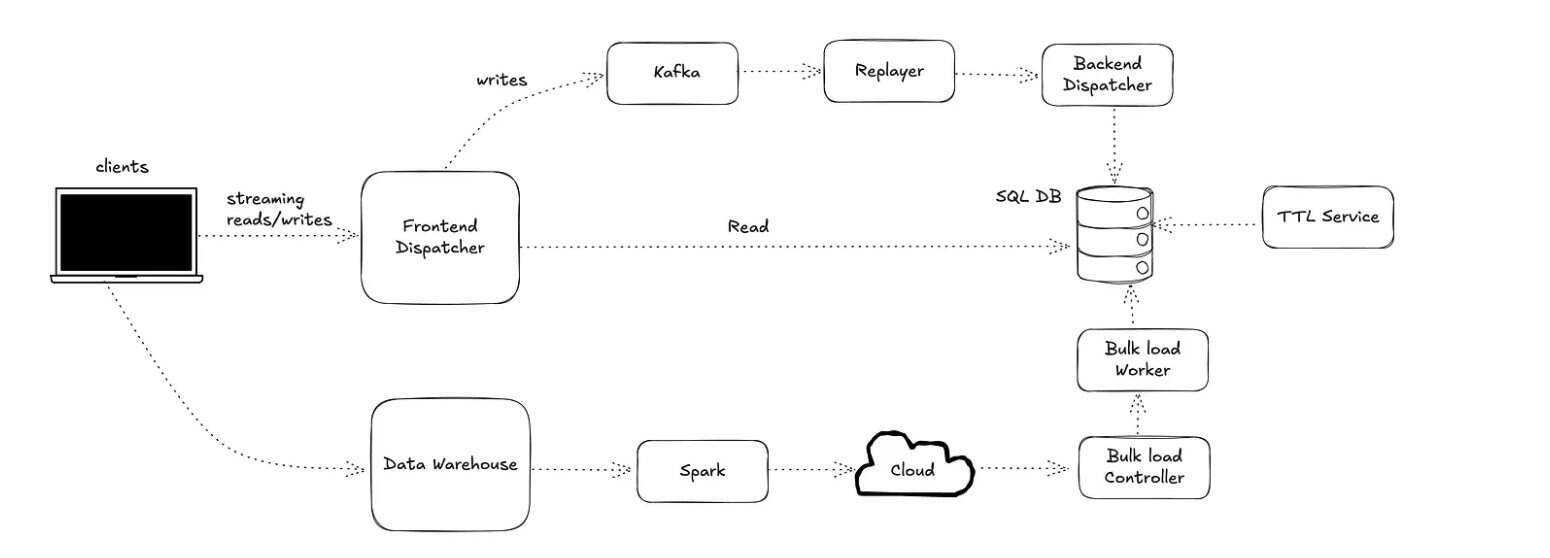
Mussel V2 架构(图片来源:Airbnb工程博客)
根据 Airbnb 的工程团队的说法,从 v1 迁移到 v2 带来了重大挑战。团队使用了具有表级别粒度的蓝绿方法、持续验证和回退机制。由于 v1 缺乏原生变更数据捕获或表快照,表通过备份和抽样数据引导到 v2 以计划预分割。在引导摄取和验证校验和之后,再应用滞后的 Kafka 事件,并启用双重写入。在切换过程中,读取逐渐转移到 v2,而影子流量监控一致性,如果错误率激增则回退到 v1。Kafka 在整个迁移过程中充当公共日志。
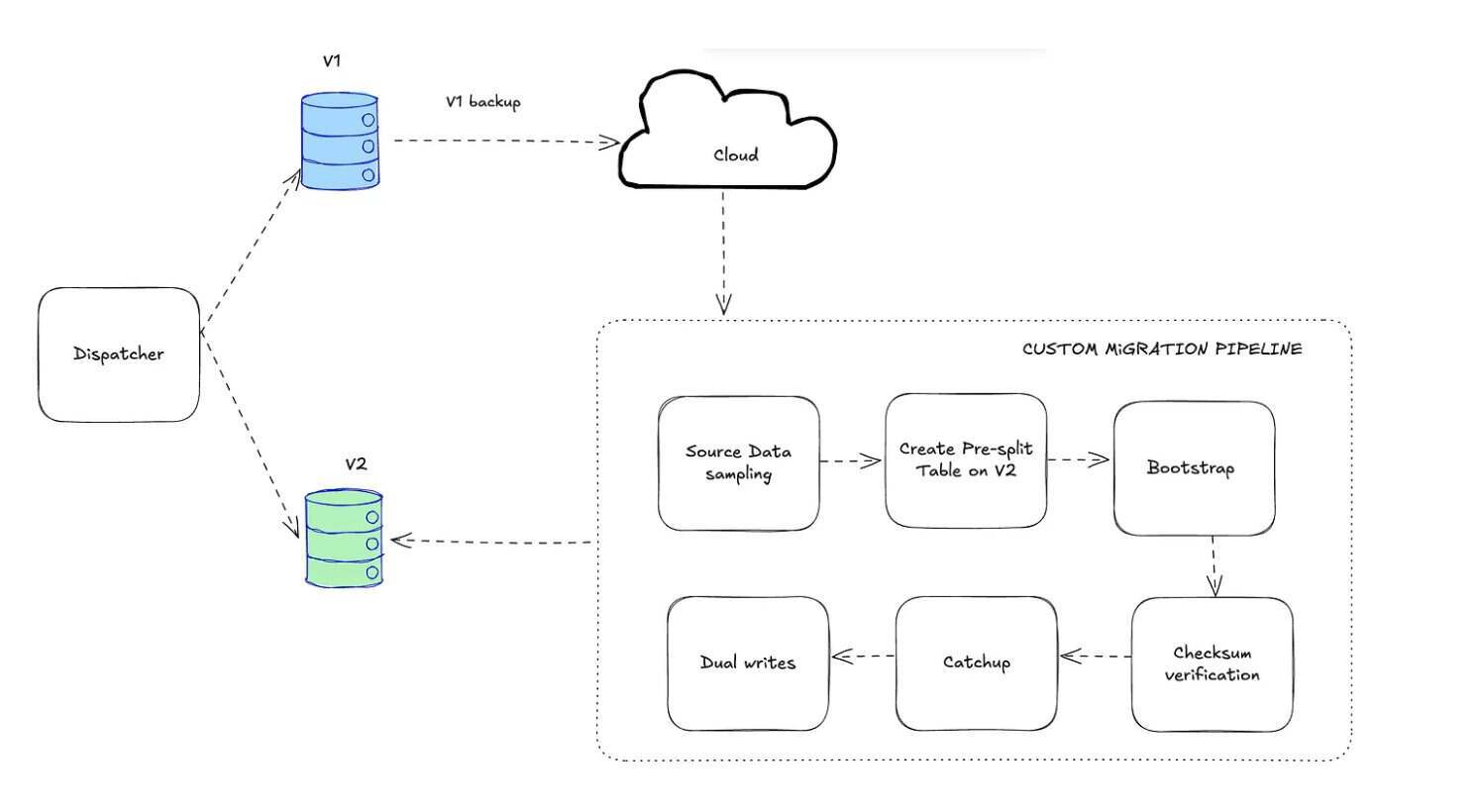
从 Mussel V1 到 V2 的数据迁移管道(图片来源:Airbnb工程博客)
Airbnb 的工程师报告说,从最终一致性后端迁移到强一致性后端涉及到运维的复杂性,包括写入去重和控制重试。他们对查询执行和工作负载分配进行了调整,而 Kafka 充当持久化日志。每个表的暂存、自动回退和监控使得在没有停机的情况下迁移了超过 1PB 的数据。
查看英文原文:Airbnb’s Mussel V2: Next-Gen Key Value Storage to Unify Streaming and Bulk Ingestion




