
优步(Uber)已成功完成一项大规模的Kubernetes迁移,将其整个计算平台从Apache Mesos迁移到Kubernetes,覆盖了多个数据中心和云环境。这家网约车巨头的工程团队在一系列技术博客文章中详细描述了他们的全面旅程,揭示了迁移数千个微服务和大规模计算工作负载时所面临的挑战、解决方案和经验教训。
这一迁移代表着优步基础设施架构的根本性转变,影响着全球市场上从叫车到送餐的数千项服务。该公司之前的计算平台是基于 Apache Mesos 构建的,在优步(Uber)快速增长阶段为其提供了良好的服务,但随着组织向更云原生的方式演进,它也呈现出了局限性。
优步的工程团队解释说:“这次迁移不仅仅是一次技术变革,而是对我们如何运营计算基础设施的彻底重新构想。”该项目历经多年,并需要在众多工程团队之间进行了仔细协调,以确保关键服务的零停机时间过渡。
优步对 Kubernetes 迁移的方法是有条理且存在风险规避的,优先考虑服务的可靠性而不是迁移速度。工程团队开发了一个复杂的迁移框架,允许逐步进行服务转换,同时保持与现有基于 Mesos 的服务的完全向后兼容性。
迁移策略围绕几个关键原则展开:
在整个转换过程中保持服务的可靠性
确保与现有工具和工作流程的无缝集成
在新的 Kubernetes 环境中建立健壮的监控和可观测性能力。
该团队采用了双栈方法,在过渡期间同时在 Mesos 和 Kubernetes 上运行服务,以最大限度地降低风险。
最重要的技术挑战之一是如何调整优步内部广泛的工具和平台套件,使其与 Kubernetes 适配并协同工作。这包括重新实现部署管道、监控系统和与 Mesos 生态系统紧密集成的服务发现机制。
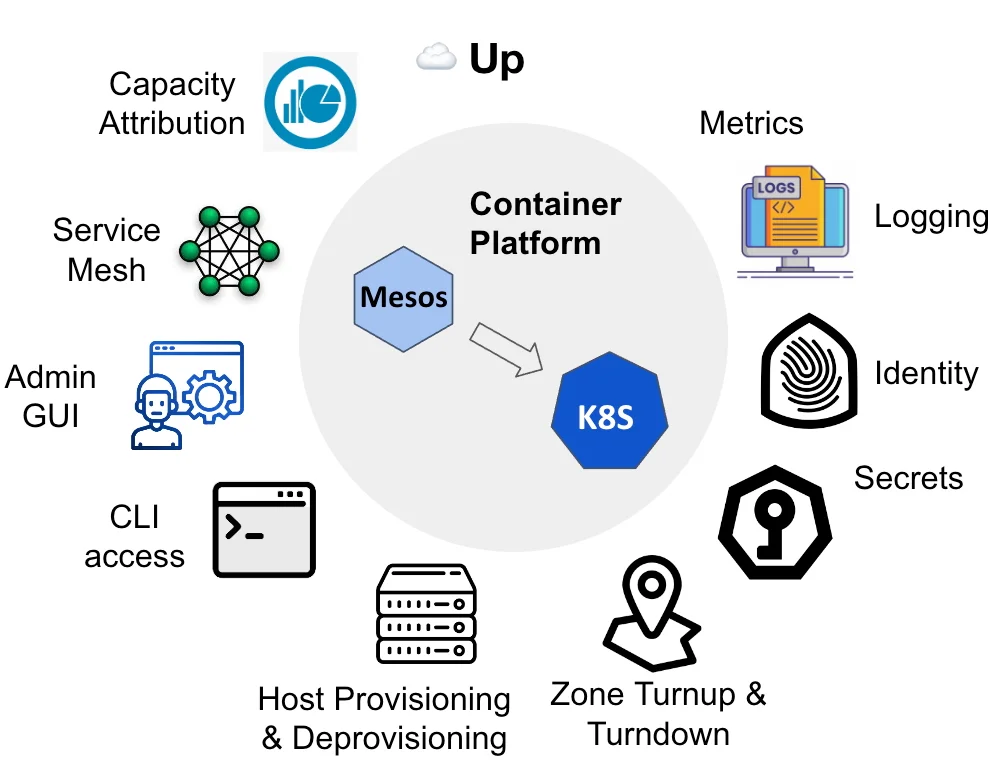
优步从 Mesos 迁移到 Kubernetes 的生态系统
除了迁移标准的微服务之外,优步还面临着迁移大规模计算工作负载的复杂性挑战,这些工作负载为包括机器学习模型训练、数据处理管道和分析工作负载在内的关键业务功能提供动力。由于资源需求和性能敏感性,对这些计算密集型应用程序提出了独特的挑战。
工程团队为在 Kubernetes 中处理这些工作负载开发了专门的解决方案,例如将 DSW 会话建模为 Kubernetes 中的自定义资源定义(Custom Resource Definition,CRD),优化的网络配置和增强的调度能力。优步工程师还使用 Federator 实施了复杂的资源分配机制,Federator 是一个集群联邦层,提供了对 Kubernetes 批处理集群的抽象。这因为如此,大规模批处理作业才可以与实时服务高效共存,而不会影响面向用户的应用程序。
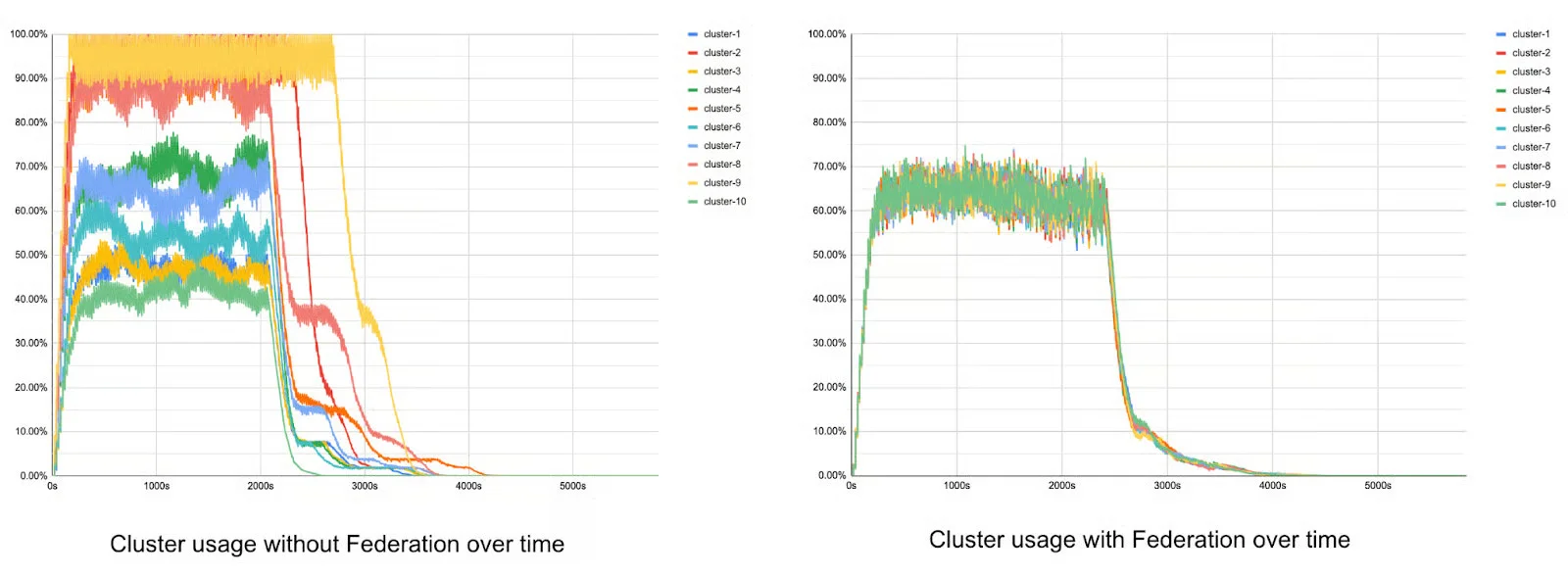
使用联邦和不使用联邦的 Kubernetes 集群
迁移过程中并非没有重大的技术障碍。优步的工程团队遇到了与网络复杂性、大规模资源管理和在不同基础设施范式之间保持性能基准相关的挑战。该公司的全球业务对此增加了额外的复杂性,需要在多个地区和云提供商之间提供一致的有效解决方案。
其中一个特别的挑战是,在将服务前移到新平台时,需要保持优步严格的延迟要求。团队实施了全面的性能测试和逐步的推出策略,以确保在整个迁移过程中服务质量能保持一致。
工程团队还必须解决文化和运营方面的挑战,包括培训数百名工程师以了解 Kubernetes 的概念,并更新开发工作流程以与云原生实践保持一致。
完成的迁移在多个维度上带来了实质性的好处。优步报告说称,其运营效率得到了提高,开发人员的生产力得到了增强,整个基础设施的资源利用率也得到了提高。迁移到 Kubernetes 还使公司能够更好地利用云原生技术和实践,实现了更快的创新和更灵活的部署策略。
新平台提供了增强的可扩展性能力,使优步能够更有效地处理流量高峰和季节性的需求变化。此外,迁移还简化了优步的基础设施管理,降低了运营开销,并使团队能够更多地专注于产品开发,而不是平台维护。
同样,其他大公司也将他们的核心基础设施迁移到了 Kubernetes:Figma 在 12 个月内将核心服务迁移到了 Kubernetes,或者像 CERN 这样的组织,他们将 CMSWEB 集群迁移到了 Kubernetes。这些例子以及优步成功迁移到 Kubernetes 的案例,为其他考虑类似转型的大型组织提供了宝贵的案例研究。该公司详细记录了他们的旅程,提供了对企业采用 Kubernetes 的最佳实践的洞见,特别是对于那些在显著规模上运营的组织。
原文链接:
https://www.infoq.com/news/2025/05/uber-kubernetes-migration/




