
Shopify 推出了一款经过重新设计的 GraphQL 执行引擎,内部代号为 GraphQL Cardinal。该引擎用广度优先执行模型取代了传统的深度优先遍历,据称在处理大规模查询工作负载时,生产环境的性能得到了显著提升。新架构旨在解决 GraphQL 执行本身存在的低效问题,而非数据库或网络基础设施中的瓶颈。Shopify 工程师认为,长期以来,这一领域在 GraphQL 生态系统中一直没有受到充分关注。
在 X 平台的一篇帖子中,Shopify 工程团队总结了测试结果:
在生产环境中,采用广度优先策略的大型 GraphQL 列表查询,其字段级执行速度提升了 15 倍,垃圾回收开销减少了 6 倍,P50 端到端时间缩短了 4 秒以上。
/filters:no_upscale()/news/2026/06/shopify-graphql-cardinal-bfs/en/resources/1Screenshot%202026-05-23%20at%2011.12.16%E2%80%AFAM-1779561190654.png)
广度优先遍历与深度优先遍历的端到端响应时间比较(图片来源:Shopify 博客)
这次重构针对的是传统 GraphQL 执行的一个核心特征。大多数 GraphQL 引擎会递归遍历查询树,并采用深度优先的方式逐个解析字段。虽然这种方法简单直观,但在处理涉及深度嵌套、高度关联的数据集(例如电商系统中常见的产品目录、商品变体和库存结构)时,可能会导致解析器被反复调用、内存分配模式碎片化,以及垃圾回收负担过重。
GraphQL Cardinal 通过在实体集合中逐层执行查询,改变了这种遍历模型。引擎不再针对树上的每个节点单独解析字段,而是将解析器的执行做批量处理,针对同一深度的对象组进行操作。Shopify 表示,这种方法可以提高 CPU 缓存的局部性,减少冗余计算,并降低每次请求的内存波动。
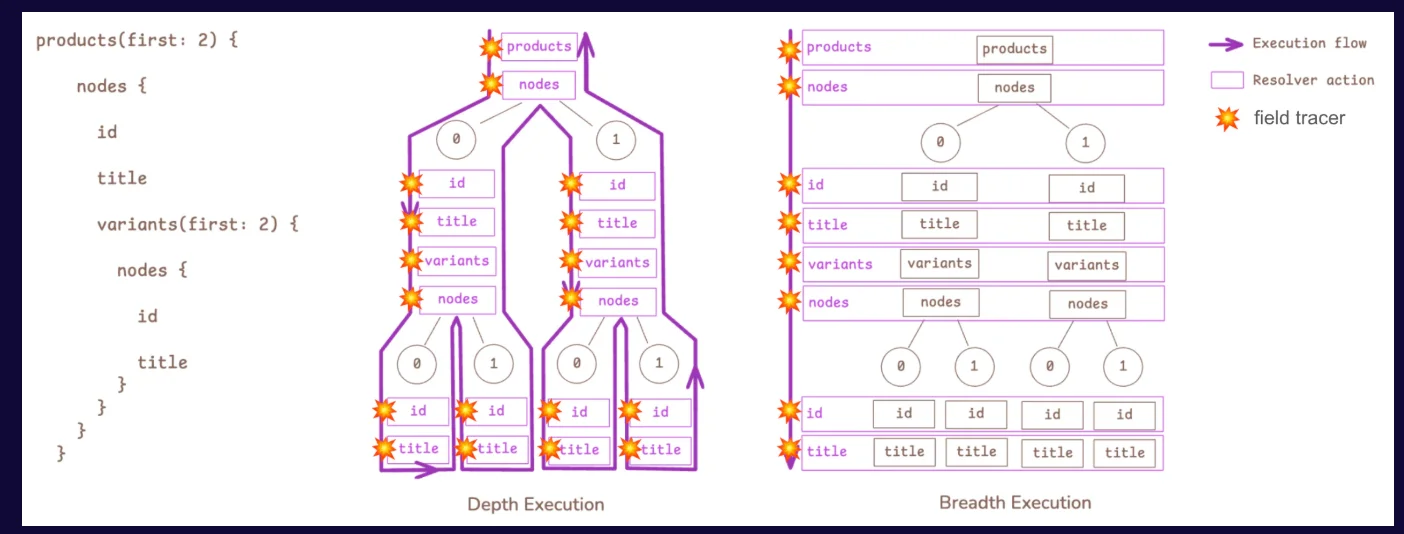
深度优先与广度优先的执行流程及字段追踪器(图片来源:Shopify 博客)
这次重构还改变了内部的执行协调机制。在递归遍历过程中,GraphQL Cardinal 不再反复调用解析器,而是按查询层协调执行,使解析器能够在深入图结构之前批量处理实体。这使得批处理成为一种原生的执行行为,而非单独的优化措施。该方法基于 GraphQL 生态系统探索过的诸多理念,包括 Airbnb 用于减少 N+1 查询开销的批处理解析器、WunderGraph 的广度批处理实验,以及 graphql-breadth-exec 等项目——这些项目探索了替代递归执行的广度优先遍历方案。
在 LinkedIn 的一篇博文中,Shopify 工程总监Farhan Thawar 写道:
GraphQL Cardinal 是 Shopify 对一个显而易见却被忽视的问题所作出的回应:在规模化应用时,传统的 GraphQL 执行在算法上代价高昂,但鲜有人对此提出质疑。
然而,Shopify 的实现方案之所以引人注目,在于它不仅将广度优先遍历直接大规模集成到了生产基础设施中,同时还保持了与现有 GraphQL 模式和 API 的兼容性。据该公司称,这次迁移需要在执行编排、解析器行为、追踪基础设施以及运行时调度系统等方面进行协调一致的变更。
这次迁移面临的一大关键挑战在于,在改变底层执行行为的同时,仍然需要保留面向开发者的现有 GraphQL 语义。现有的模式和解析器是基于递归的深度优先假设而设计的,这意味着 Shopify 需要调整解析器的协调和追踪机制,同时避免大规模重写 API。该公司表示,整个部署过程始终保持着与现有 GraphQL API 的兼容性,使各团队能够从执行性能的提升中受益,而又不需要更改应用程序级的查询结构。
原文链接:https://www.infoq.com/news/2026/06/shopify-graphql-cardinal-bf




