
“我们的模型表现超过了其他模型,欢迎不认同的友商来 LMSYS 打擂台,证明我是错的。但在那发生之前,我们会继续说我们是最好的模型。”李开复在 5 月 21 日的分享会上说道。
李开复的底气来自 Yi-Large 一直以来不错的测评表现。而最近的 5 月 20 日,在 LMSYS 盲测竞技场最新排名中,零一万物的最新千亿参数模型 Yi-Large 总榜排名世界第七,中国大模型中第一,已经超过 Llama-3-70B、Claude 3 Sonnet,中文榜更是与 GPT4o 并列第一。
零一万物也因此成为总榜上唯一一个自家模型进入排名前十的中国大模型企业。在总榜上,GPT 系列占了前十位的四个名额。以机构排序,零一万物 01.AI 仅次于 OpenAI、Google、Anthropic,正式进入国际顶级大模型企业阵营。
榜单表现
让零一万物振奋的原因是 LMSYS 是大模型金标准,都是第三方匿名,而且每个模型都有数万用户评估,结果可信度非常高。OpenAI 的 Sam Altman 和 Google CTO Jeff Dean 都在最近的模型发布中引用了该测试结果。
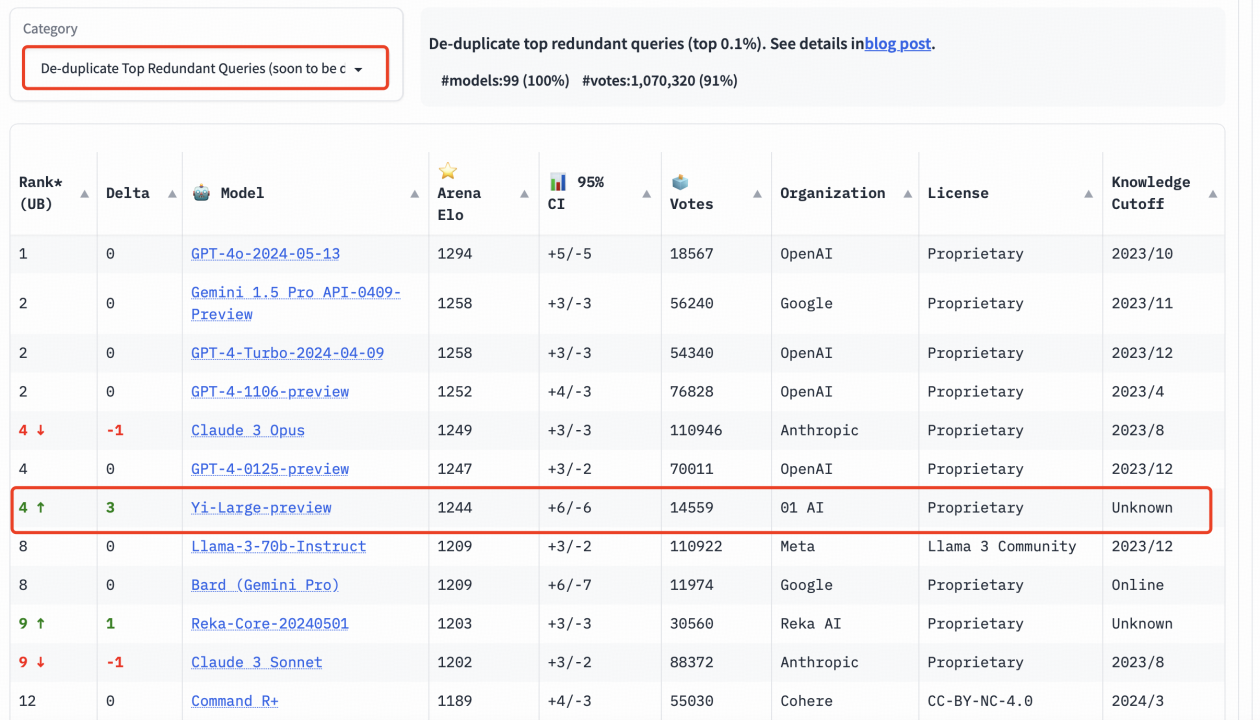
为了提高 Chatbot Arena 查询的整体质量,LMSYS 实施了重复数据删除机制,并出具了去除冗余查询后的榜单。这个新机制旨在消除过度冗余的用户提示,如过度重复的“你好”。这类冗余提示可能会影响排行榜的准确性。LMSYS 公开表示,去除冗余查询后的榜单将在后续成为默认榜单。
在去除冗余查询后的总榜中, Yi-Large 的 Elo 得分更进一步,与 Claude 3 Opus、GPT-4-0125-preview 并列第四。
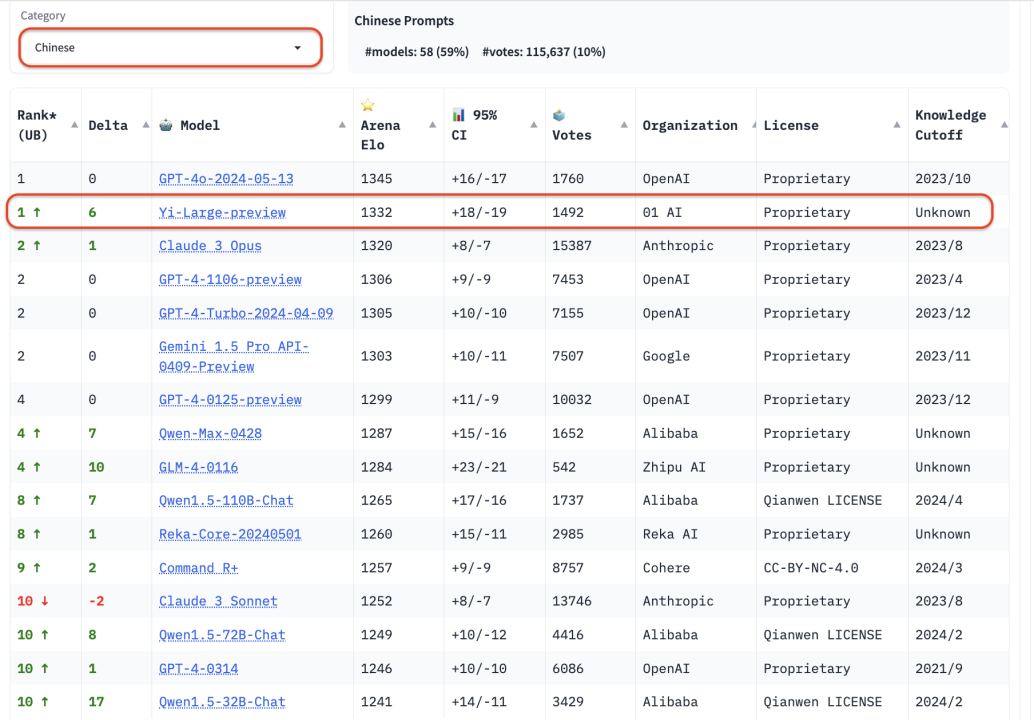
国内大模型厂商中,智谱 GLM4、阿里 Qwen Max、Qwen 1.5、零一万物 Yi-Large、Yi-34B-chat 此次都有参与盲测。在总榜之外,LMSYS 的语言类别上新增了英语、中文、法文三种语言评测,开始注重全球大模型的多样性。Yi-Large 的中文语言分榜上拔得头筹,与 OpenAI GPT-4o 并列第一。
在分类排行榜中,编程能力、长提问及最新推出的 “艰难提示词” 的三个评测是 LMSYS 所给出的针对性榜单,以专业性与高难度著称,可称作大模型“最烧脑”的公开盲测。
在编程能力(Coding)排行榜上,Yi-Large 的 Elo 分数超过 Anthropic 当家旗舰模型 Claude 3 Opus,仅低于 GPT-4o,与 GPT-4-Turbo、GPT-4 并列第二。长提问(Longer Query)榜单上,Yi-Large 同样位列全球第二,与 GPT-4-Turbo、GPT-4、Claude 3 Opus 并列。
艰难提示词(Hard Prompts)则是 LMSYS 为了响应社区要求,新增的排行榜类别。这一类别包含来自 Arena 的用户提交的提示,这些提示则经过专门设计,更加复杂、要求更高且更加严格。LMSYS 认为,这类提示能够测试最新语言模型面临挑战性任务时的性能。在这一榜单上,Yi-Large 处理艰难提示的能力也得到印证,与 GPT-4-Turbo、GPT-4、Claude 3 Opus 并列第二。

测评结果:Coding、Longer Query、Hard Prompts
在此之前,各种静态榜单几乎成为厂商必争的地方。在零一万物模型训练负责人黄文灏看来,所谓打榜主要是厂商要把模型某些单一能力做提升,但比较的时候大家可能并不了解,会带来一些 bias。LMSYS 提供了一种更接近于用户真实场景的评测方式,所以可以作为一个更好的衡量标准。
李开复:不会对标“价格战”
用好的模型,贵不贵?当前,Yi-Large API 的定价是 0.02 元/千 tokens,大概是 GPT-4 Turbo 成本和定价的三分之一。
成本问题其实是零一万物一直以来就在关注的。“在大模型时代,模型训练和推理成本构成了每一个创业公司必须要面临的增长陷阱。”李开复曾说道。
“我们关注到最近降价的现象,我认为我们的定价还是非常合理的,而且我们也在花很大精力希望它能再降下来。”李开复表示,整个行业每年降低 10 倍推理成本是可以期待的,而且也必然发生的,以这个角度看,现在的降价对整个行业来说就是一个好消息。
但对于大模型公司,李开复认为,国内常看到 ofo 式的疯狂降价、双输的打法,大模型公司不会这么不理智,因为技术还是最重要的,如果技术不行,纯粹靠贴钱、赔钱做生意是行不通的。
李开复以万知为例介绍到,零一万物内部也纠结过用 Yi-Medium,中尺寸模型有成本优势,但是大尺寸模型更有泛化和推理能力优势。考虑到万知用户也包括海外用户,还是需要最强的推理能力,因此团队最终选择了千亿参数的 Yi-Large。
“虽然这并没有达到 TC-PMF、还不能赚钱,但是技术的需求是不可妥协。推出之后,模型和 Infra 团队就一起快速把钱降下来。”李开复说道。
对于当前的大模型价格战,李开复明确表示不会对标这样的(市场)定价。“如果中国市场就是这么卷,大家宁可赔光、通输也不让你赢,那我们就走外国市场。”
“最小到最大的模型,做到中国最好”
在做大模型方面,零一万物将继续坚持 Scaling Law。从最小的 6B 到 34B,到现在的千亿模型,还有训练中的万亿 MoE,零一万物技术团队明显看到模型性能随着参数量的增大,智能水平也在显著上升,Scaling Law 给 AGI 指明了一个方向。
以大模型为代表的就是大规模机器学习,需要过大量的算力做大量的实验来得到结论,同时需要算法和 Infra 做联合优化。
在 Scale up 过程中,最能够高效使用算力的通用结构一般会获得较大成功。在模型结构上加了各种各样的 prior(先验知识)、去调优可以获得更好效果,但这些 prior 也是约束条件,对模型效果产生影响。零一万物发现,最简单的模型就是最高效的,重要的是怎么去用好计算能力,而给定算力条件下的智能水平,最重要的是数据的质量和使用数据的效率、计算效率。
黄文灏表示,零一万物需要算法、Infra 和工程三位一体的人才,但这样的人在国内并不是很多。大模型研发中,人才的作用被放大,比如算法团队不需要特别多的人,一般是 10~20 人,但是他们后面是几万张卡,这些人的能力就被几万张卡放大了很多。
目前,零一万物的系列大模型参数刚迈入千亿行列,但已经可以与 GPT-4、Gemini 1.5 Pro 等万亿级别的超大参数规模模型扳手腕。
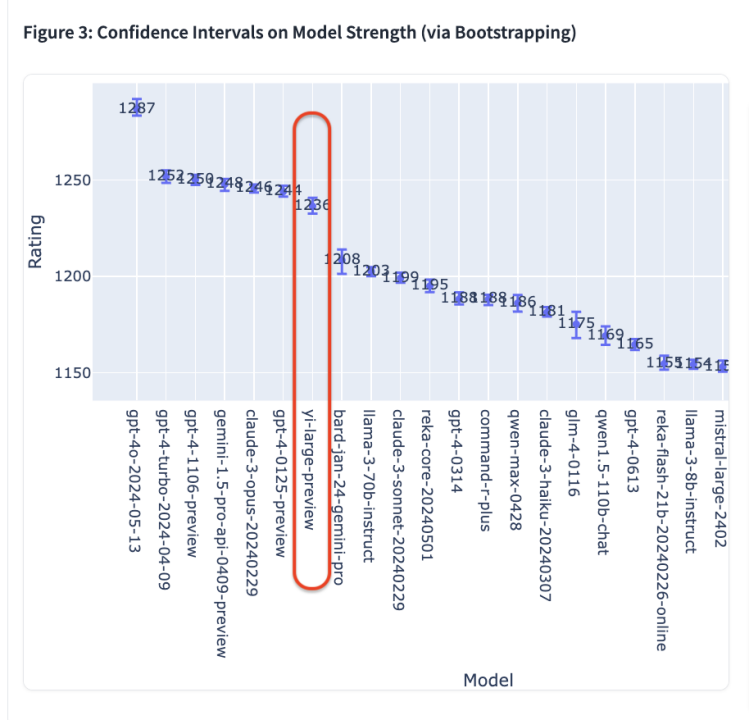
在 Chatbot Arena 测评的 44 款模型中,GPT-4o 在最新的 Elo 评分中以 1287 分高居榜首,GPT-4-Turbo、Gemini 1 5 Pro、Claude 3 0pus、Yi-Large 等模型则以 1240 左右的评分位居第二梯队;其后的 Bard (Gemini Pro)、Llama-3-70b-Instruct、Claude 3 sonnet 的成绩则断崖式下滑至 1200 分左右。
“我们的计划是从最小到最大的模型都能够做到中国最好。”李开复表示。一方面,根据 scaling law,越大尺寸的模型约有可能达到 AGI;另一方面,小一些的模型也有各种应用机会。因此,零一万物的打法是“一个都不放过”,并且在每一个潜在尺寸上做到性能最高、推理成本最低。
不过另一个现实是,零一万物 GPU 存量只有 Google、Microsoft 的 5%,但李开复认为这并不代表企业就没有机会。
“能用同样一张卡挤出更多的价值,这是今天我们能够达到这些成果的重要原因之一。”李开复说道。




