
微医是总部位于杭州萧山的一家互联网医疗公司,我们的前端研发人员从 2015 年的几个人发展到现在的 120 多人,前端技术栈体系发生了巨大的变化,下面这张图展示了我们部门前端团队的技术栈演进过程。

16 年之前主要是前后端耦合的开发方式。
17 年开始引进 Vue,进行前后端分离,并开始尝试做 Vue SSR 的探索。
18 年全面推 Vue SSR,积累了一定的 Node.js 经验,出现了越来越多的线上 Node.js 应用。
今年主要是将之前的解决方案沉淀下来,变成框架、文档、插件、脚手架等,来更好的支持需求的迭代。
可以看到在微医, Node.js 在线上应用起步较晚,但是发展很快,例如消费线业务基本都迁移到了 SSR 技术体系。下面这张图是我们公司前端应用的分布情况。
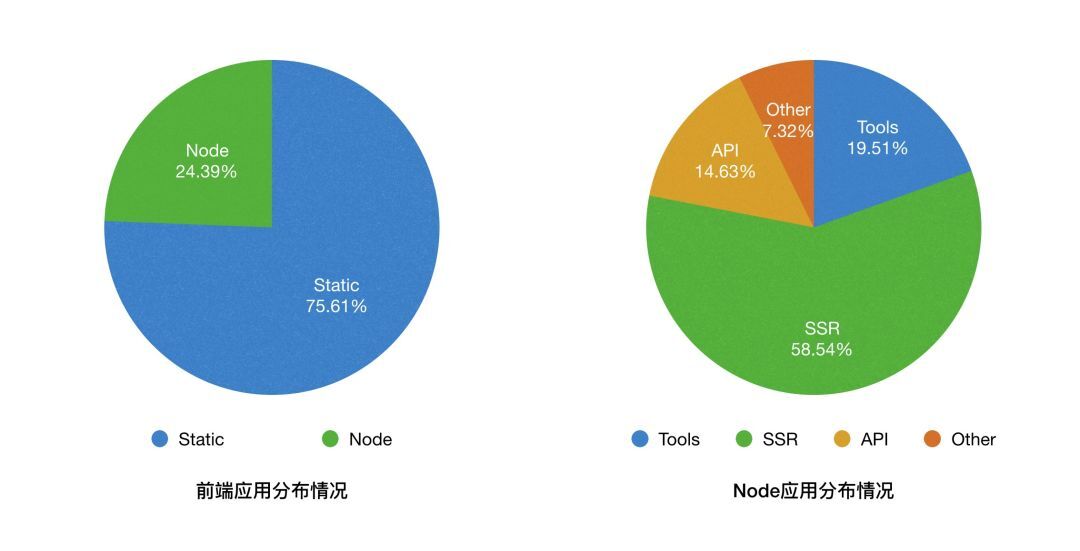
可以看到,集团总体前端应用中,Node.js 应用大概占比 1/4,而在 Node.js 应用中主要是 SSR 应用,其次是一些全栈体系的内部应用,接着是一些 API 服务,做一些接口的聚合和转发。
所以我今天主要从 Vue SSR、内部应用和 API 服务来介绍一下 Node.js 在微医的使用情况。
应用场景一:内部工具

我们团队在业务之余做了很多内部效率工具,来服务于集团内的其他角色,包括开发、测试、运营、产品等等,这些应用都有一个特点:使用 Node.js 来进行后端服务层的开发。这边我列举了三个我们的内部应用:
筋斗云 - 需求发布管理系统
魔方 - 可视化活动页面搭建平台
智能运营管家 - 社群运营工具
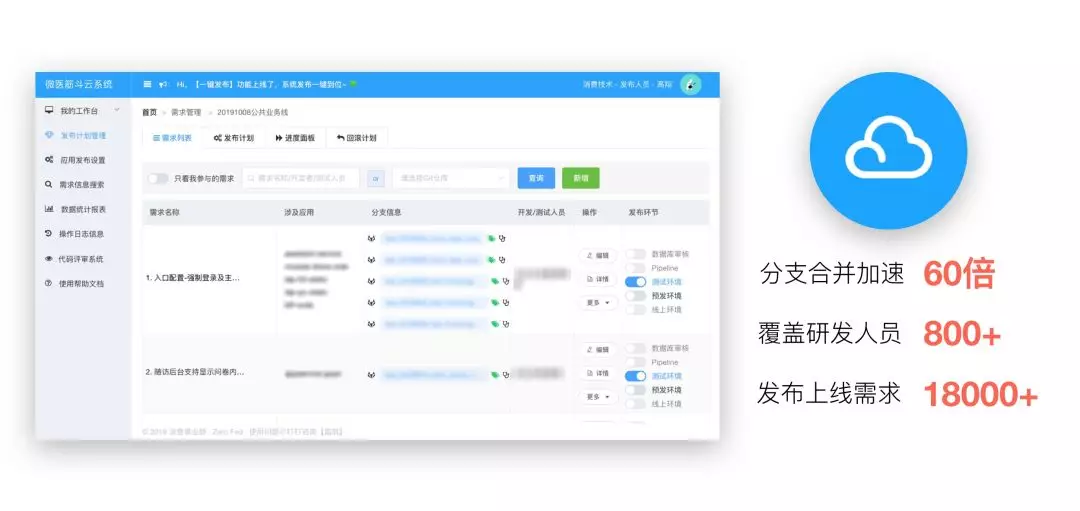
其中,筋斗云系统用于支撑需求的发布管理,是使用频率最高的内部平台之一。
我们以需求为单位,将整个需求发布流程中一些需要人工操作和不严谨的点整理出来,做成一个平台,来进行发布流程的把控,提高需求发布的效率和质量,其中的一些功能,比如:通过 GitLab API 来做分支智能合并、发布计划管理、一键发布、前端应用 package.json 变动监听、release 分支落后检测......这些小功能都可以为开发和测试提高成倍的效率和质量。这个系统里面 Node.js 也做了非常多的工作,比如数据的持久化、API 设计、Dubbo 服务调用 、钉钉消息推送、邮件提醒以及定时任务等等。
有了 Node.js 的加持,前端工程师能够发挥自己丰富的想象力,将想法变成产品,创造一些能够提高数倍效率的工具。
应用场景二:Vue 服务端渲染

除了内部应用,我们在 Vue SSR 方面也做了很多的研究和实践,前后端同构(同一种编程语言,同一套开发模式) 的应用拥有单页的用户体验,又自然支持 SEO, 让后端同学从表现层解脱出来,专注服务开发。

在 Vue SSR 中,我们的 Node.js 主要做了以下工作:
异步数据混合
我们参考 Nuxt.js 中对 asyncData 的操作,在 asyncData 钩子中获取数据后直接将数据对象返回,然后与组件中的 data 函数的对象进行混合,页面组件可以像操作 data 一样操作 asyncData 返回的数据,这样就可以很好的与 Vuex 解耦(官方推荐的做法是将 asyncData 中获取的数据存到 Vuex 中,组件从 Vuex 中取数渲染)。
通用工具封装
我们做了一些通用方法的封装,比如:Cookie 操作、路由操作等等,抹平了服务端和客户端的差异,同时还输出了一些非常好用的插件。
feb-alive 是一个 Vue 页面级缓存插件,使用 feb-alive 来代替 keep-alive 进行页面缓存,可以使我们的应用达到浏览器级别的路由体验(前进刷新,后退缓存),详细使用可以参考 https://github.com/wefront/feb-alive。
异常降级机制
对于一般的 SSR 应用来说,在服务端发生异常时都会返回一个 500 的页面,其实对于某一些场景,比如:接口调用异常、asyncData 中写了浏览器的代码,对于这种情况的异常我们可以返回一个 SPA 应用,在用户的浏览器上进行渲染,达到高可用。在介绍降级机制之前,先来看下降级的效果。
一开始是正常的服务端渲染 ,接着在 URL 中带上一个 degrade 参数后,服务端会返回一个 SPA 应用。然后我模拟了 asyncData 中接口异常的情况,可以发现服务端也返回了一个 SPA 应用,而不是一个 500 的异常页面。
接着介绍一下 SSR 降级机制的实现原理。首先如果要实现这样一套降级机制,我们得在构建客户端代码的时候生成一个 SPA 应用:
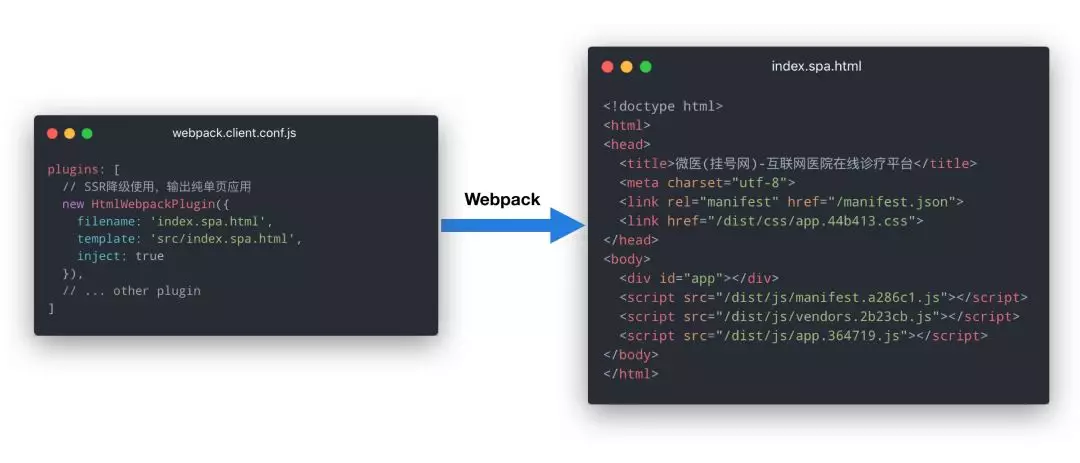
了解 Vue SSR 的同学都知道,服务端渲染会输入一个 window.__INITIAL_STATE__ 变量,里面存放着服务端的 Vuex 数据快照:
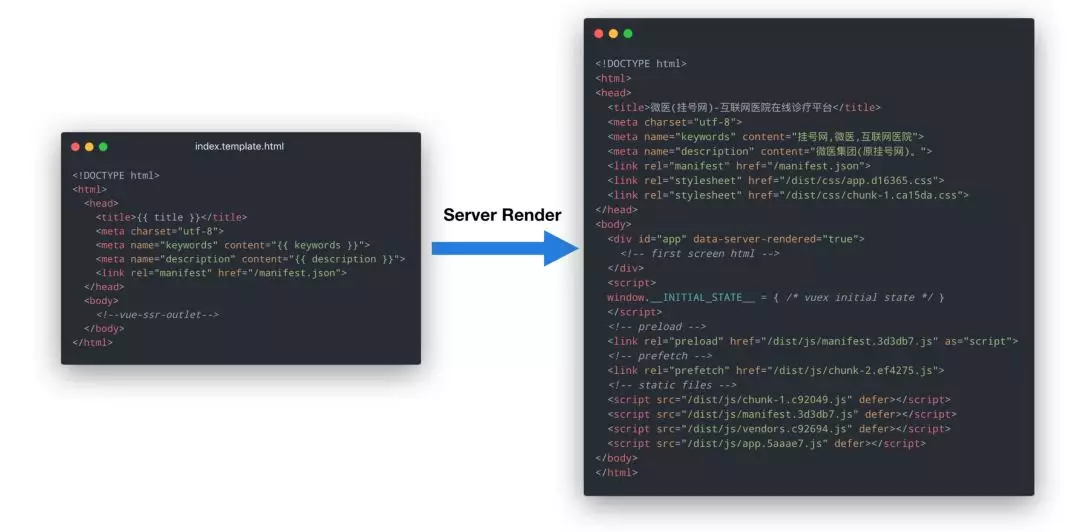
在客户端入口文件(entry-client.js)中,我们需求通过 window.__INITIAL_STATE__ 变量来判断本次渲染是正常渲染还是降级渲染,如果是降级渲染,还需要手动的调用 asyncData 方法进行首屏的数据预取。
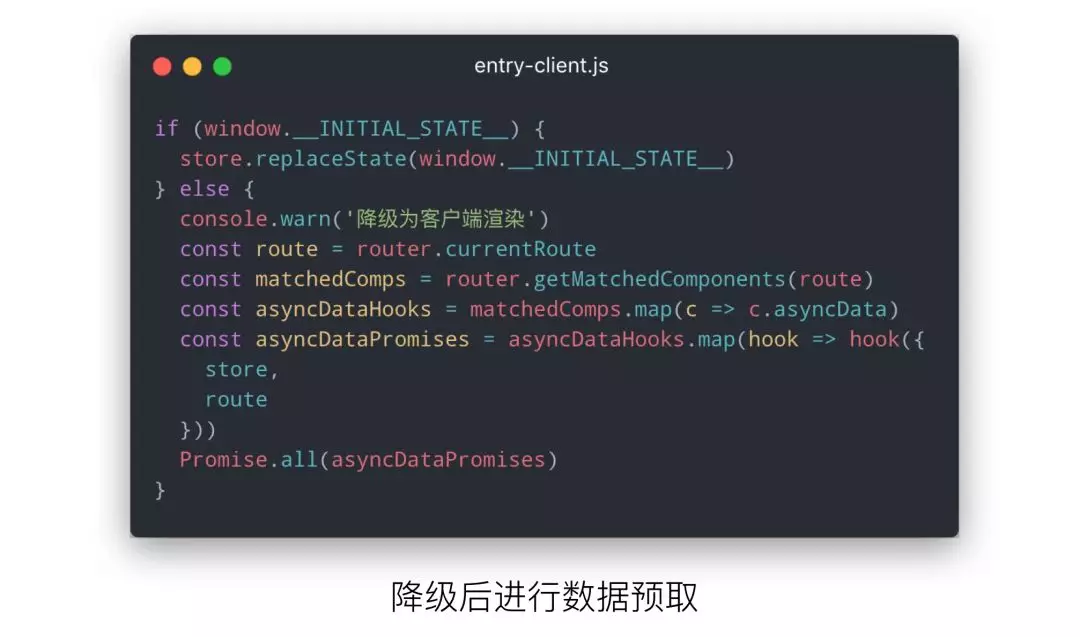
至此,降级的入口文件就完成了,接下来就是在 SSR 的流程中,我们在什么阶段将这个 SPA 文件返回给浏览器。
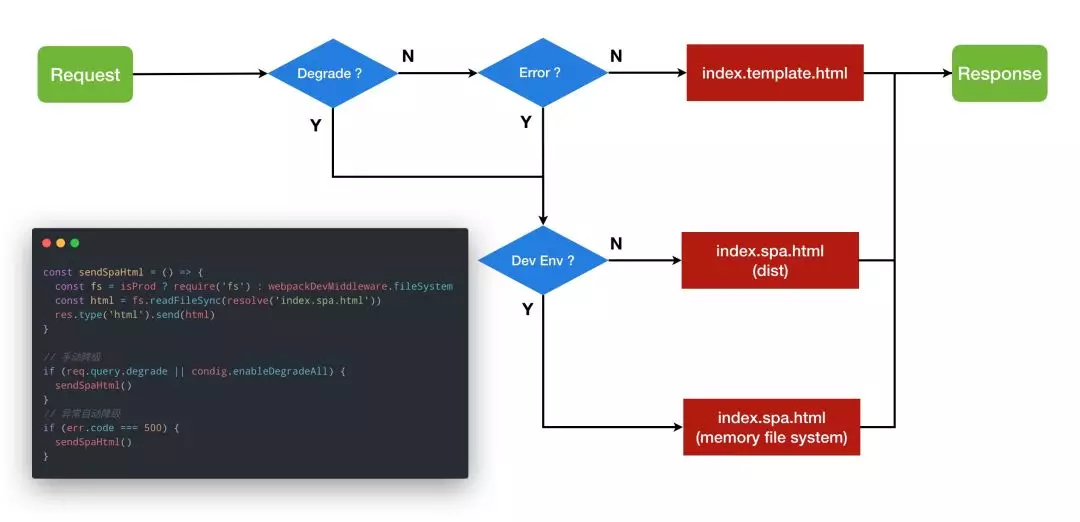
这边有一个流程图,当请求进来时,判断 URL 中是否有 Degrade 参数或者配置文件中有没有开启全局降级,如果有则进行降级,如果没有再看服务端渲染流程中有没有发生异常,发生异常也会进行降级。另外还要区分开发环境和正式环境对 SPA 应用的获取规则:开发环境下从内存中取,正式环境从磁盘中取,因为开发环境下用了 webpack-dev-middleware,是构建到内存中的。
到这里,整个降级机制的实现原理就介绍完了,有了这个机制,我们可以非常方便的让应用随时降级成单页,来观察接口的调用(开发、测试利器)。而且,如果服务端渲染出现异常,用户也不会看到一个冷冰冰的 500 页面了。另外,对于一些大流量的场景,也可以通过配置文件开启全局降级,让 SSR 应用直接变成一个 SPA 应用,减少服务器的负担。
服务端缓存
对于一些与用户无关的接口和页面,就是说不管是谁访问返回的结果都是相同的,对于这些接口我们可以使用 LRU-Cache (最近最少使用)做服务端缓存,更好的降低内容到达时间。
接入全链路追踪
我们将 SSR 应用接入到内部的全链路追踪系统中,在现代的微服务架构中,应用的调用链路是非常复杂的,而 Vue SSR 应用又是在调用链的最顶端,所以将 Node.js 接入这套全链路系统是非常有必要的。
内部框架沉淀
我们将这套 SSR 解决方案封装成一个内部框架、来更好的支持需求的迭代。出于框架可维护性、可升级性的考虑,我们将 Webpack 和 Server 部分都内置了进去,但同时也暴露了方法让用户做一些自定义的操作(webpack-chain、middleware 等)。
应用场景三:API 服务

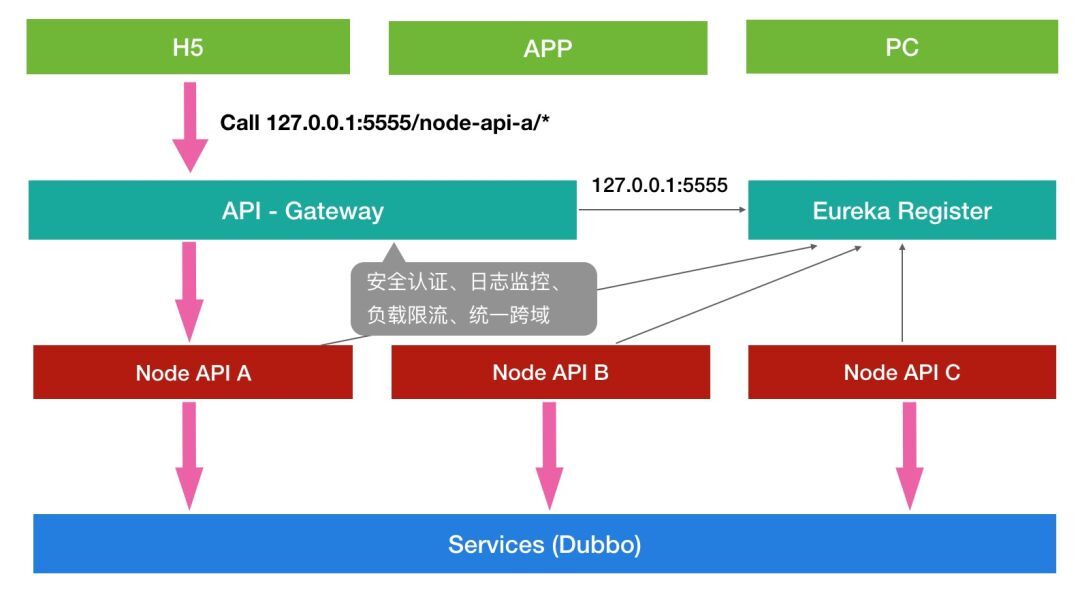
BFF 的概念在国内是阿里最先提出来的,主要是前端工程师维护的在端应用和底层服务中间的一层,用来针对不同的用户设备输出不同的接口,做一些数据的聚合、裁剪、适配等。在微医我们主要做了一些底层服务的调用,进行接口的聚合和转发,即 Node.js API 服务层。
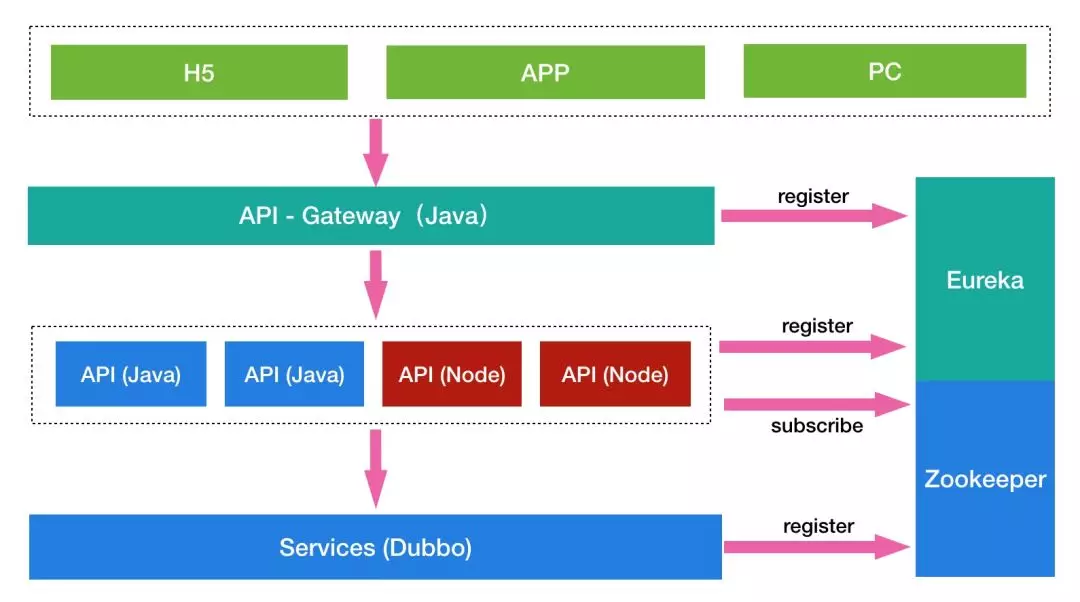
上面这张图展示了 Node.js 在整个微服务架构中的位置,最上层的是一些端应用,当一个请求发起时首先会经过 Java 的网关,网关作为微服务的唯一入口,进行请求的分发和通用逻辑的处理,网关下面是一些 API 服务,用来提供 HTTP 接口,最底层是更加原子化、细粒度的 Dubbo 服务。Eureka 是网关和 API 层的注册中心,Zookeeper 是 Dubbo 层的注册中心。Node.js 在 API 层主要做了以下工作。
Dubbo 服务调用
我们使用了社区提供的 dubbo2.js 进行 Dubbo 服务的调用,并且做了一些封装来优化发开体验。
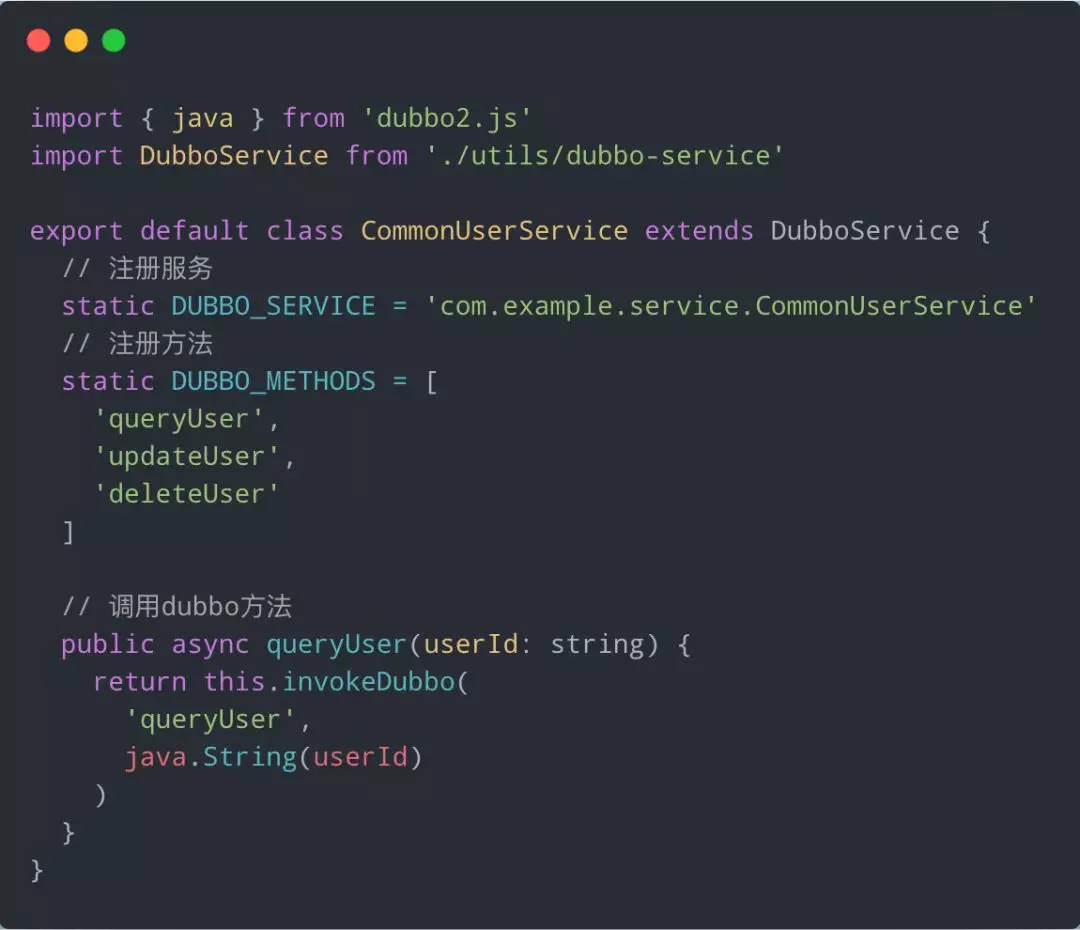
当然,官方还推荐 jar-to-ts 的方案,将 dubbo 服务的 JAR 包转成 TS 定义,来进行更方便的调用。
接入 Eureka 注册中心
如果想接入统一的 API 网关,首先得将我们的应用接入到 Eureka 注册中心中,使用社区提供的 eureka-js-client 这个库可以非常快速的进行 Eureka 的接入。
装饰器路由封装
我们的应用是基于 Egg.js 和 Typescript 的,但是我们发现 Egg.js 的映射式路由对开发体验有点不友好,所以我们做了装饰器路由的封装。
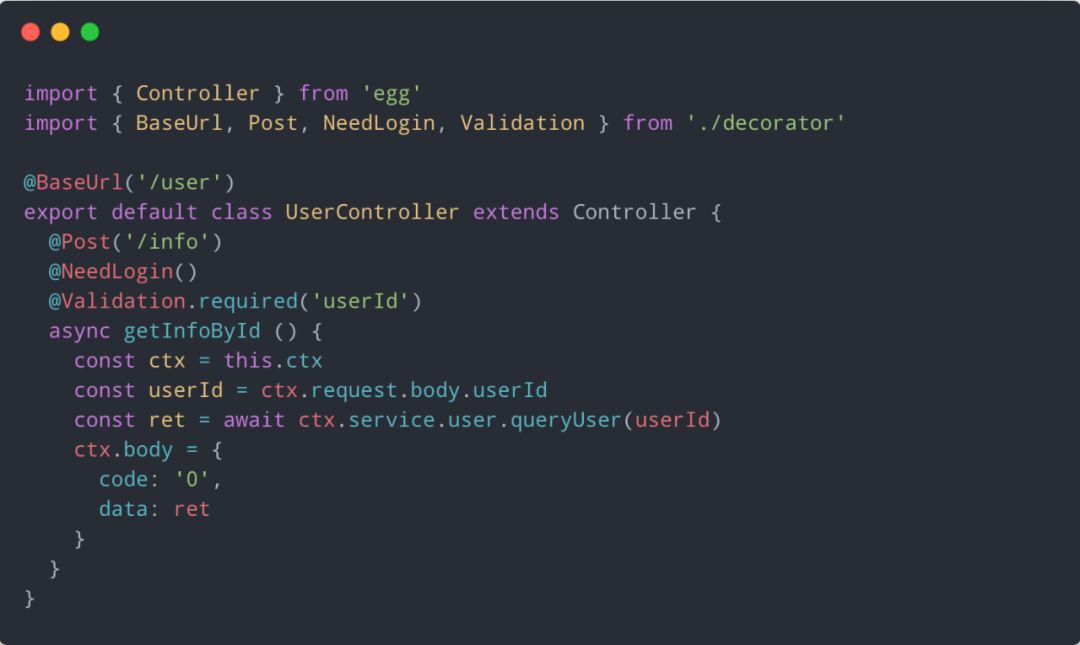
通过装饰器,我们不仅可以做一些路由的定义,还可以做一些前置逻辑的处理,比如请求头判空、权限校验、接口文档生成等等。
内部框架封装
Aug.js 是一个基于 Egg.js 基础框架,使用 TypeScript 开发的 Node.js 应用框架,集成了 Log、APM、Gtrace 以及 Eureka 等基础中间件,致力于打造通用的企业级 Node 应用解决方案。

Node.js 生态建设
其实我们在团队内 Node.js 的生态建设上面,还做了一些其他东西,下面我主要对全链路追踪和性能监控平台做一下介绍。
全链路追踪
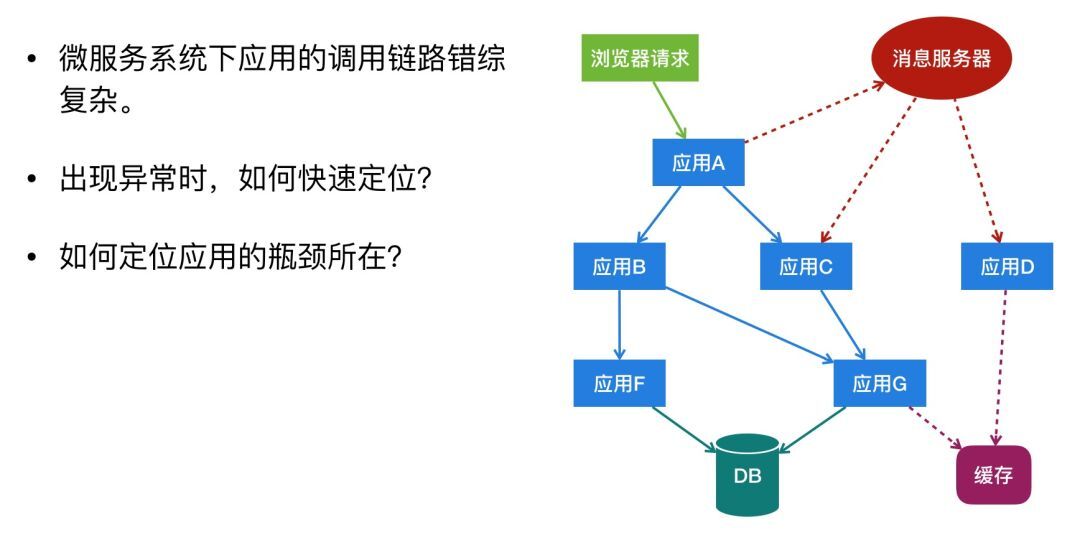
为什么需要全链路追踪系统
在现代化的微服务系统中,客户端的一次请求操作,可能需要经过系统中多个模块,如何确定客户端的一次操作背后调用了哪些应用,经过了哪些节点,先后顺序是怎样的?当出现 BUG 时,如何快速的定位问题出现在哪一环?还有每个应用的性能如何,耗时有多长,我们如何快速定位应用的瓶颈所在?
全链路追踪系统的原理
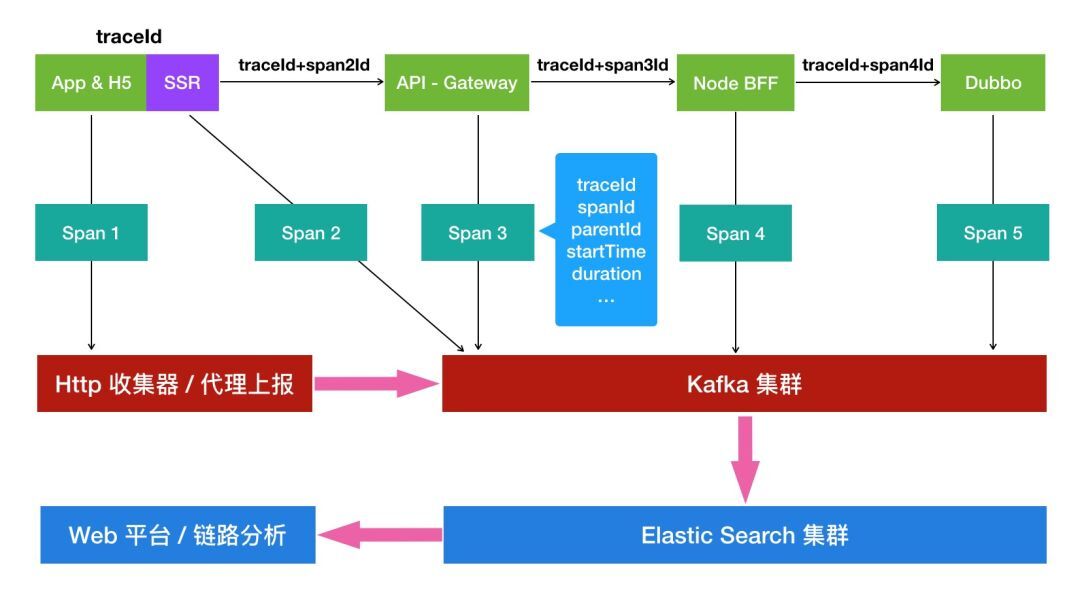
当一条请求进来的时候,会生成一个唯一的 TraceId,来标记一条链路,每当进行后续的调用时,都会将 TraceId 传下去,来串连起来整个链路。
Span 是一个上报单元,是一个原子化的操作,一个程序块的调用,或者一次 RPC/数据库访问都可以认为是一个 Span,每个 Span 都遵循一个固定的数据结构。
通过 TraceId 我们可以把每一次请求经过的系统收集起来:
每一层把 TraceId 传递下去(Http Header、Dubbo Attchment)。
每一层把 TraceId 上报上去。
通过 SpanId 和 ParentId 我们可以构建树的父子关系:
每一层把 SpanId 传递下去。
每一层在构建 Span 时,如果在请求头中有 SpanId 带过来,则标记 ParentId 为父级的 SpanId。
const spanId = generateUUID16()const spanCtx = { spanId }const parentSpanId = req.headers['span-id']const parentTraceId = = req.headers['trace-id']if (parentSpanId && parentTraceId) { spanCtx.traceId = parentTraceId spanCtx.parentId = parentSpanId spanCtx.reference = reference.CHILD_OF} else { const traceId = generateUUID32() spanCtx.traceId = traceId spanCtx.parentId = traceId.substr(-16)}通过 startTime 可以确定同级的先后顺序,startTime 标记生成这条 Span 的时间,同级节点 startTime 排序后的顺序就是节点展示的顺序。
Node.js 和 Java 层面都是通过 Kafka 生产者将数据上报到消息队列里面。客户端需要做特殊的处理,因为客户端的应用协议比较单一,一般是 HTTP,所以不支持消息队列上报,需要加一层代理层。ES 负责消费数据,进行链路的分析,最后由 Web 平台进行链路的展示。
其实除了最基本的链路分析,这套系统还可以做:慢调用分析、冷热应用、相互依赖、日志平台整合、监控中心整合等等。
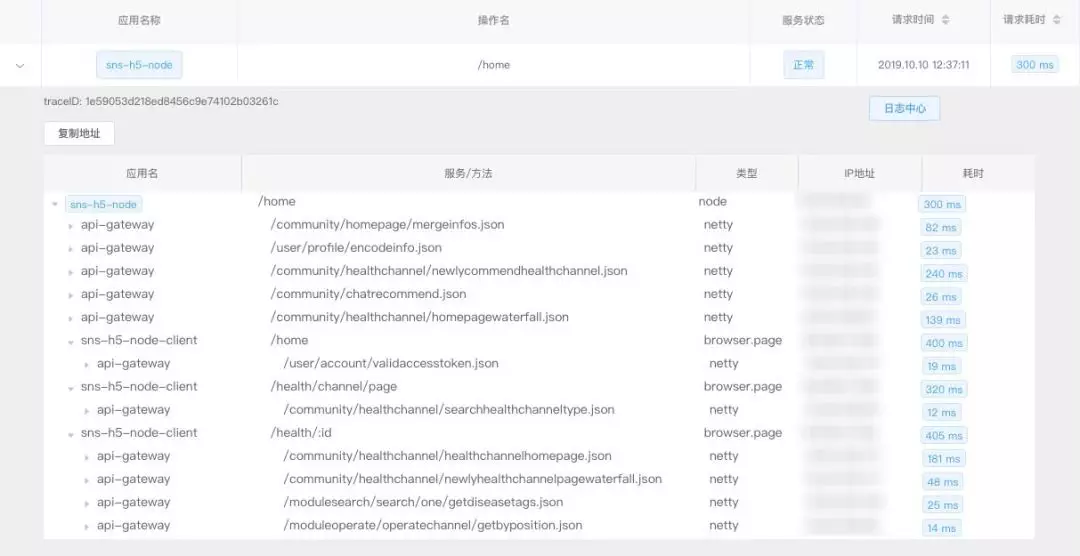
上面这张图是 Node.js 应用接入到这套链路追踪系统后的链路图,可以非常清晰的看到在服务端调用了哪些接口,甚至配合 Browser 端的 SDK 可以将 SSR 应用的链路链接起来,进行用户页面访问路径、内容到达时间、页面性能的分析。
性能监控平台
我们对比了常用的 APM 产品,从代码侵入、实现方式、成熟度、数据安全性以及性能等各个方面进行对比。

我们想要的是一个可以在公司内部部署、侵入低、基础监控完备的 APM 产品,最终我们选择了 Elastic APM 方案。
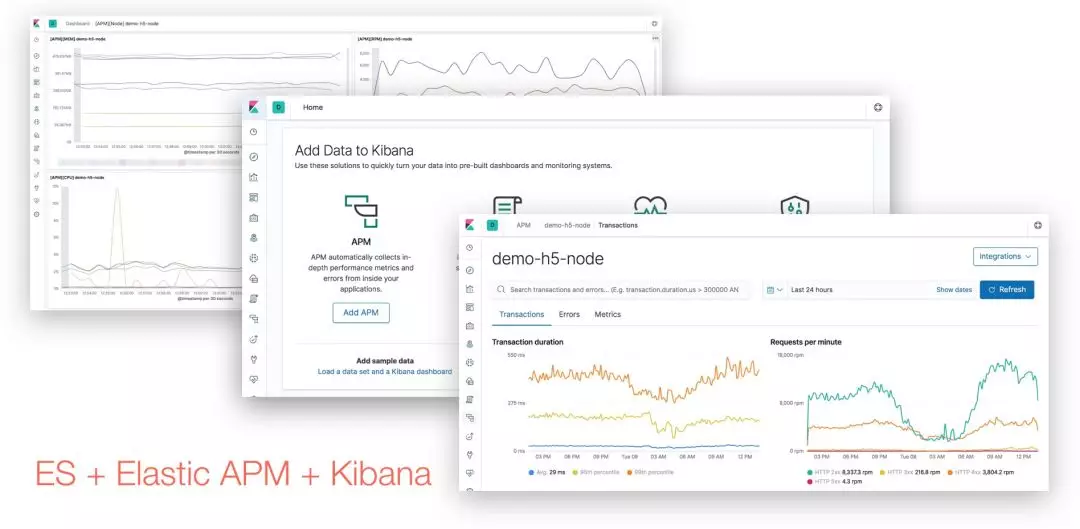
这套性能监控方案可以满足我们目前的需求,如果需要更深入监控及分析,还可以进行二次开发。
总结

今天给大家介绍了 Node.js 在微医的应用探索及沉淀的情况,可以看到:
Node.js 是一个效率利器,有了 Node.js 的帮助,前端工程师可以好的将想法变成产品。
不管是 SSR 应用的容错降级、全链路追踪还是性能监控,可以看到,对于线上应用来说稳定性保障设施是必不可少的。
最后,重要的话要说三遍:不要重复造轮子!不要重复造轮子!不要重复造轮子!
头图:Unsplash
作者:高翔
原文:https://mp.weixin.qq.com/s/GHC3a6RBSdNiHg7rKLOV2g
原文:Node.js 在微医的应用场景及实践
来源:微医大前端技术 - 微信公众号 [ID:wed_fed]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




