
1 月 16 日,InfoQ 获悉,经过了半个月的部分客户的内测和反馈,MiniMax 全量发布大语言模型 abab6,该模型为国内首个 MoE(Mixture-of-Experts)大语言模型。
早在上个月举办的数字中国论坛成立大会暨数字化发展论坛的一场分论坛上,MiniMax 副总裁魏伟就曾透露将于近期发布国内首个基于 MoE 架构的大模型,对标 OpenAI GPT-4。
在 MoE 结构下,abab6 拥有大参数带来的处理复杂任务的能力,同时模型在单位时间内能够训练足够多的数据,计算效率也可以得到大幅提升。改进了 abab5.5 在处理更复杂、对模型输出有更精细要求场景中出现的问题。
为什么选择 MoE 架构?
那么,MoE 到底是什么?MiniMax 的大模型为何要使用使用 MoE 架构?
MoE 架构全称专家混合(Mixture-of-Experts),是一种集成方法,其中整个问题被分为多个子任务,并将针对每个子任务训练一组专家。MoE 模型将覆盖不同学习者(专家)的不同输入数据。
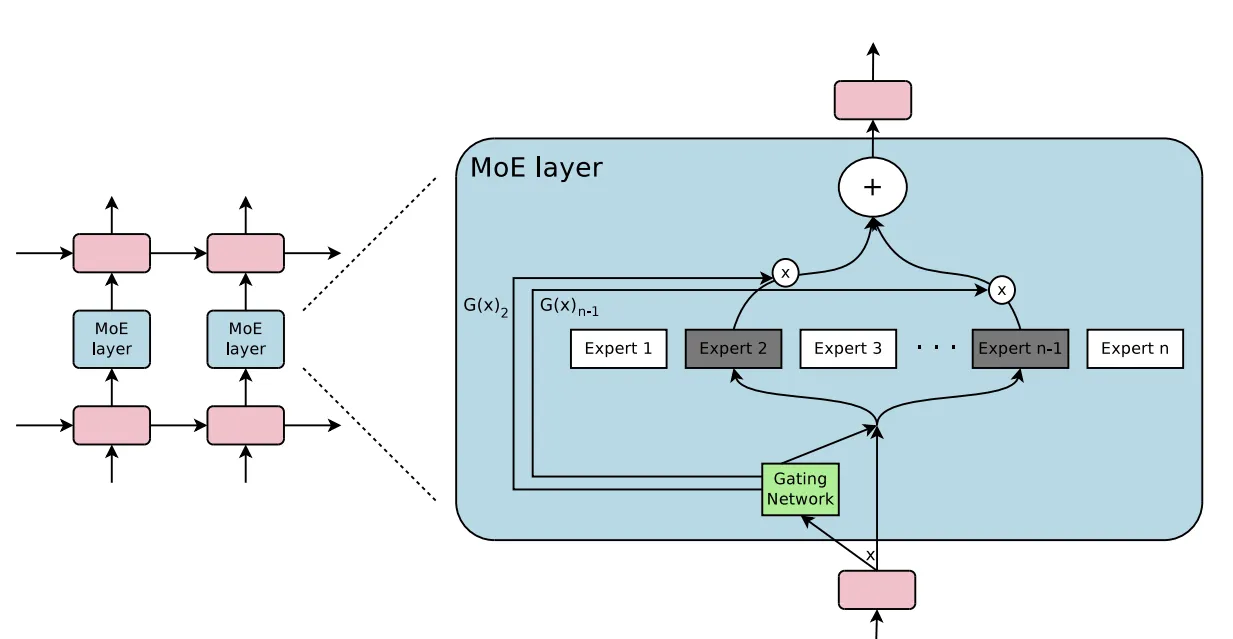
图片来源:https ://arxiv.org/pdf/1701.06538.pdf
有传闻称,GPT-4 也采用了相同的架构方案。
2023 年 4 月,MiniMax 发布了开放平台。过去半年多,MiniMax 陆续服务了近千家客户,包括金山办公、小红书、腾讯、小米和阅文在内的多家头部互联网公司,MiniMax 开放平台平均单日的 token 处理量达到了数百亿。
MiniMax 在官微中发文称:“这半年多来,客户给我们提供了很多有价值的反馈和建议。例如,大家认为我们做得比较好的地方有:在写作、聊天、问答等场景中,abab5.5 的表现不错,达到了 GPT-3.5 的水平。”
但是和最先进的模型 GPT-4 相比,仍有明显差距。这主要体现在处理更复杂的、对模型输出有精细要求的场景时,存在一定概率违反用户要求的输出格式,或是在推理过程中发生错误。当然,这不仅是 abab5.5 的问题,也是目前除 GPT-4 以外,几乎所有大语言模型存在的缺陷。
为了解决这个问题,进一步提升模型在复杂任务下的效果,MiniMax 技术团队从去年 6 月份起开始研发 MoE 模型——abab6 是 MiniMax 的第二版 MoE 大模型(第一版 MoE 大模型已应用于其 C 端产品中)。
虽然 MiniMax 并未透露 Abab6 的具体参数,但据 MiniMax 透露,Abab6 比上一个版本大了一个量级。更大的模型意味着 abab6 可以更好的从训练语料中学到更精细的规律,完成更复杂的任务。
但仅扩大参数量会带来新的问题:降低模型的推理速度以及更慢的训练时间。在很多应用场景中,训练推理速度和模型效果同样重要。为了保证 abab6 的运算速度,MiniMax 技术团队使用了 MoE (Mixture of Experts 混合专家模型)结构。在该结构下,模型参数被划分为多组“专家”,每次推理时只有一部分专家参与计算。基于 MoE 结构,abab6 可以具备大参数带来的处理复杂任务的能力;计算效率也会得到提升,模型在单位时间内能够训练足够多的数据。
目前大部分大语言模型开源和学术工作都没有使用 MoE 架构。为了训练 abab6,MiniMax 还自研了高效的 MoE 训练和推理框架,也发明了一些 MoE 模型的训练技巧。到目前为止,abab6 是国内第一个千亿参数量以上的基于 MoE 架构的大语言模型。
测评结果
为了对比各模型在复杂场景下的表现,MiniMax 对 abab6、abab5.5、GPT-3.5、GPT-4、Claude 2.1 和 Mistral-Medium 商用进行了自动评测。在简单的任务上,abab5.5 已经做得比较好,因此 MiniMax 选择了三种涵盖了较复杂的问题的评测方法:
IFEval:这个评测主要测试模型遵守用户指令的能力。在测试时,提问者会问模型一些带有约束条件的问题,例如“以 XX 为标题,列出三个具体对方法,每个方法的描述不超过两句话”,然后统计有多少回答严格满足了约束条件。
MT-Bench:这个评测衡量模型的英文综合能力。提问者会问模型多个类别的问题,包括角色扮演、写作、信息提取、推理、数学、代码、知识问答。MiniMax 技术团队会用另一个大模型(GPT-4)对模型的回答打分,并统计平均分。
AlignBench:该评测反映了模型的中文综合能力测试,测试形式与 MT-Bench 类似。
测评及对比结果如下:

注:对比模型均选择各自最新、效果最好的版本,分别为 Claude-2.1、Mistral-Medium 商用、GPT-3.5-Turbo-0613、GPT-4-1106-preview;GPT-3.5-Turbo-0613 略好于 GPT-3.5-Turbo-1106 。abab6 是 1 月 15 号的版本。
可以看出,abab6 在三个测试集中均明显好于前一代模型 abab5.5。在指令遵从、中文综合能力和英文综合能力上,abab6 大幅超过了 GPT-3.5。和 Claude 2.1 相比,abab6 也在指令遵从、中文综合能力和英文综合能力上略胜一筹。相较于 Mistral 的商用版本 Mistral-Medium,abab6 在指令遵从和中文综合能力上都优于 Mistral-Medium,在英文综合能力上与 Mistral- Medium 旗鼓相当。
如果想体验 MiniMax MoE 大模型,可访问 MiniMax 开放平台官网:api.minimax.chat
ps:MiniMax 方面称,模型还在持续训练中,远没有收敛,欢迎大家反馈。




