
整理 | 华卫
1 月 28 日,智源多模态大模型成果"Multimodal learning with next-token prediction for large multimodal models(通过预测下一个词元进行多模态学习的多模态大模型)"上线国际顶级学术期刊 Nature,预计 2 月 12 日纸质版正式刊发。
Nature 编辑点评这项研究:Emu3 仅基于预测下一个词元(Next-token prediction),实现了大规模文本、图像和视频的统一学习,其在生成与感知任务上的性能可与使用专门路线相当,这一成果对构建可扩展、统一的多模态智能系统具有重要意义。

https://www.nature.com/articles/s41586-025-10041-x
2018 年以来,GPT 采用 “预测下一个词元(Next-token prediction,NTP)”的自回归路线,实现了语言大模型重大突破,开启了生成式人工智能浪潮。而多模态模型主要依赖对比学习、扩散模型等专门路线,自回归路线是否可以作为通用路线统一多模态?一直是未解之谜。
智源这项成果表明,只采用自回归路线,就可以统一多模态学习,训练出优秀的原生多模态大模型,对于确立自回归成为生成式人工智能统一路线具有重大意义。在后续迭代的 Emu3.5 版本,确实证明了这一范式的可拓展性,并达成预测下一个状态(Next-state prediction)的能力跃迁,获得可泛化的世界建模能力。
从语言到多模态:“预测下一个词元”的潜力与未解之问
“预测下一个词元”彻底改变了语言模型,促成了如 ChatGPT 等突破性成果,并引发了关于通用人工智能(AGI)早期迹象的讨论。然而,其在多模态学习中的潜力一直不甚明朗。
在多模态模型领域,视觉生成长期以来由结构复杂的扩散模型主导,而视觉语言感知则主要由组合式方法引领 ,这些方法通常将 CLIP 编码器与大语言模型(LLMs)结合。尽管已有一些尝试试图统一生成与感知(如 Emu 和 Chameleon),但这些工作要么简单将 LLM 与扩散模型拼接在一起,要么在性能效果上不及那些针对生成或感知任务精心设计的专用方法。这就留下了一个根本性的科学问题:单一的预测下一个词元框架是否能够作为通用的多模态学习范式?
就此,智源提出了 Emu3,基于“预测下一个词元”的全新多模态模型,将图像、文本和视频统一离散化到同一个表示空间中,并从零开始,在多模态序列混合数据上联合训练一个单一的 Transformer。这一架构证明了仅凭“预测下一个词元”,就能够同时支持高水平的生成能力与理解能力,并且在同一统一架构下,自然地扩展到机器人操作以及多模态交错等生成任务。此外,研究团队还做了大量消融实验和分析,验证了多模态学习的规模定律(Scaling law)、统一离散化的高效性、以及解码器架构的有效性。
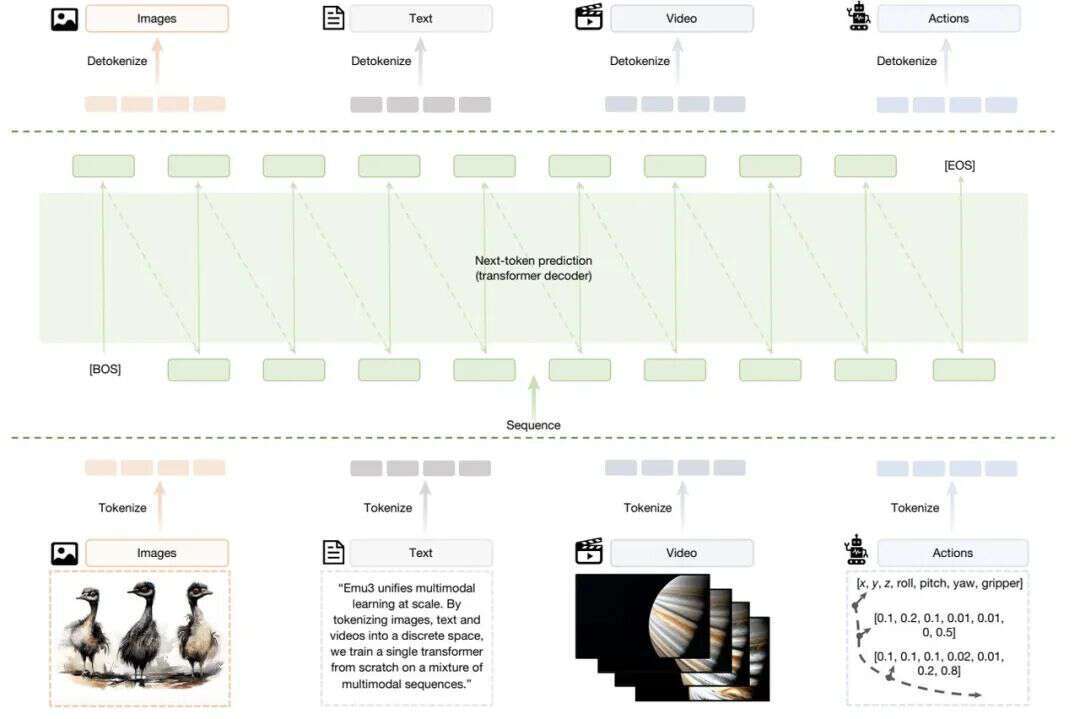
Emu3 架构图
实验显示,Emu3 在生成与感知任务上的整体表现可与多种成熟的任务专用模型相媲美:在文生图任务中,其效果达到扩散模型水平;在视觉语言理解方面,可以与融合 CLIP 和大语言模型的主流方案比肩。此外,Emu3 还具备视频生成能力。不同于以噪声为起点的扩散式视频生成模型,Emu3 通过自回归方式逐词元(token)预测视频序列,实现基于因果的视频生成与延展,展现出对物理世界中环境、人类与动物行为的初步模拟能力。
从模型到范式:Emu3 对多模态学习的启示
不同于 Sora 的扩散式视频生成,Emu3 采用纯自回归方式逐词元(token) 生成视频,能够在给定上下文下进行视频延展与未来预测,并在文本引导下生成高保真视频。此外,Emu3 还可拓展至视觉语言交错生成,例如图文并茂的菜谱生成;也可拓展至视觉语言动作建模,如机器人操作 VLA 等,进一步体现了“预测下一个词元”的通用性。
智源研究团队对相关研究的多项关键技术与模型进行了开源,以推动该方向的持续研究。其中包括一个稳定且通用的视觉分词器(tokenizer),可将图像与视频高效转换为离散词元来表示。同时,研究通过大规模消融实验系统分析了多项关键技术的设计选择,例如:分词器(tokenizer)码本尺寸、初始化策略、多模态 dropout 机制以及损失权重配置等,揭示了多模态自回归模型在训练过程中的动态特性。研究还验证了自回归路线高度通用性:直接偏好优化(DPO)方法可无缝应用于自回归视觉生成任务,使模型能够更好地对齐人类偏好。
研究有力表明了预测下一个词元可作为多模态模型的核心范式,突破语言模型的边界,在多种多模态任务中展现了强劲性能。通过简化复杂的模型设计、聚焦统一词元,该方法在训练与推理阶段均展现出显著的可扩展性,为统一多模态学习奠定了坚实基础,有望推动原生多模态助手、世界模型以及具身智能等方向的发展。
在此研究基础上,悟界·Emu3.5 进一步通过大规模长时序视频训练,学习时空与因果关系,展现出随模型与数据规模增长而提升的物理世界建模能力,并观察到多模态能力随规模扩展而涌现的趋势,实现了“预测下一个状态”的范式升级。




