
谷歌发布了 Aletheia,这是一套基于 Gemini 3 Deep Think 的 AI 系统,在 FirstProof 挑战中成功解决了 10 道全新数学问题中的 6 道。与此同时,Aletheia 在 IMO-ProofBench 上取得了约 91.9% 的成绩,这表明在无需人工干预的研究级证明自动发现方面出现了显著进展。
与传统基准测试常见的数据污染问题(即模型无意中记住训练数据)不同,FirstProof 挑战包含了十个尚未发表的研究级数学引理。这些问题来源于数学家正在进行的研究工作,从未在网上发布,因此几乎可以确定 AI 不可能提前见过这些题目。此外,参赛者仅有一周时间提交解答。
在仅提供原始问题描述、没有任何人工提示或交互循环的情况下,Aletheia 完全自主地生成了候选证明。由人类专家组成的评审团队认为,其中 10 个解答中的 6 个“经过少量修改即可发表”。值得注意的是,第 8 题的解答获得了 7 位专家中 5 位的认可为正确,其余专家则指出缺少一些必要的澄清细节。更关键的是,对于剩余的 4 道问题,Aletheia 明确输出“未找到解”或因超时未给出结果,而不是生成看似合理但存在缺陷的错误答案。DeepMind 研究人员对此表示:
这种自我过滤能力是 Aletheia 的关键设计原则之一;我们认为,在将 AI 扩展应用于研究级数学时,可靠性是主要瓶颈。我们推测……许多在一线工作的研究者更愿意用更高的准确性来换取一定程度的问题求解能力。
OpenAI 也使用一款尚未发布的内部推理模型参与了该挑战。最初他们报告称解决了 10 道问题中的 6 道(具体为第 2、4、5、6、9 和 10 题),但随后在发现第 2 题的解答存在逻辑缺陷后,将结果下调为 5 道。与 DeepMind 严格的零样本自动化不同,OpenAI 承认在过程中依赖了有限的人类监督,用于从多次尝试中手动评估并筛选最佳结果。
在底层实现上,Aletheia 基于 Gemini 3 Deep Think 架构,并依赖扩展的“测试时计算”(即推理阶段的计算资源)。系统采用多代理框架,包括用于提出逻辑步骤的 Generator、用于检测步骤缺陷的 Verifier,以及用于迭代修正错误的 Reviser。通过整合如谷歌搜索等外部工具,该代理能够检索现有文献以验证相关概念,从而降低大语言模型常见的无依据引用问题。
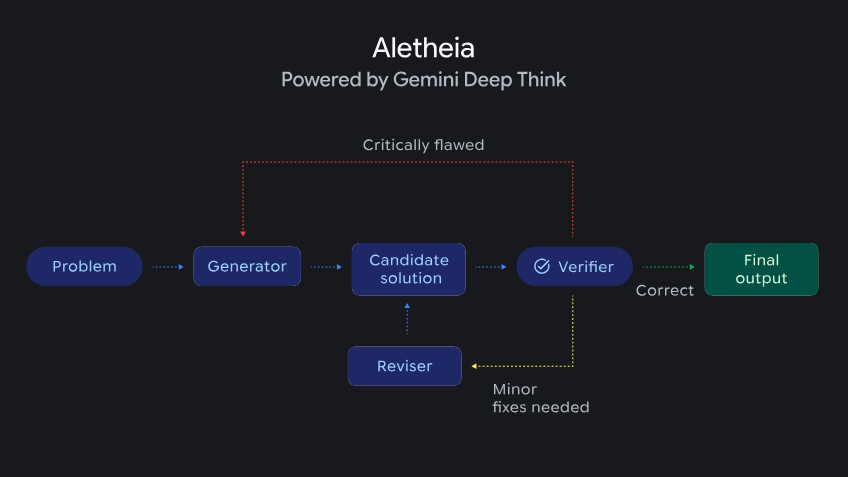
Aletheia:基于 Gemini Deep Think,展示多步骤解答验证流程。(来源:谷歌 DeepMind 博客)
正如 Luhui Dev 在一篇深度分析中所指出,Aletheia 本质上类似一个严格且可执行的研究循环,可以类比为数学领域的 CI/CD 流水线:提出、验证、失败、修复、合并。在这一过程中,大语言模型充当具有创造力的候选生成器,而第二个代理则类似同行评审者,推动问题修复。
不过,研究人员在论文《Towards Autonomous Mathematics Research(迈向自主化数学研究)》中也指出,尽管短短数月内已经取得显著进展,但完全自主化仍未实现:
即便引入了验证机制,Aletheia 在出错率上仍高于人类专家。此外,只要问题存在一定歧义,模型往往倾向于将其理解为更容易回答的形式……这与机器学习中众所周知的‘规格博弈(specification gaming)’和‘奖励劫持(reward hacking)’现象是一致的。
该项目背后的数学家团队已经在推进第二版系统。下一批问题将在 2026 年 3 月至 6 月期间设计、测试并评估,并计划构建为一个完全形式化的基准测试体系。
Aletheia 由 Gemini Deep Think 的高级版本提供支持。




