
Netflix 的工程师Vidhya Arvind和Shawn Liu在旧金山 QCon 会议上介绍了他们为集中式数据删除平台设计的架构,该平台解决了一个非常关键但较少讨论的系统设计挑战。平台在管理跨异构数据存储的删除操作时,同时平衡了持久性、可用性和正确性。迄今为止,它已经处理了 1300 个数据集中的 768 亿行删除操作,没有发生任何数据丢失事件。
分布式系统中的数据删除面临的挑战远远超出了简单的数据库操作。工程师们面临一个基本的困境:对意外破坏关键信息的恐惧使团队变得非常谨慎,但未能删除数据可能会使他们面临GDPR等法规的法律风险,同时会增加存储成本,并侵蚀客户信任。演讲者强调,“删除不能是事后才有的想法”。Netflix 平台的一个主要驱动力是管理频繁的端到端生产测试产生的测试数据。这些测试验证了系统功能,但在系统中留下了大量的“垃圾”数据。
当数据跨越多个存储引擎并且这些这些引擎具有不同的删除特征时,复杂性会进一步加深。Cassandra使用背景压缩(background compaction),这涉及到 CPU 成本和潜在的峰值;Elasticsearch依赖于最终的段合并,这会带来高资源使用的影响;而Redis使用延迟或主动过期。即使是高效的删除操作也可能导致后台资源的峰值,这可能会影响系统稳定性。该平台还解决了数据复活问题,即由于配置错误、节点长时间停机或同步问题,已删除的数据可能会重新出现——演讲者称之为“机器中的幽灵”。
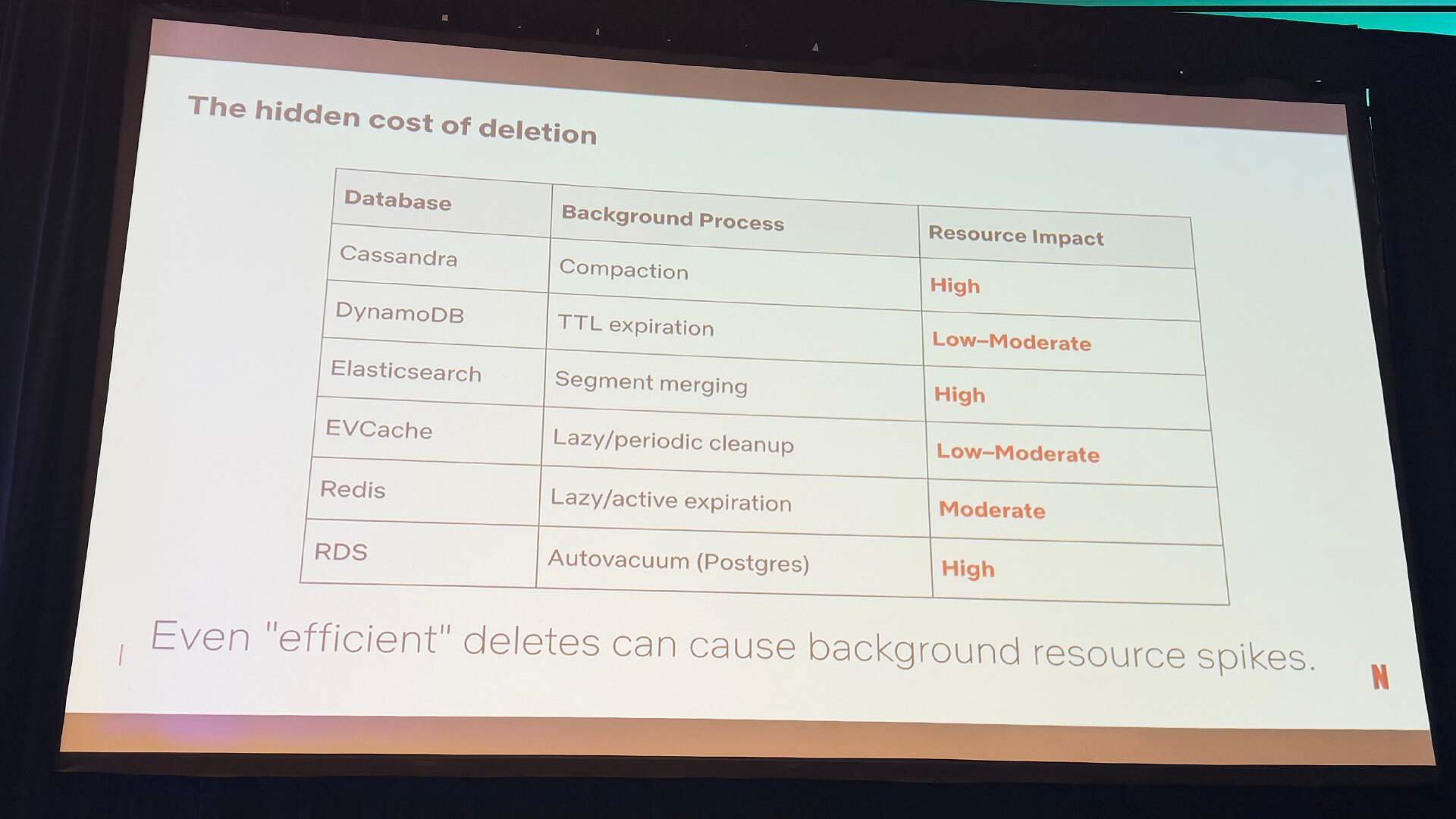
删除的隐形成本
Netflix 的解决方案围绕三个基础支柱构建。持久性确保数据最终会通过精细管理在分布式系统中传播的副本来删除。可用性通过将删除操作视为低优先级请求,并使用异步处理,从而优先考虑实时流量,保持系统运行。正确性确保即使在竞争条件存在的情况下也能准确删除。
平台架构集成了多个组件。控制平面触发工作流程,审计 job 在系统间识别可删除的数据,校验 job 验证标记的数据,删除服务协调删除操作。日志和恢复服务通过时间戳维护删除历史,使数据能够在 30 天内恢复,同时保持数据的完整性。
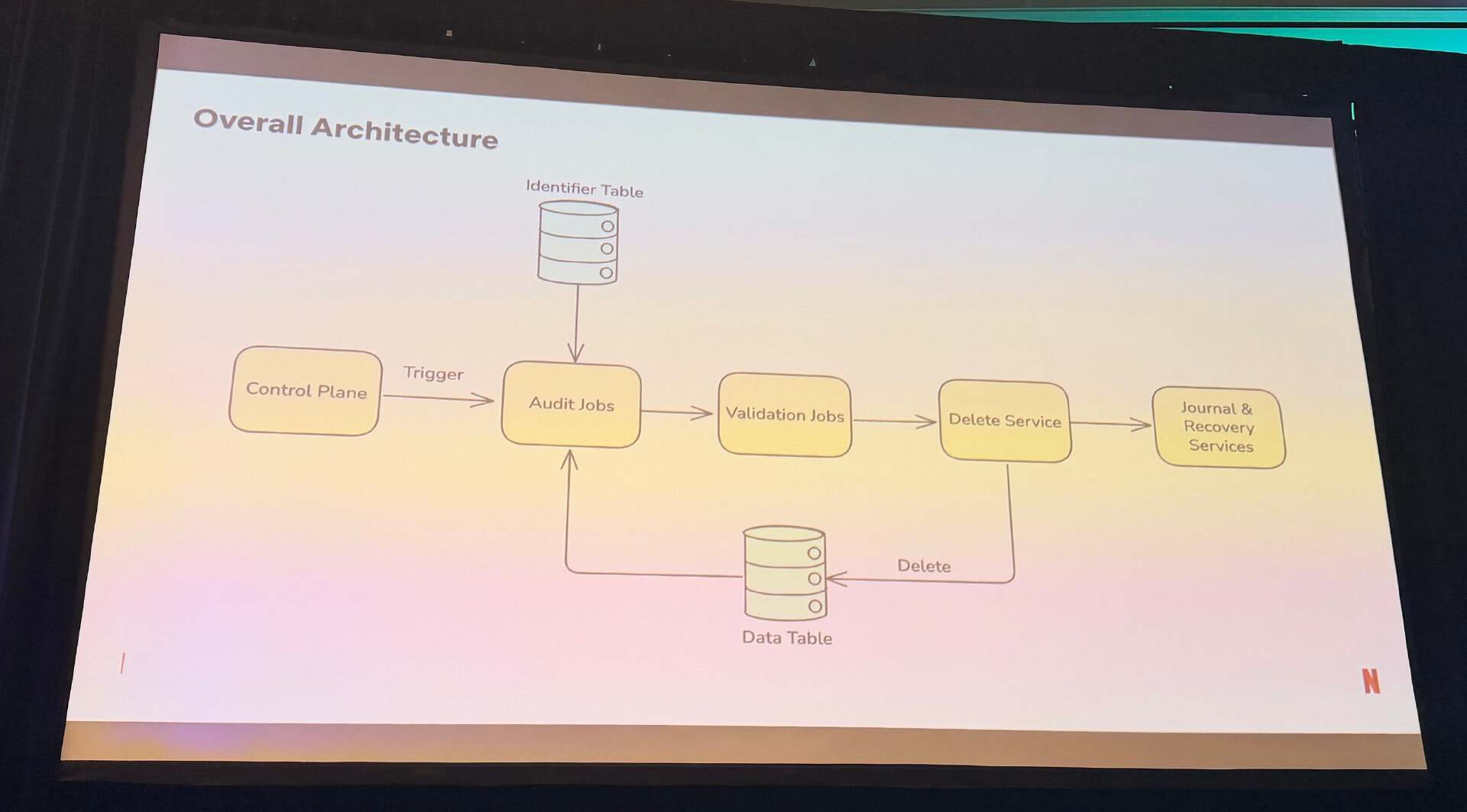
Netflix 数据删除平台的整体架构
为了在批量删除期间保持韧性,Netflix 实现了多个安全措施。背压(backpressure)机制使用资源的占用指标来确定删除速度,随着数据库负载的增加而减慢操作。速率限制会从每秒低请求开始,随着安全容量的允许而逐渐增加,并使用压缩指标来实现限流操作。指数退避能够防止在故障期间对集群的强力冲击。
全面的监控会通过关键指标跟踪删除操作的健康信息,包括可删除记录计数、最大保留超限以及成功与失败删除的比率。集中式的仪表盘能够提供可见性,因此团队相信平台能够正确处理他们的数据。最终结果证明了该平台的有效性:1300 个处于管理状态的数据集,零数据丢失,总删除 768 亿行数据,启用 125 个审计配置,每日删除记录数超过 300 万。
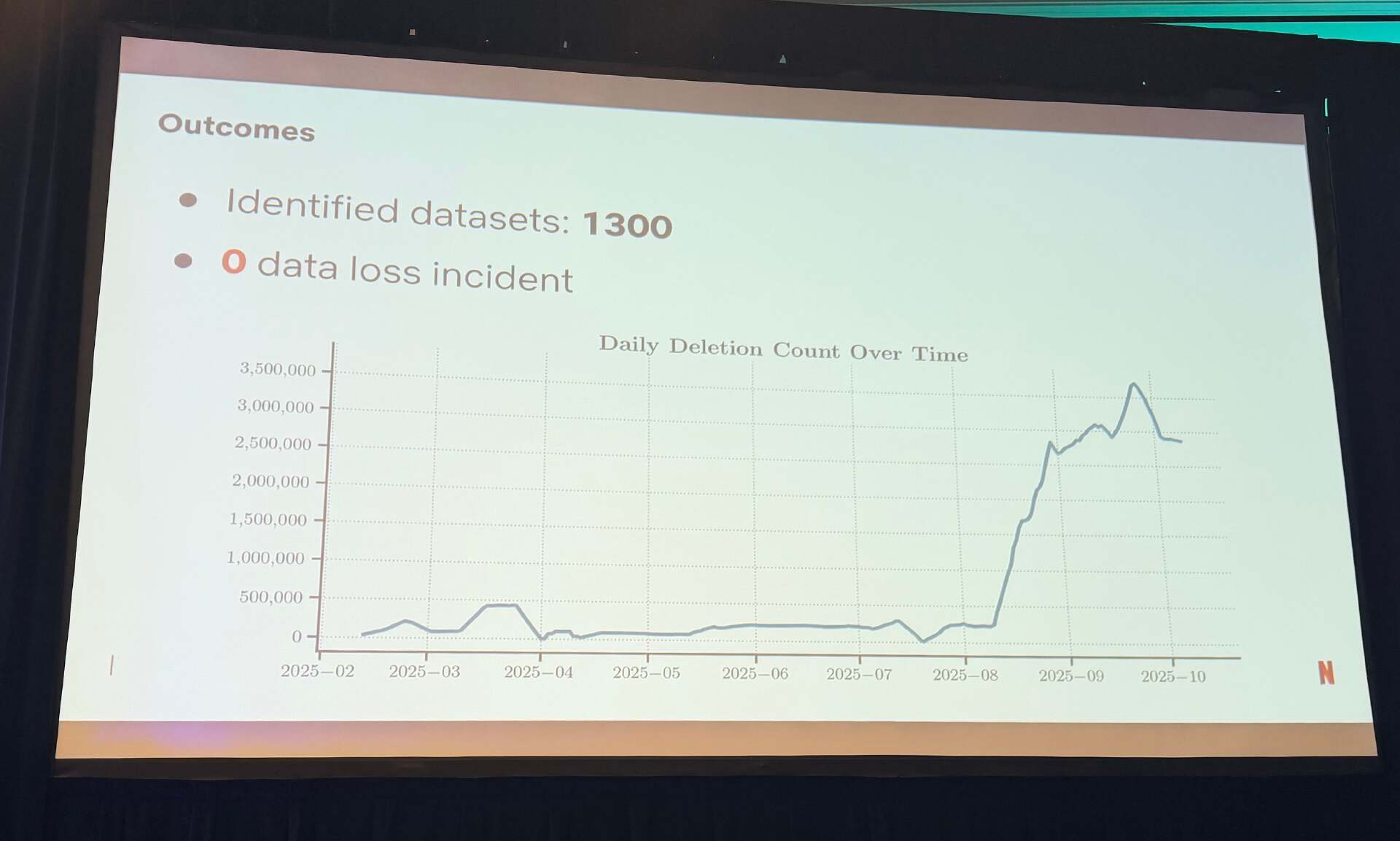
Netflix 数据删除平台:输出和每日删除的数据行计数
Netflix 的关键建议包括持续审计删除失败,构建集中式平台而不是分散的解决方案,深入理解存储引擎的细节,并积极应用韧性技术,包括扩展 TTL、资源利用监控、速率限制和高优先负载的减载。最重要的是,组织必须通过严格的验证、集中的可见性和展示可靠的数据处理来建立信任。
该平台展示了如何将删除视为第一等的架构关注点,这需要专用的基础设施,而不是运维的事后想法。演讲者分享了这个系统是如何从一个令人沮丧的生产事件中出现的,也就是一个错误的命令在深夜部署期间触发了连锁数据丢失,给工程师们带来了巨大的压力和内疚感。演讲者指出,“我们核心决策是确保这样的危机永远不会重演”。
原文链接:
Netflix Tackles Data Deletion at Scale with Centralized Platform Architecture




