
在当今以闭源模型为主导、各大科技公司严格保护核心 AI 技术的环境下,一个开源项目能够真正挑战行业顶尖产品实属罕见。
然而,DeepSeek 前段时间更新的最新版本 DeepSeek-R1(0528)不仅做到了这一点,甚至在某些关键领域超越了 Claude Opus 4 和 GPT-4.1 这样的顶级商业模型。
真正引起开发者社区关注的是 R1(0528)在大模型公共基准测试平台 LMArena 上的性能排名超越了多个顶尖封闭模型。
R1 编码能力超过 Claude Opus 4
在 WebDev Arena 中,DeepSeek-R1(0528)的性能表现与 Gemini-2.5-Pro-Preview-06-05、Claude Opus 4 (20250514) 等闭源大模型并列第一,更让人惊讶的是,R1(0528)得分为 1408.84 分,在分数上已经超过了得分为 1405.51 的 Claude Opus 4。
WebDev Arena 是由 LMArena 开发的实时 AI 编程竞赛平台,专注于 Web 开发挑战,让不同 AI 模型同台竞技、一较高下。
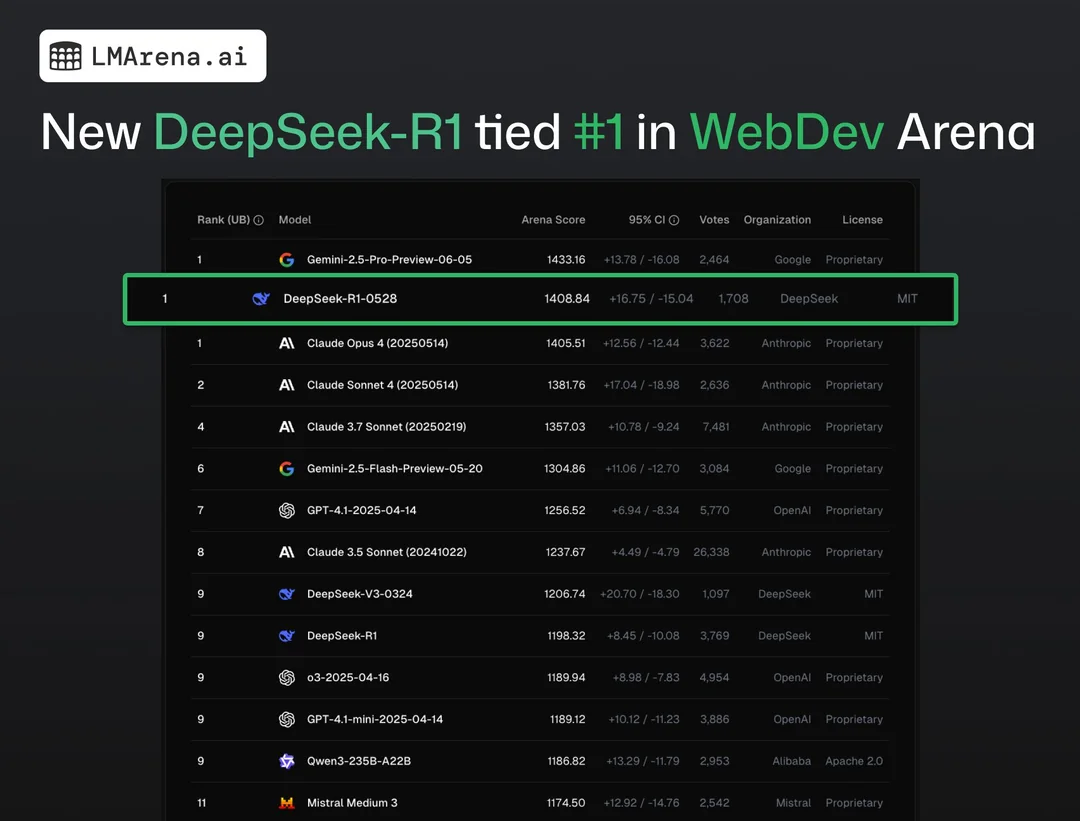
想想 Claude Opus 4 背后的资源。Anthropic 已经筹集了数亿美元,聘请了全球最优秀的 AI 研究人员,并拥有海量的计算资源。然而,由一个规模相对较小的团队开发的 DeepSeek 却拥有与之完全匹配的性能。
这样的成就的确令人惊叹。因为要想在 WebDev Arena 测试中取得高分并不是件容易事。
WebDev Arena 测试的不仅仅是基本的编码能力。它向这些模型提出了复杂、多步骤的开发挑战。例如构建交互式组件、调试复杂的 JavaScript 问题、处理 CSS 边缘情况。这些挑战将实际的开发能力与简单的代码生成区分开来。
除了编码之外,DeepSeek-R1(0528)在文本竞技场中排名第六。现在,文本竞技场的挑战性变得更高,因为它测试广泛的语言理解、推理和复杂任务的处理能力。
Text Arena 的测试也相对复杂。Text Arena 测试旨在揭示模型的弱点。这类挑战设置得细致入微、层次丰富,模型有时候会在这些挑战中暴露出“幻觉”,甚至出现一本正经胡说八道的现象。
Text Arena 测试结果显示 DeepSeek 能在文本能力上与 GPT-4o、Claude Opus 以及其他由巨额企业研究预算支持的模型展开直接竞争。
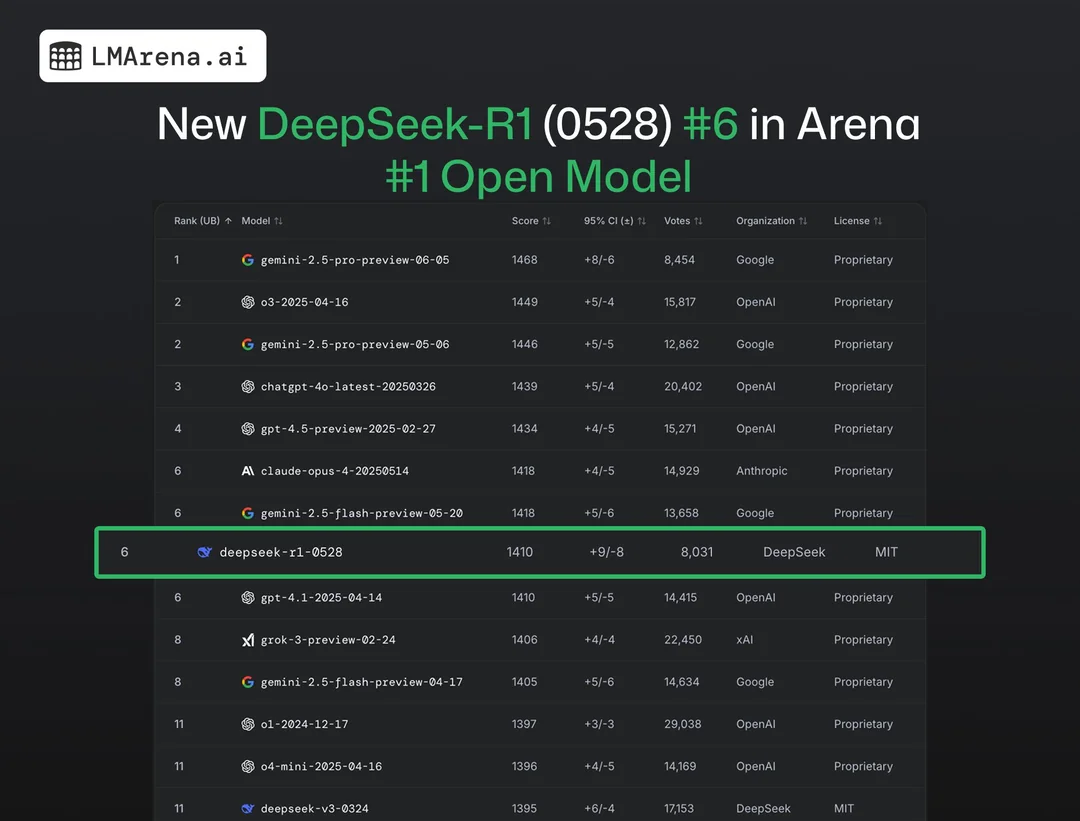
在其他细分领域的测试中,DeepSeek-R1(0528)表现怎样?具体测试结果如下:
在硬提示词(Hard Prompt)测试中排名第 4
在编程(Coding)测试中排名第 2
在数学(Math)测试中排名第 5
在创意性写作(Creative Writing)测试中排名第 6
在指令遵循(Intruction Fellowing)测试中排名第 9
在更长查询(Longer Query)测试中排名第 8
在多轮(Multi-Turn)测试中排名第 7

社区:堪称开源界里程碑时刻
2025 年 5 月 28 日,DeepSeek 发布了 R1(0528)(或称 R1.2),这是其开源大语言模型 DeepSeek R1 系列的最新升级版本。尽管官方将其定位为“小版本更新”,但实际测试表明,DeepSeek-R1(0528) 在推理深度、代码能力及整体稳定性上都有很大的提升。
它还是沿用了初代 R1 的混合专家(MoE)架构,总参数量高达 6850 亿,但每次推理仅激活约 370 亿参数,确保高效计算。同时,它支持 128K tokens 的长上下文窗口,使其在长文本理解、代码分析和复杂逻辑推理任务中同样表现出色。
此次升级的关键在于训练后优化,DeepSeek 团队通过改进推理策略和计算资源分配,使模型在数学推导、代码生成和复杂问题解决方面的能力大幅提升。
LMArena 最新测试结果在社交平台上引发了诸多讨论。
在 X 上,有 ID 名为 Sughu 的用户表示,DeepSeek 与 Claude Opus 4 匹敌。这些数字令人难以置信。

还有用户已经摩拳擦掌,迫不及待想试试 R1(0528)实际使用效果怎么样了。
还有用户拿 R1 的开源特性调侃 Opus 等封闭模型。
“区别在于:Opus 让你变穷,但 R1 是免费的。”

也有用户认为,DeepSeek R1 目前在测试中显现出来的性能表现的确是让人印象深刻,但它也有一些地方不及 Claude,比如在用户体验方面还有待提升。
“DeepSeek R1 目前在 WebDev Arena 性能上与 Claude Opus 匹敌,鉴于 Claude 长期以来作为代码型 AI 基准的地位,这是一个值得注意的里程碑。
这标志着开源人工智能的关键时刻。DeepSeek R1 在完全开放的 MIT 许可证下提供了前沿级别的能力,表明开放模型如今已能够与最优秀的专有系统相媲美。虽然这一突破在 Web 开发领域最为显著,但其影响可能会扩展到更广泛的编码领域。
然而,原始性能并不能定义其实际效用。DeepSeek R1 在技术能力上或许能与 Claude 匹敌,但它在用户体验方面仍远不及 Claude,而正是这种体验让 Claude 在日常工作流程中如此高效。”
在 Reddit 平台上,一些用户同样对 DeepSeek R1(0528)强大的编码能力表示赞扬,甚至觉得使用 R1 辅助编程的开发者能碾压用其他封闭模型的开发者。
“DeepSeek R1(0528)很火。我知道这是 LMAarena 的测试(可能会有点不那么准确),但我绝对相信 R1 的实力有能力做到如此。我觉得它用在编程上,它的性能确实能与 Gemini/OpenAI 和 Anthropic 的模型匹敌。一个能用 DeepSeek 的程序员会碾压使用封闭模型的普通程序。”
但也有用户对 WebDev Arena 测试的结果表示了怀疑,认为 DeepSeek 的确很强大,但在 WebDev 中与 Opus 比肩,还是不太相信。
“他们(LMArena)有没有修改评级流程或模型?DeepSeek 很棒,但在 WebDev 领域能和 Opus 比肩吗?不可能的!”

其实也不怪网友质疑 LMArena 的测试结果,因为前不久,AI 实验室 Cohere、斯坦福大学、麻省理工学院和 Ai2 也联合发表了一篇新论文,指责 LMArena 在榜单分数上偏袒一些科技巨头公司。

论文地址:https://arxiv.org/pdf/2504.20879
据作者称,LMArena 允许一些行业领先的 AI 公司(例如 Meta、OpenAI、谷歌等)私下测试多种 AI 模型变体,并且不公布表现最差的模型的得分。作者表示,这使得这些公司更容易在该平台的排行榜上名列前茅。
作者称,在科技巨头 Meta 发布 Llama 4 之前的 1 月至 3 月期间,一家名为 Meta 的 AI 公司在 Chatbot Arena 上私下测试了 27 种模型变体。在发布时,Meta 只公开透露了一个模型的得分——而这个模型恰好在 Chatbot Arena 排行榜上名列前茅。
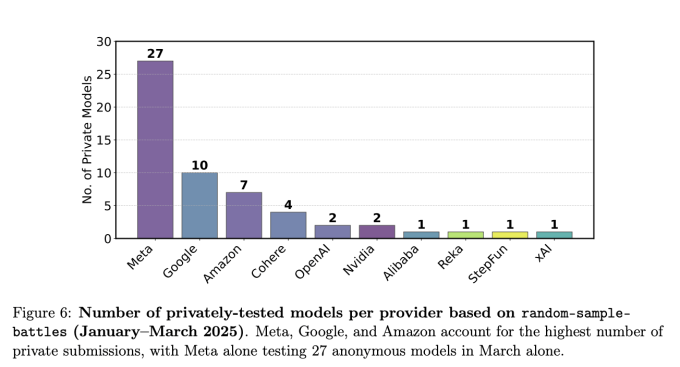
这项研究的图表。(图片来源:Singh 等人)
面对这些指控,LMArena 联合创始人兼加州大学伯克利分校教授 Ion Stoica 在给媒体的一封电子邮件中表示,这篇论文充满了“不准确之处”和“值得怀疑的分析”。
月之暗面新模型编程新榜单超过 R1
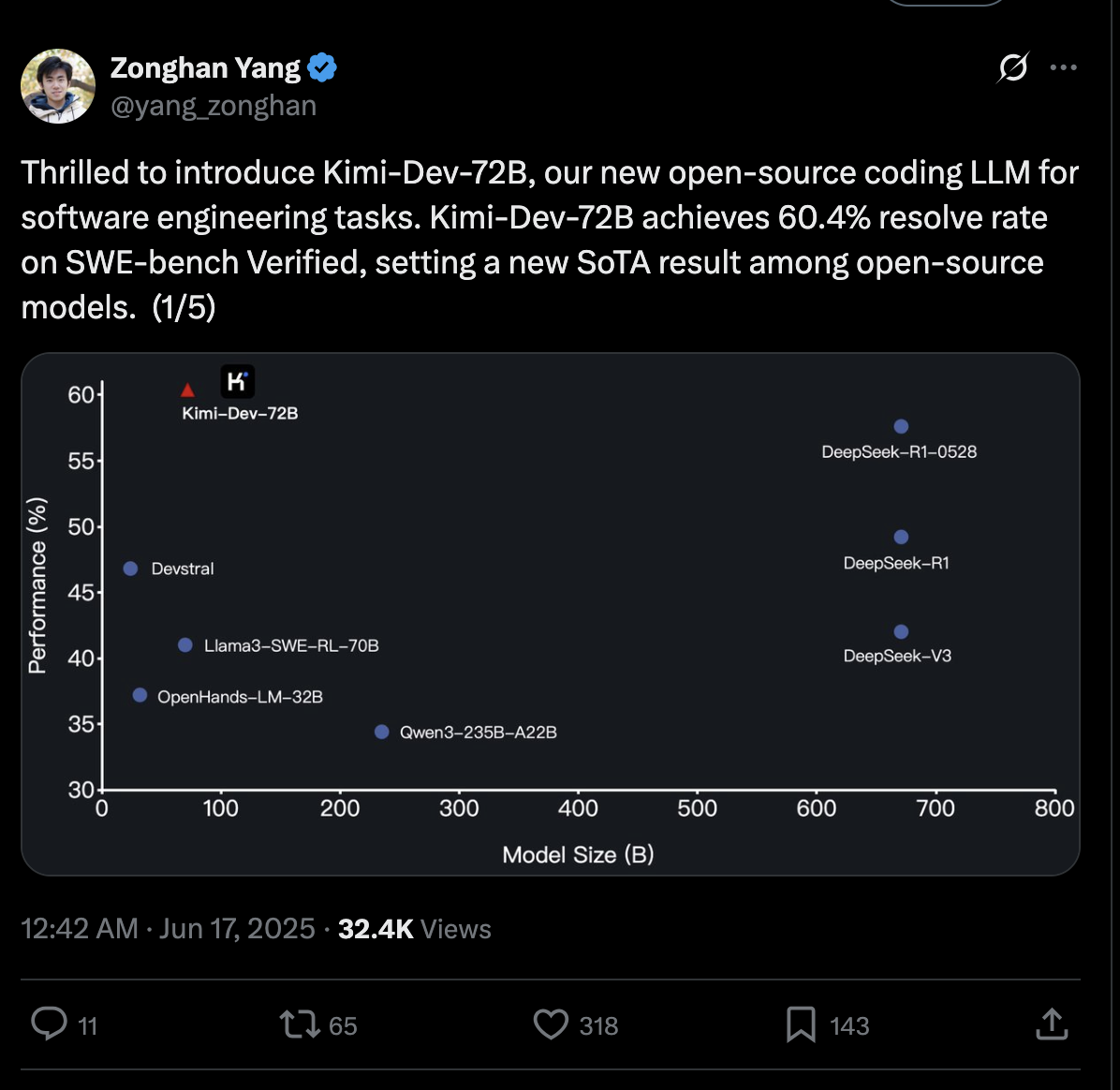
巧合的是,今天月之暗面发布了针对软件工程任务的全新开源代码大模型 Kimi-Dev-72B。
Kimi-Dev-72B 项目地址:https://huggingface.co/moonshotai/Kimi-Dev-72B
该模型在 SWE-bench Verified 编程基准测试中取得了全球最高开源模型水平,以仅 72B 的参数量,成绩超过了 R1(0528),而 R1(0528)在中 LMArena 的编码能力测试中与谷歌、Anthropic 模型并列第一。
Kimi-Dev-72B 在 AI 软件工程能力基准测试 SWE-bench Verified 上取得了 60.4%的高分,创下开源模型的 SOTA 成绩。
Kimi-Dev-72B 通过大规模强化学习进行了优化。它能够自主修补 Docker 中的真实存储库,并且只有当整个测试套件通过时才会获得奖励。这确保了解决方案的正确性和稳健性,并符合现实世界的开发标准。
在月之暗面官网上,研发团队介绍离 Kimi-Dev-72B 的设计理念和技术细节,包括 BugFixer 和 TestWriter 的组合、中期训练、强化学习和测试时自我博弈。
BugFixer 和 TestWriter 的组合
一个成功修复漏洞的补丁应通过能准确反映该漏洞的单元测试。同时,一个成功复现漏洞的测试应触发断言错误,而当向代码库应用正确的漏洞修复补丁后,该测试应能通过。这体现了漏洞修复者(BugFixer)与测试编写者(TestWriter)的互补作用,而能力足够强的编码大语言模型应能在这两方面都表现出色。
漏洞修复者与测试编写者遵循相似的工作流程:二者均需先找到需要编辑的正确文件,再进行代码更新(无论是修正脆弱的实现逻辑,还是插入单元测试函数)。因此,针对这两种角色,Kimi-Dev-72B 采用了相同的极简框架,仅包含两个阶段:(1)文件定位;(2)代码编辑。漏洞修复者与测试编写者的双重设计,构成了 Kimi-Dev-72B 的核心基础。
训练中期
为了增强 Kimi-Dev-72B 作为漏洞修复者(BugFixer)和测试编写者(TestWriter)的先验能力,研发团队采用了约 1500 亿高质量真实世界数据进行中期训练。
它们以 Qwen 2.5-72B 基础模型为起点,收集了数百万条 GitHub 问题与 PR 提交记录作为中期训练数据集。该数据方案经过精心构建,旨在让 Kimi-Dev-72B 学习人类开发者如何基于 GitHub 问题进行推理、编写代码修复方案及单元测试。研发团队还执行了严格的数据净化处理,排除了 SWE-bench Verified 中的所有代码库。中期训练充分强化了基础模型在实际漏洞修复和单元测试方面的知识,使其成为后续强化学习(RL)训练更优的起点。
强化学习
通过适当的中期训练和 SFT,Kimi-Dev-72B 在文件本地化方面表现出色。因此,强化学习阶段专注于提升其代码编辑能力。
Kimi-Dev-72B 使用了 Kimi k1.5 中描述的策略优化方法,该方法在推理任务中表现出色。对于 SWE-bench Verified,有三个关键设计值得重点关注:
仅基于结果的奖励。研发团队仅使用 Docker 的最终执行结果(0 或 1)作为奖励,训练期间不采用任何基于格式或过程的奖励。
高效的提示集。研发团队过滤掉模型在多样本评估下成功率为零的提示,从而更有效地利用大批量。此外,他们还采用课程学习法,引入新的提示,逐步提高任务难度。
正例强化。在训练的最后阶段,研发团队将之前迭代中最近成功的样本纳入当前批次。这有助于模型增强成功模式并提升性能。
Kimi-Dev-72B 通过使用高度并行、强大且高效的内部代理基础设施,从可扩展数量的问题解决任务的训练中受益匪浅。
经过强化学习后,Kimi-Dev-72B 能够同时掌握 BugFixer 和 TestWriter 的角色。在测试过程中,它会采用自我博弈机制,协调自身 Bug 修复和测试编写的能力。

BugFixer 和 TestWriter 之间的测试时自我对弈。
每个问题最多可生成 40 个补丁候选和 40 个测试候选(按照标准无代理设置),可以观察到测试时间自玩的扩展效应。
参考链接:
https://www.reddit.com/r/LocalLLaMA/comments/1lcy6fc/deepseek_r1_0528_ties_claude_opus_4_for_1_in/
https://x.com/lmarena_ai/status/1934650635657367671
https://techcrunch.com/2025/04/30/study-accuses-lm-arena-of-helping-top-ai-labs-game-its-benchmark/




