
OpenAI 发布了新一代语言模型系列——GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano,现已通过 API 开放使用。该系列模型在多项技术基准测试中超越了 GPT-4o 和 GPT-4.5,并支持高达 100 万 tokens 的上下文长度。
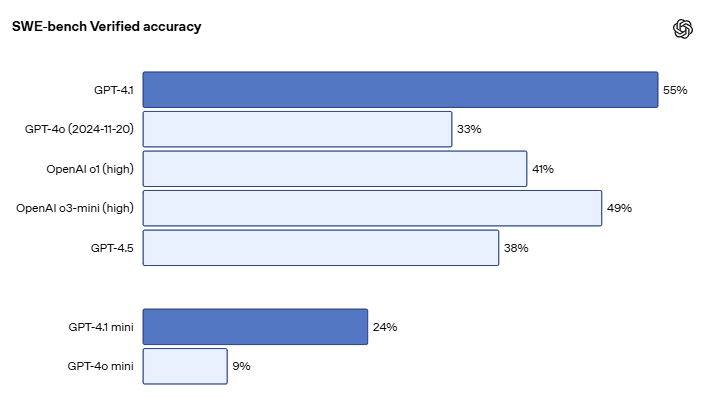
OpenAI 表示,GPT-4.1 在代码能力、指令遵循和长文本理解方面均有提升。在衡量实际软件工程任务的 SWE-bench Verified 基准测试中,GPT-4.1 准确率达到 54.6%,较 GPT-4o(33.2%)提升 21 个百分点,比 GPT-4.5 高出 26.6 个百分点。在 Scale 的 MultiChallenge 指令基准测试中,该模型也比 GPT-4o 提高了 10.5 分。
来源:OpenAI 博客
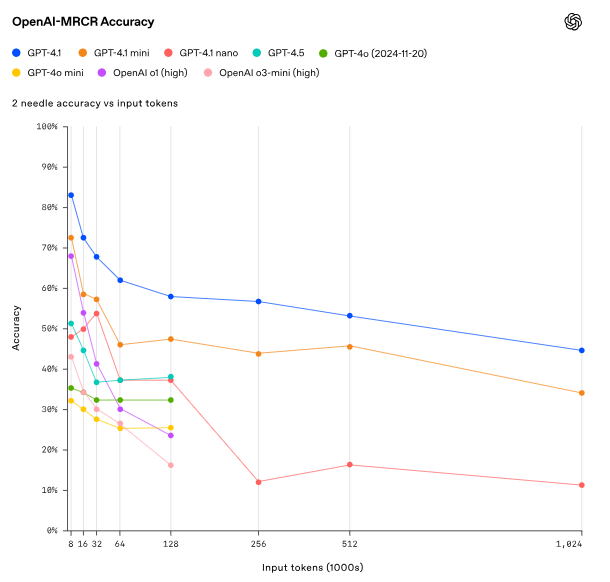
OpenAI 还测试了该系列模型处理长文本输入的能力。GPT-4.1 全系模型均可支持长达 100 万 tokens 的上下文。在 OpenAI-MRCR 和 Graphwalks 等内部评估中,GPT-4.1 在长文本任务(如分散信息检索与推理)中表现稳定。例如,在多跳推理基准测试 Graphwalks 中,GPT-4.1 得分为 61.7%,而 GPT-4o 仅为 42%。
来源:OpenAI 博客
除了主模型外,GPT-4.1 mini 以更低的延迟和成本提供了相近的性能。OpenAI 表示,该模型在多数智能评估中达到或超越 GPT-4o 水平,同时成本降低达 83%。GPT-4.1 nano 是该系列中最轻量也最快速的版本,专为分类和自动补全等简单任务设计,但仍保持高分表现,例如在 MMLU 测试中达到 80.1%,在 GPQA 测试中达到 50.3%。
OpenAI 特别强调了该模型在代码编辑能力的提升。在 Aider 的多语言基准测试中(该测试主要评估生成差异代码而非重写整个文件的能力),GPT-4.1 超越了包括 GPT-4.5 在内的所有前代模型。其不必要编辑的比例从 GPT-4o 的 9% 降至 2%。
OpenAI 确认 GPT-4.5 Preview 将于 2025 年 7 月 14 日停用,并表示 GPT-4.1 在成本和性能上的改进是此次迭代的主要原因。这印证了社区对 GPT-4.5 临时性质的猜测。一位 Reddit 用户评论道:
GPT-4.5 根本就是个预览版,连‘公测版’都算不上,它就是拿来测试新模型用的。既然不是正式版,可以说 GPT-4.5‘从未’存在过,所以新版才叫 GPT-4.1……开放期间 OpenAI 一直在收集数据……可能就是为了做个更强更便宜的蒸馏模型,最后搞出了 GPT-4.1。
定价方案也进行了调整。相比 GPT-4o,GPT-4.1 的常规查询费用降低了约 26%。提示词缓存折扣提升至 75%,且长文本使用不再收取超出标准 token 费用之外的附加费。
GPT-4.1 系列现已通过 OpenAI API 开放使用。目前 ChatGPT 仍在升级 GPT-4o,因此暂未搭载该系列模型。
查看英文原文:OpenAI Introduces GPT‑4.1 Family With Enhanced Performance and Long-Context Support




