
Cursor 推出了一种新方法,用于减少发送给大语言模型(LLM)的请求上下文的大小。这种方法名为动态上下文发现(Dynamic Context Discovery),它摒弃了以往在请求开始时就包含大量静态上下文的做法,转而让智能体(agent)按需动态检索所需信息。这种方式不仅显著减少了 token 消耗,也避免了将可能令人困惑或无关的细节混入上下文。
为了实现动态上下文发现,Cursor 采用了五种不同的技术。这些技术有一个共同特点,即以文件作为 LLM 工具的主要接口,使内容能够由智能体动态存储和获取,而不是一次性塞满有限的上下文窗口。
随着编码智能体能力的快速提升,文件已成为一种简单而强大的基础原语(primitive)。相比引入另一种尚无法完全适应未来需求的抽象层,使用文件是一种更安全、更务实的选择。
Cursor 使用的第一项技术是将大规模输出(比如,shell 命令或其他工具的输出)写入文件,确保关键信息不会因上下文截断而丢失。随后,智能体可根据需要使用tail等命令读取文件末尾的内容。
其次,针对上下文过长时被摘要压缩而导致信息丢失的问题,Cursor 会将完整的交互历史保存到文件中,使智能体能在后续需要时检索缺失的细节。同样,领域特定的能力被存放在文件中,智能体可通过Cursor内置的语义搜索工具动态发现相关文件。
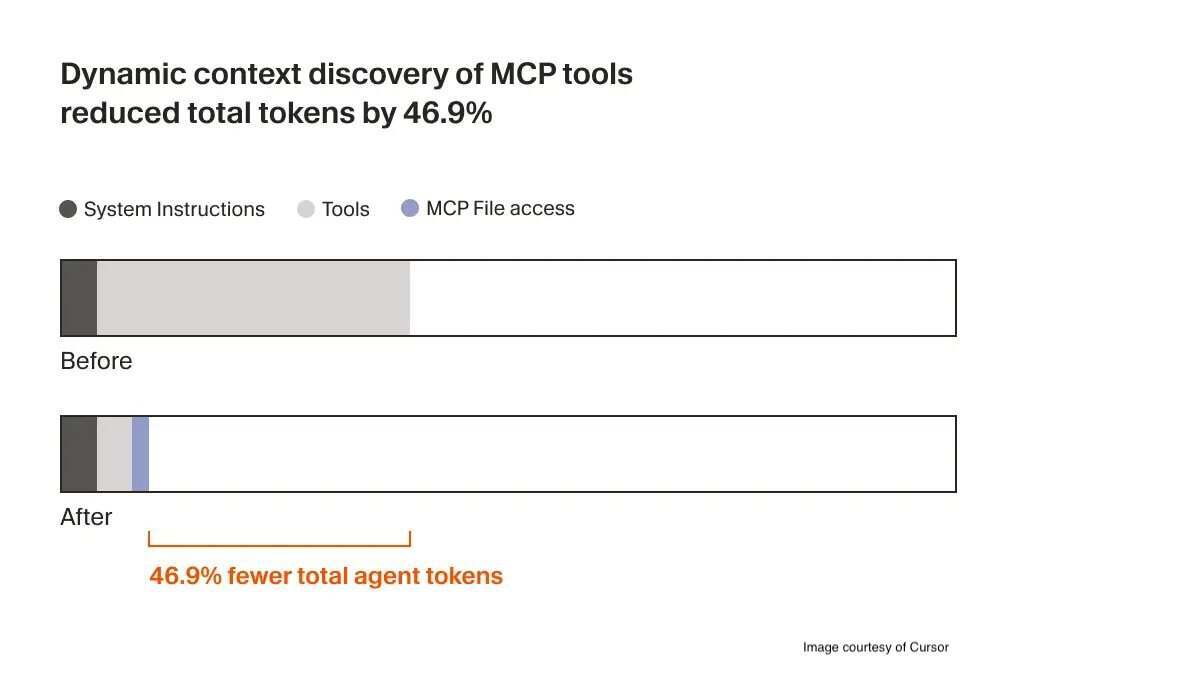
对于 MCP 工具(Model Context Protocol 工具),传统做法是在请求初始阶段就加载所有 MCP 服务器提供的工具描述,而 Cursor 修改为仅传递工具名称。当任务实际需要某个工具时,智能体才会动态拉取其完整定义。这一策略大幅降低了 token 总量:
智能体现在只接收少量的静态上下文(包括工具名称列表),并在任务需要时主动查询具体工具。在一项 A/B 测试中,对于调用了 MCP 工具的运行实例,该策略平均减少了 46.9%的总 token 使用量(结果具有统计显著性,但方差较大,这取决于所安装 MCP 服务器的数量)。
此外,这种方法还带来一个额外的优势,那就是智能体可以监控每个 MCP 工具的状态。例如,比如某个 MCP 服务器需要重新认证,智能体可以及时通知用户,而不是完全忽略该问题。
最后,所有终端会话的输出会同步到文件系统。这使得智能体能更轻松地回答用户关于命令失败原因的问题。同时,通过将输出存入文件,智能体可使用 grep 等工具仅提取相关的信息,进一步压缩上下文规模。
在 X 上,用户 @glitchy 指出,虽然减少token是重要目标,但是尚不清楚这种动态机制是否会增加延迟。@NoBanksNearby 则认为,动态上下文发现“在同时运行多个MCP服务器时,对开发效率提升巨大”。@casinokrisa也对此表示赞同:
token 数量几乎减少了一半,既降低了成本,又加快了响应速度,尤其是在多服务器场景下。
最后,@anayatkhan09提出了可能的优化方向:
下一步应该是向用户开放动态上下文策略,让我们能针对不同代码仓库调整优化的激进程度,而不是对所有工具一视同仁。
据 Cursor 官方表示,动态上下文发现功能将在未来几周内向所有用户开放。
原文链接:
AI-Powered Code Editor Cursor Introduces Dynamic Context Discovery to Improve Token-Efficiency




