
整理 | 华卫、核子可乐
9 月 12 日,OpenAI 万众期待的“草莓”(Strawberry)终于上线了。这一新模型名为 o1,是 OpenAI 推理模型家族的首位成员,能够解决现有 AI 模型所无法攻克的科学、编码和数学难题,甚至包括 OpenAI 最强大的现有模型 GPT-4o。但与此同时,o1 模型也比 GPT-4o 价格更贵、生成速度更慢。
该公司表示,o1 模型并不是 GPT-4o 的继任者,而只是对 4o 的强大补充。o1 不再像传统大语言模型那样一步步得出答案,而是通过推理拆解问题,像人一样行之有效地给出思维步骤,最终得出正确结果。并且,OpenAI 还推出了体量更小、价格更低的 o1-mini 版本。
思维更像人了,编码、数理能力指数级增长
“使用 o1 在一分钟内创建 3D 版本的贪吃蛇游戏!”在国外某社交平台上,一位网友发布了完整的演示视频。
还有网友通过合并 o1 和 Cursor Composer,在 10 分钟内为 iOS 创建了一个带有动画的完整天气应用程序。
有网友这样评价 o1,“编码和数学能力是 GPT-4o 的指数级增长!现在每个人都可以建造任何东西!”还有人称,“Cursor 和 Replit 的压力暴增”,“奥特曼用 o1 杀死了 Cursor、Replit 和其他许多代码模型”。
OpenAI 官方还则展示了使用这套新模型解决现有模型 GPT-4o 也无法解决的几个问题,其中包括两道令人费解的数学题。
第一道:“已知公主的年龄比王子大,当公主的年龄是王子年龄的两倍时,此时公主年龄是二人现在年龄总和的一半,问公主和王子现在多大?”该模型成功理解了这一问题中的不同变量并确定了解决问题所需的方程式,最终分步给出了正确答案(王子 30 岁,公主 40 岁)。
OpenAI 还专门设计了界面来显示模型思考时的推理步骤,其中令人印象深刻的是,o1 似乎在刻意模仿人类的思维:“我很好奇”、“我正在认真思考”和“好的,让我想想”之类的表达,真的营造出一种它在分步推理的感觉。
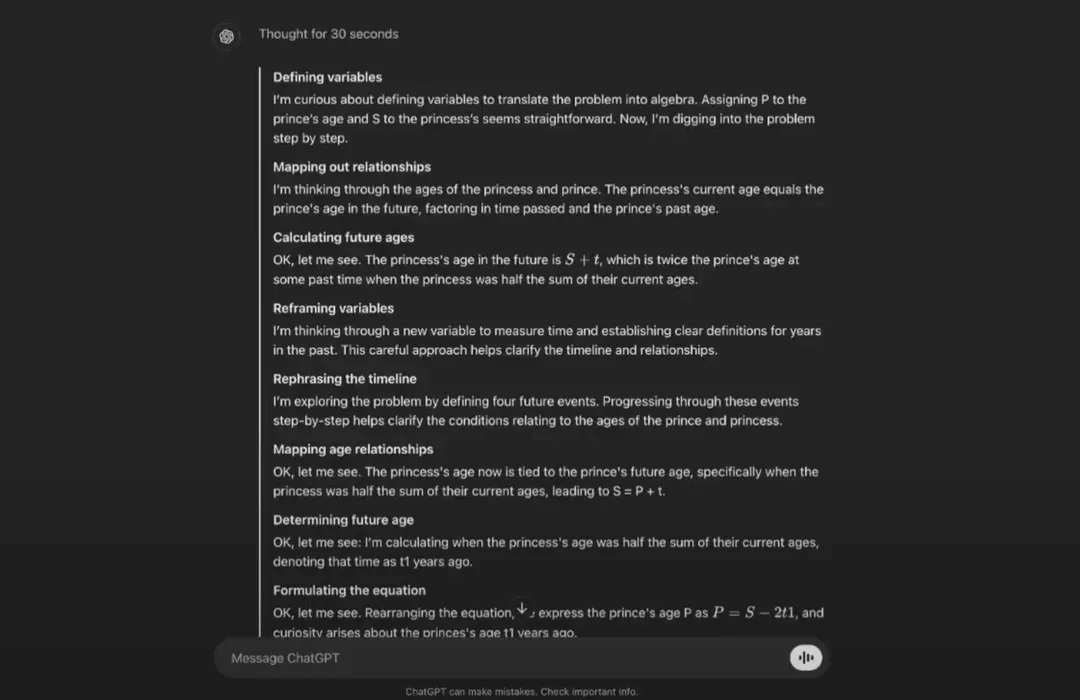
OpenAI 首席研究官 Bob McGrew 表示,“与之前的模型相比,o1 的确在某些方面感觉更像人。”同时,McGrew 指出,“这套模型在解决 AP 数学考试方面的表现比我更好,我还是数学专业出身呢。”OpenAI 研究副总裁 Mark Chen 则介绍称,“新模型正在学习独立思考,而不是像传统大模型那样试图模仿人类的思维方式。”
第二道,要求 o1 数出“strawberry”这个单词里有几个 r。由于基于 token 化(即大模型以 token 数据块的方式处理单词)模式,大多数语言模型对于单词中个别字符的差异往往视而不见。很明显,o1 具有自我反思能力,可以在未经用户提示的情况下理解如何计算字母数量并给出正确答案。
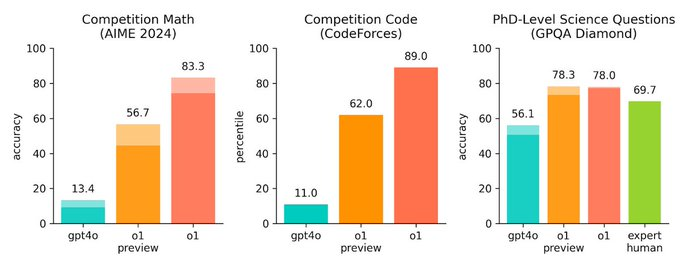
据 OpenAI 介绍,在针对数学专业学生的美国数学邀请赛(AIME)中,GPT-4o 的平均解题成功率为 13.4%,而 o1 的正确率则高达 83.3%。在 Codeforces 在线编程竞赛当中,这套新模型的排名为全体参赛者中的第 89 百分位。
“刚刚测试了一些物理问题,目前的测试结果是 100% 正确的。”物理学科上,o1 的表现也获得了不少网友的认可。
OpenAI 宣称,在解决博士水平的物理问题时,o1 达到了 92.8 分的水平,GPT-4o 才 59.5 分。并且, o1 的下一个更新版在其测试中,“在物理、化学和生物学等具有挑战性的基准任务上,拥有与博士生相当的解题表现。”
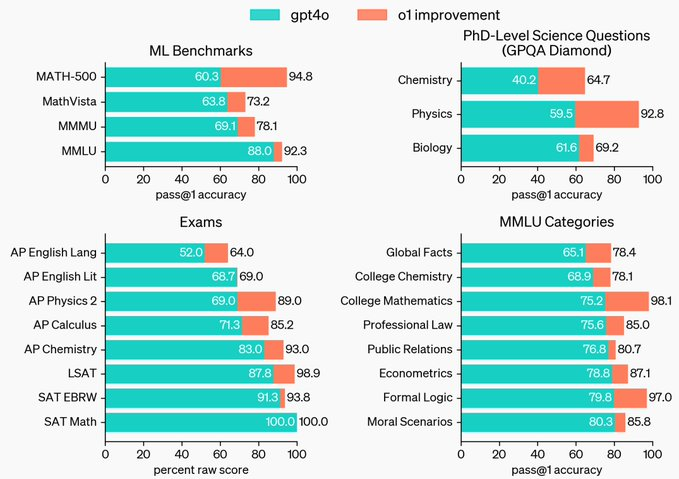
不过,对于这个评分结果似乎也存在一些争议。有网友指出,“AP 物理成绩是 89 分,而博士成绩是 92.8 分?如果按照这个结论,这些数字就说不通了。原因在于博士水平的问题来自预制题集,而非一般问题。实际上,这仍属于 AP 物理能力水平。”
另外,在 OpenAI 官方分享的演示中,还有一个要求 o1“写一个语法正确的句子,并且不要重复使用任何字母”的案例。最终,o1 花了 39 秒的时间给出了“go fix my bed”的答案。
从目前 o1 的这些案例演示中可以看到,该模型的确更适合解决数学、物理和编码等科学领域的复杂问题。OpenAI 也在官方公告指出,“医疗研究人员可以使用 o1 模型标注细胞测序数据,物理学家可以使用 o1 模型生成量子光学所涉及的复杂数学公式,各领域的开发人员也可以使用 o1 模型构建并执行多步骤工作流程。”
然而,现在 o1 还有许多不足之处。首先,目前亮相的 o1 预览版仍有一定局限性,如无法浏览网页或接收上传的文件和图像。OpenAI 表示,对于这类任务,GPT-4o 仍是最佳模型选项。
其次,o1 初见之下令人惊艳,但也已在用户的长时间使用中暴露出短板。例如,沃顿商学院教授 Ethan Mollick 向 o1-preview 提交了八条关于填字游戏的线索,要求其将内容翻译成文本。o1 模型通过多个步骤共耗时 108 秒才给出答案,虽然结果完全正确,但虚构了一条 Mollick 并未给出的特定线索。
还有一位网友指出,o1 不能解决后向传播推理的问题。
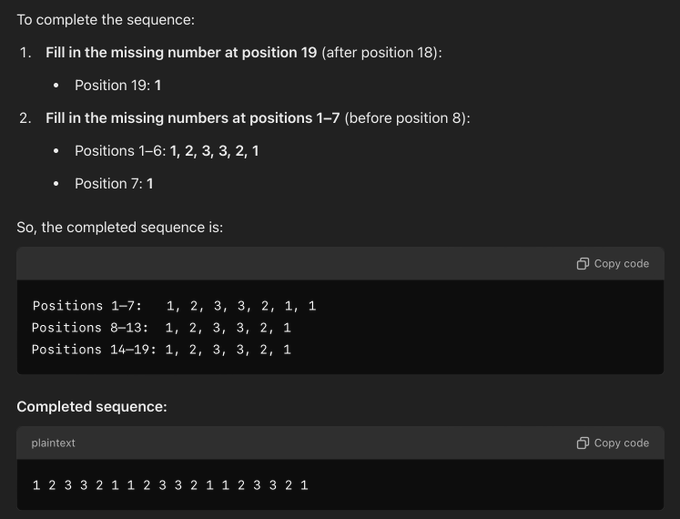
输入:给定这个不完整的序列:. . . . . 1 2 3 3 2 1 1 2 3 3 2(空白处用“. ”表示),请补全序列。
o1 的结果:
位置 1-7 错误
即使 1-7 是正确的,也错误地将其放在完成的序列中。
完整序列中的错误
定价高 GPT-4o3 倍以上,改进目标竟是加长响应时间
“o1 背后的训练方式与之前的大模型有着根本性的不同。”OpenAI 公司研究负责人 Jerry Tworek 解释称。尽管该公司对于具体细节含糊其辞,但承认 o1“使用的是一种全新的优化训练算法,同时辅以为其量身定制的新训练数据集。”
OpenAI 已经成功教会之前的 GPT 模型如何模仿训练数据中的模式,而 o1 使用的是名为强化学习的技术以训练模型自主解决问题。这项技术通过奖惩机制引导系统行为,即在模型答对时给予正反馈、答错时给予负反馈,借此改进其推理过程。以此为基础,o1 可以使用“思维链”来处理查询,类似于人类以分步方式解决问题。
OpenAI 表示,凭借这种新的训练方法,o1 模型生成的结果应该会更加准确。Tworek 指出,“我们注意到这套模型的幻觉有所减少”,但问题仍然存在,“尚不能说我们彻底消灭了幻觉。”
据 OpenAI 介绍,这套新模型与 GPT-4o 最大的区别在于,能比前辈更好地解决编码和数学等复杂难题,同时还可对推理过程做出解释。Tworek 表示,OpenAI 并不认为 AI 模型的思维等同于人类思维。但他表示,推理界面确实能够展示模型如何花费更多时间深入剖析并解决问题。
Chen 解释称,OpenAI 已经成功建立起一套通用性更强的推理系统。“我认为我们确实在这方面取得了一定突破,而这也是 OpenAI 的优势之一。实际上,它在所有领域的推理方面都有相当不错的表现。”
但与此同时,o1 在很多领域的能力则不及 GPT-4o。OpenAI 推理研究科学家、德扑 AI 之父 Noam Brown 表示,“我们的 o1 模型并不总是比 GPT-4o 好。许多任务不需要推理,有时等待 o1 响应与快速 GPT-4o 响应是不值得的。”

想象的 openAI 的 o1 在后台工作
值得一提的是,对于 o1 的推理思考时间,未来 OpenAI 的改进方向是继续增加。
目标是让未来的版本思考数小时、数天甚至数周。推理成本会更高,但您会为新的癌症药物支付多少费用?又会为突破性的电池和证明黎曼假说付出多少?AI 可以不仅仅是聊天机器人。
在谈到安全问题时,OpenAI 表示,根据拜登总统先前发布的 AI 行政令规定,o1 模型已经向美国和英国安全研究机构开发以接受早期测试。在 OpenAI 最难的越狱测试之一中,GPT-4o 得分为 22(0-100 分),而 o1-preview 模型得分为 84。
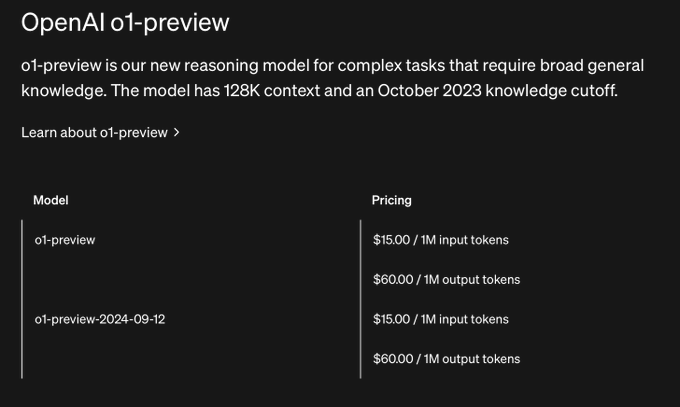
定价方面,o1 大约是 GPT-4o 和 100x 4o mini 的 3.5 倍。就目前来看,开发人员要想访问 o1 需要支付高昂的价格:在 API 中,o1-preview 每 100 万个输入 token(即供模型解析的文本块)收费 15 美元,每 100 万个输出 token 收费 60 美元。相比之下,GPT-4o 每 100 万个输入 token 只收费 5 美元,而 100 万个输出 token 则收费 15 美元。
为了向开发人员提供更高效的解决方案,OpenAI 还发布了更经济高效的的 o1-mini,比 o1-preview 便宜 80%,适用于需要推理但不需要广泛世界知识的应用程序。OpenAI 方面表示,他们计划将 o1-mini 的访问权限向全体 ChatGPT 用户免费开放,但具体发布日期未定。
即日起,ChatGPT Plus 和 Team 版的用户从可以访问到 o1-preview 和 o1-mini 模型,Enterprise 和 Edu 用户则将于下周起获得访问权限。
值得一提的是,在 o1 模型背后的研究团队里,有不少华人开发者的身影。从 OpenAI 发布的 o1 模型核心贡献者名单里,我们也看到了许多华人的姓名:Chong Zhang、Mengyuan Xu、 Mingxuan Wang、 Lilian Weng 等。
提高 AI 智能水平,不必依靠无限的规模提升
去年,OpenAI 发布的 GPT-4 模型已经将参数规模扩大到令人难以置信的水平,同时也成为 AI 领域最具份量的重大突破。如今,该公司再次带来最新进展,也标志着生成式 AI 在方法论层面的转变——新模型能够以逻辑方式“推理”解决诸多难题,其智能水平要远超现有 AI 方案,而且无需依靠无穷无尽的规模提升。
OpenAI 公司首席技术官 Mira Murati 在采访中表示,“我们认为这将成为 AI 模型中的新范式,而且在处理高度复杂的推理任务方面有着明显更好的表现。”
Murati 解释称,OpenAI 目前正在着力构建下一代主模型 GPT-5,且将在体量方面远远超过其前身。尽管 OpenAI 仍然坚信提升规模有助于帮助 AI 挖掘出新的能力,但 GPT-5 也可能会同时融入此番公布的推理技术。Murati 指出,“大语言模型拥有两种范式,一种是传统的扩展范式,另一种就是这种推理新范式。我们希望能把二者合而为一。”
OpenAI 此番发布的技术,也有望保障 AI 模型不偏离正确的行为轨道。Murati 指出,新模型已经证明自身能够有效避免产生令人不悦或者潜在有害的输出,因为它能够展示行为结果的推理过程。“这就像是教导孩子,只要他们能够推理为为什么要做某件事,就可以更好地学会遵循某些规范、行为和价值观。”
如何提高大语言模型的推理能力,一直是 AI 研究领域的热门议题。事实上,其他竞争对手也在进行类似的研究。今年 7 月,谷歌就公布了 AlphaProof,能够通过查看正确答案来学习如何推理并解决数学问题。但扩大这种学习方式的一个关键挑战,在于模型可能遇到大量不存在正确答案的问题。
斯坦福大学教授 Noah Goodman 则发表了关于提高大模型推理能力的论文,在他看来通用训练的关键可能在于使用“精心编写的提示词配合手工生成的数据”对语言模型进行训练。他补充称,能够比较稳定地用推理速度来换取更高的准确性,本身就是个“很大的进步”。
麻省理工学院助理教授 Yoon Kim 也提到,大语言模型的解题过程目前仍然相当神秘。即使模型进行逐步推理,其底层机制也可能与人类智能存在巨大差异。随着该技术得到广泛应用,这种差异自然值得引起高度重视。“这些系统可能将被用于做出影响普罗大众的决策。而更重要的问题在于,我们能否充分信任模型做出的决策。”
华盛顿大学名誉教授、著名 AI 专家 Oren Etzioni 评论称,“让大语言模型能够参与到多步骤问题解决、工具使用和复杂问题的解决中来,无疑至关重要。”他同时补充称,“单纯扩大规模不足以实现这个目标。”然而 Etzioni 也承认未来还有更多挑战需要克服。“即使推理问题得到解决,我们也仍面临着幻觉与事实之间的冲突。”
OpenAI 研究副总裁 Mark Chen 则做出乐观解释,表示该公司开发的新推理方法表明,推进 AI 发展并不一定需要耗费大量算力。“这种模式最令人兴奋的一点,在于我们相信它能让我们以更便宜的价格交付智能成果。我认为这也正是 OpenAI 公司的核心使命所在。”
参考链接:
https://www.wired.com/story/openai-o1-strawberry-problem-reasoning/
https://mashable.com/article/openai-releases-project-strawberry-o1-model
https://www.theverge.com/2024/9/12/24242439/openai-o1-model-reasoning-strawberry-chatgpt




