
3 月 9 日,Anthropic 推出了一款新的代码审查产品 Code Review,主打在人工介入之前,先用 AI 自动检查 Pull Request 中的问题。 这项服务面向团队和企业用户,瞄准的是软件开发生命周期(SDLC)中一个越来越突出的新环节:代码写得越来越快,但代码审查正逐渐成为瓶颈。
和传统 IDE 内置的审查插件不同,Code Review 主要运行在 GitHub 和 CI 流程中,而不是开发者本地的 IDE 里。也就是说,它更像是被放在代码提交之后、人工审查之前的一道自动检查关卡。乍一看,这确实像是个很有吸引力的新功能——毕竟在 AI 持续抬高代码产能之后,代码审查已经成了越来越多团队不得不面对的新问题。
更贵,也更慢:Claude 开始收“审代码税”
实际上,Anthropic 的 Claude 模型本身已经具备按需进行代码审查的能力——甚至可以通过让 Claude 审查自己写的代码,来评估 AI 生成代码的质量。此外,公司还提供了 Claude Code GitHub Action,可以在 CI/CD 流水线中自动触发代码审查。而新的 Code Review 服务,则把这种能力做得更深入——当然,成本也更高。
“代码审查按 token 使用量计费,通常平均每次在 15 到 25 美元之间,具体费用取决于 Pull Request 的规模和复杂度。”
注意,Claude Code 创始人 Boris 强调了这是每个 Pull Request 的价格。
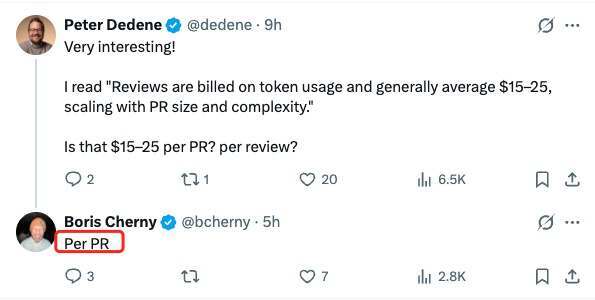
从开发者实际测试来看,这个价格并不只是纸面数字。开发者 Sinai Gross 表示,他测试了 Claude Code 的代码审查功能,一次共审查了 3 个 Pull Request:其中两个 PR 各修改了约 750 行代码,另一个修改了约 100 行,系统给出的平均费用是 18.39 美元。
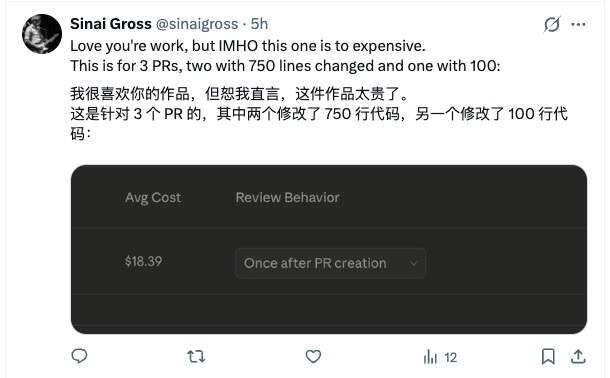
问题在于,这样的价格一旦放到真实的工程规模里,成本会迅速放大。网友 DanT(@uyintans) 就直接指出,如果一家中大型公司每天都会产生大量 Pull Request,而每个 PR 都要花 15 到 25 美元来审查,那么规模化之后,这笔费用很容易滚到每年数百万美元。
换句话说,假设一个团队一天产生 100 个 PR——这在大型工程团队里并不算夸张。按“每位工程师每天提交 1 到 2 个 PR”估算,一个 50 人的工程团队,一天就可能接近这个数量。若按平均 20 美元一次审查计算,一天就是 2000 美元,一年大约就是 70 多万美元。如果是更大的工程组织,PR 数量再翻几倍,整体成本很快就会迈入百万美元级别。
对比之下,做 AI 代码审查的 CodeRabbit,月费也不过 24 美元。也就是说,Claude 这套多跑两次 PR,花的钱可能就已经超过别人一个月。
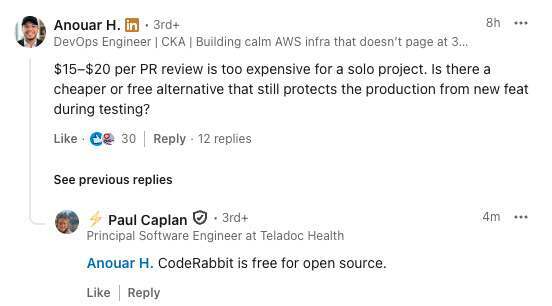
Q:每次 PR 审查要 15–20 美元,对于一个个人项目来说实在太贵了。有没有更便宜甚至免费的替代方案,同时还能在测试阶段防止新的功能把生产环境搞崩?
A:CodeRabbit 对开源项目是免费的。
而且,Code Review 的速度也不算快。Anthropic 表示,具体耗时取决于 Pull Request 的规模,但平均一次审查需要约 20 分钟。
原因在于,这些 Agent 并不只分析 PR 的改动部分,而是会把整个代码库作为上下文来分析。
Anthropic Claude Code 产品负责人 Cat Wu 认为,这样可以避免某个文件的改动在其他文件中引入新的 bug——例如不同模块之间存在一些意想不到的交互关系。
她解释说,他们希望这个系统“非常智能、非常彻底,而目前实现这一点的方式,就是让它运行得更久一些。”
“不过换来的结果是更可靠的输出。而且每个 Agent 不只是查看你修改的代码,它们可以灵活地遍历整个代码库。”
目前,这个工具只会在 Pull Request 创建时自动运行。对于简单的 PR,系统只会进行一次“轻量级扫描”;而对于复杂的 PR,则会调用更多 Agent,进行更深入的分析。
并行 Agent,效果还不差
在实际运行中,Code Review 会派出一组并行工作的 Agent,每个 Agent 负责寻找不同类型的错误。任务完成后,它们会在 Pull Request 中留下评论,总结发现的问题,并在必要时给出修复建议。
不过,这些 Agent 不会自动批准 Pull Request——最终是否通过,仍然由人类工程师决定。
这些 Agent 的重点是发现逻辑错误(logic errors),而不是代码风格问题。这是一个刻意的设计选择。 Cat Wu 表示,这样做可以减少误报。
她解释说:“很多时候人类在做代码审查时,不仅会发现逻辑错误,还会提出大量代码风格上的问题。我们发现,在 AI 生成的代码审查中,开发者最关心的其实是逻辑错误,所以这也是系统的核心关注点。”
“大家对误报非常敏感。如果我们只专注于逻辑错误和真正的 bug,那么误报率就会很低。因为一旦发现 bug,几乎肯定就应该修复。”
Anthropic 表示,他们已经在内部使用 Code Review 数月,并取得了相当不错的成果。公司称:
对于超过 1000 行变更的大型 Pull Request,84% 的自动审查会发现值得关注的问题,平均 7.5 个问题。
对于少于 50 行的小型 Pull Request,31% 会收到评论,平均 0.5 个问题。
而在人类开发者的反馈中,被 Claude 标记的问题里,不到 1% 会被工程师否决。

一些参与测试的客户也获得了实际收益。例如,当 TrueNAS 在其开源中间件中进行 ZFS 加密模块重构时,这个 AI 审查服务在相邻代码中发现了一个 bug:一个类型不匹配的问题,可能在同步操作时导致加密密钥缓存被清空。
Anthropic 还举了一个内部案例:Code Review 曾发现一处看似无害的一行代码修改,但如果合入生产环境,实际上会破坏服务的认证机制。该公司表示:“这个问题在代码合并之前就被修复了。事后这位工程师也表示,如果没有 AI 审查,他很可能自己发现不了。”
既当运动员,又当裁判
Anthropic 还强调说,过去一年,自家工程师的代码产量增长了 200%,代码审查反而成了新的瓶颈。公司还表示,很多客户也在遇到同样的问题:开发者已经忙不过来,很多 PR 最后只能草草看一眼,很难做深入审查。
这其实也是行业普遍现象:AI 让代码写得越来越快,但审代码的人并没有变多,PR 越来越多,审查自然就跟不上了。
不过网友的质疑也很直接:既然 Claude 能审代码,为什么不一开始就把代码写对?有人吐槽,现在看起来像是 Claude 先写代码,再让 Claude 自己审代码,最后还抓出一堆 Claude 自己写出来的 bug。还有人说得更犀利:这会不会违背了“裁判不能同时当刽子手(既当运动员,又当裁判)”的基本原则?万一 Claude Code 先制造出问题,再靠修复这些问题继续收费呢?
说白了,这看上去更像是在给模型自己的不稳定再加一层补丁——而且这层补丁,还要再收一笔钱。
参考链接:
https://x.com/bcherny/status/2031089411820228645
https://claude.com/blog/code-review
https://www.theregister.com/2026/03/09/anthropic_debuts_code_review/




