
一毫秒的代价:为什么延迟会塑造用户体验
当我们谈论 API 性能时,往往会不自觉地陷入一套“工程化”的语境:响应时间、CPU 周期、连接池、以及偶尔翻出来看的 flame graph。但在真实世界的系统中,尤其是全球化的电商与支付平台里,延迟有着非常“人性化”的成本。
单次 50 或 100 毫秒的延迟,几乎不会被用户明确察觉;但在大规模场景下,它可能悄悄促使用户放弃一次购买、打断一次支付流程,或一点点侵蚀用户对产品的信任。
速度在塑造指标之前,先塑造了感受。用户不会拿秒表去量延迟,他们是“感觉”到的。一次 120 毫秒的结账步骤与 80 毫秒的差异,肉眼不可见,但在情绪层面,却是“顺滑”和“有点烦人”的区别。小规模时,这种摩擦可以忽略;当它发生在数百万次会话中,就会凝结成更低的转化率、更高的弃购率,以及直接的收入损失。
讽刺的是,为了弥补这种体验损失,团队往往投入大量工程资源去做新功能、实验和留存策略;而预防这些延迟本身,所需的工程投入反而更少。
在高吞吐平台中,延迟会被放大。如果一个服务在正常情况下增加 30 毫秒,在高峰期可能变成 60 毫秒;当下游依赖开始抖动时,甚至会膨胀到 120 毫秒。延迟不会“优雅地退化”,它只会层层叠加。一旦尾延迟(p95、p99)开始漂移,就会对所有上游依赖你的服务形成一种隐形“税负”。
每个服务都会引入自己的抖动、序列化开销和网络跳数。最初只是一个 API 的微小波动,最终却可能在几十个相互依赖的服务之间形成级联式变慢。
这正是为什么高性能架构团队把速度视为一种产品特性,而不是附带效果。他们像设计安全性和可靠性一样,有意识地为延迟做设计:设定清晰的预算、明确的预期,以及在压力下仍能保护用户体验的工程模式。
一种很有帮助的视角是“延迟预算”(latency budget)。与其把性能理解为一个单一指标,比如“API 必须在 100 毫秒内返回”,现代团队会将它拆解到完整的请求路径上:
边缘节点:10 ms
路由:5 ms
应用逻辑:30 ms
数据访问:40 ms
网络跳数与抖动:10–15 ms
每一层都有明确的预算配额。延迟不再是抽象目标,而是具体的架构约束。于是取舍开始变得清晰:“如果在服务层增加功能 X,我们需要在哪里做减法,才能不超预算?”
正是这些技术、文化和组织层面的讨论,孕育了真正快速的系统。
本文的核心观点很简单:低延迟不是一次优化,而是一种设计结果。它来自于你在数据就近性、同步与异步流程、缓存边界、错误隔离和可观测性上的一系列选择。很多系统都可以做到亚 100 毫秒,但要在高负载下长期维持,需要工程、产品和运维之间的高度协同。
接下来,我们将拆解真实系统的结构、工程团队在毫秒级取舍中的决策方式,以及组织如何在首次发布之后持续守住性能底线。快速系统从不偶然,它们是被“有意设计”出来的。
快速通道内部:低延迟系统是如何构建的
在讨论优化之前,必须先拉远视角,理解低延迟系统的整体形态。亚 100 毫秒的响应并不是某个“神奇技巧”的结果,而是一个精心编排的组件管道协同运作、尽量减少摩擦的产物。与其说是“让某个点变快”,不如说是“从整个请求旅程中移除不必要的步骤”。
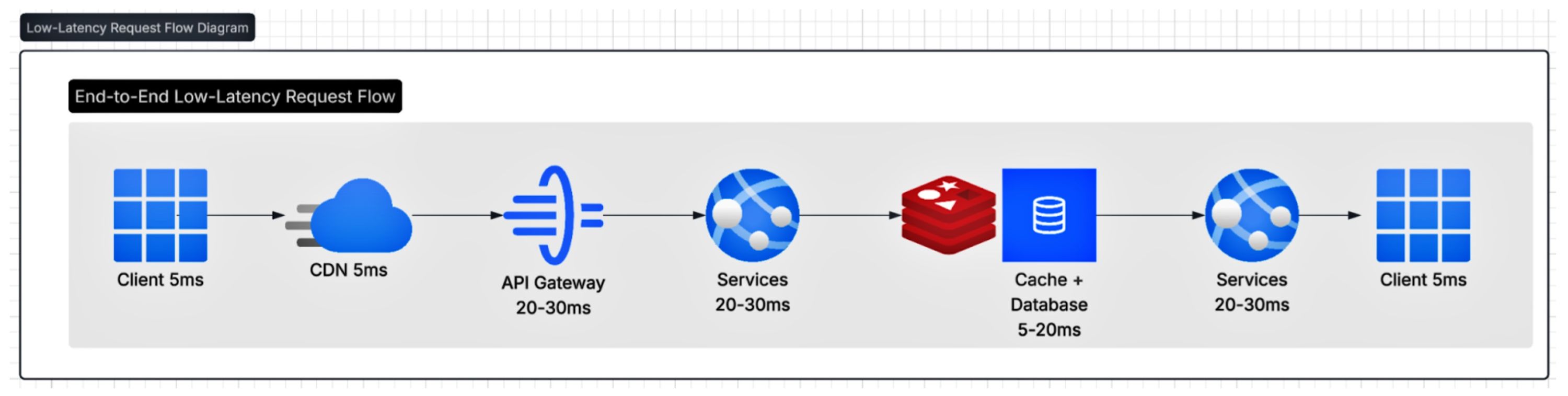
大多数现代系统——尤其是电商和支付系统——表面上都遵循一个看似简单的分层结构:客户端发起请求 → API Gateway → 服务层 → 数据库 → 返回结果。但在这条路径背后,是一个极其精细的链条,每一次跳转、每一次序列化、每一次缓存命中或失效,都会直接影响用户体验。
下面从一次典型的亚 100 毫秒请求出发,看看毫秒通常藏在哪里。
请求的旅程:延迟在哪里潜伏一个典型的亚百毫秒请求流可能如下所示:
客户端 → CDN 或边缘网络: 最近的节点接收请求并进行智能路由。延迟目标:5–15 毫秒。
边缘 → API 网关:负责身份验证、路由、限流。延迟目标:5 毫秒。
网关 → 服务层: 业务逻辑、编排、扇出(Fan-out)。延迟目标:10-20 毫秒。
服务层 → 数据/缓存层: 获取状态。延迟目标:10 毫秒。
服务层 → 网关 → 客户端:序列化并返回。延迟目标:5–10 ms。
在设计良好的情况下,即使在高峰期,这条链路也应保持可预测性。一旦其中任意一环漂移,整条路径都会继承这次变慢。这也是为什么,快速系统首先关注的是“完整旅程”,而不是某一个局部组件。
延迟真正的来源(往往不是你以为的地方)
在生产系统中,延迟很少是“代码慢”导致的,常见根源包括:
网络跳数
每一次跳转都会带来成本:减少一次跳转,往往比重写 100 行 Java 更有效。
TLS 握手
连接池等待
DNS 查询
跨区域通信
序列化与负载体积
JSON 的序列化和反序列化成本被普遍低估。多一个字段,就多一次开销。Protobuf 等二进制格式可以缓解,但也会引入运维复杂度。
冷缓存
在错误的时间发生一次缓存未命中,可能让延迟翻倍甚至翻三倍。这也是为什么新版本部署时,缓存预热策略至关重要。
数据库查询形态
数据库延迟往往是访问模式问题:查询结构、索引设计和基数都会产生巨大影响。一个索引不当的查询,可以把 10 ms 的请求拉高到 120 ms;在高 QPS 下,尾延迟会迅速失控。
下游依赖服务
这是延迟最不可预测的来源。如果你的服务依赖三个下游,最终响应时间通常由最慢的那个决定。
正因如此,异步扇出、缓存和熔断器才成为核心能力。
延迟预算:最重要的架构工具
高绩效团队不会只是“测量延迟”,而是为延迟做预算。延迟预算就像财务预算:每一层都有额度,没人可以超支。
一个典型的 100 ms 预算示例:
有了预算,性能讨论就变得可管理、可协商,而不是主观争论。
为什么理解系统结构如此重要
后文将讨论的所有手段——异步扇出、缓存层级、熔断器、降级策略——都建立在对系统整体结构的理解之上。只优化一个服务,却忽略整体生态,就像升级了发动机,却不管轮胎、刹车和燃油系统。
真正快速的系统通常具备这些特征:
更少的网络跳数
激进的本地缓存
可预测的数据访问路径
并行优于串行
慢组件隔离
高负载下稳定的尾延迟
理解了系统解剖结构,才能进入真正的工程打法。
工程实践手册:让 API 保持“闪电般快速”的取舍
低延迟工程,本质上是对不确定性的工程化管理。快速系统并非靠微优化堆出来,而是由一系列有意识的分层决策构成,目标只有一个:控制尾延迟。
异步扇出:无痛并行
很多慢 API 的根因只有一个:串行依赖。
如果一个请求顺序调用三个下游,每个 40 ms,你还没开始真正的业务逻辑,120 ms 已经没了。
并行是唯一出路
Java 的 CompletableFuture 是天然的适配工具,特别是当它与针对下游并发调优的自定义执行器(Custom Executor)配合使用时:
ExecutorService pool = new ThreadPoolExecutor( 20, 40, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<>(500), new ThreadPoolExecutor.CallerRunsPolicy());CompletableFuture<UserProfile> profileFuture = CompletableFuture.supplyAsync(() -> profileClient.getProfile(userId), pool);CompletableFuture<List<Recommendation>> recsFuture = CompletableFuture.supplyAsync(() -> recClient.getRecs(userId), pool);CompletableFuture<OrderSummary> orderFuture = CompletableFuture.supplyAsync(() -> orderClient.getOrders(userId), pool);return CompletableFuture.allOf(profileFuture, recsFuture, orderFuture) .thenApply(v -> new HomeResponse( profileFuture.join(), recsFuture.join(), orderFuture.join() ));但一个常被忽略的事实是:异步并不会消除阻塞,它只是把阻塞藏进了线程池。
线程池配置不当,会引发:
CPU 抖动
线程竞争
队列堆积
OOM
全链路级联变慢
经验法则
对 IO 型下游调用,线程池大小 ≈ 2 × CPU 核心数 × 单请求并行下游数,并通过 p95/p99 压测校准。
/filters:no_upscale()/articles/engineering-speed-scale/en/resources/111figure-3-1767010410236.jpg)
多级缓存:构建真正的“快路径”
快速系统并不是不做工作,而是避免重复做昂贵的工作。
常见层级:
本地缓存(Caffeine):亚毫秒
Redis:3–5 ms
数据库:20–60+ ms
在系统架构设计中,请务必采用双层缓存模式(Dual-level caching pattern)。以本案例为例,Redis 采用了 10 分钟的生存时间(TTL)。与此同时,本地内存缓存(Local in-memory cache)也必须设置明确的时间限制,且通常应短于远程缓存的失效时间。如果不设定这一限制,本地缓存极易在无声无息中演变成“永久缓存”。这会导致不同实例之间持续提供陈旧的失效数据,从而破坏系统的数据一致性。
public ProductService(RedisClient redis, ProductDb db) {this.redis = redis;this.db = db;this.localCache = Caffeine.newBuilder() .maximumSize(50_000) .expireAfterWrite(Duration.ofMinutes(1)) // shorter than Redis .build(); }public ProductInfo getProductInfo(String productId) { ProductInfo local = localCache.getIfPresent(productId); if (local != null) return local; ProductInfo redisValue = redis.get(productId); if (redisValue != null) { localCache.put(productId, redisValue); return redisValue; } ProductInfo dbValue = db.fetch(productId); redis.set(productId, dbValue, Duration.ofMinutes(10)); // localCache is configured with expireAfterWrite(1, MINUTES) localCache.put(productId, dbValue); return dbValue;}这种设计模式的核心逻辑在于:将绝大多数的访问请求驱动至“快速路径”(Fast Path)中,而将高耗时的重负载操作预留在“冷路径”(Cold Path)处理。[此处输入链接的描述][3]
缓存失效:计算机科学中最难的问题(依然如此)
缓存驱动的系统,如果没有清晰的失效策略,就是定时炸弹。
常见三类策略:
不存在通用最优解,取决于数据变更频率与过期成本。
数据分级:不是所有数据都适合缓存
真实系统里,数据必须分类处理:
何时该严谨,何时该宽松?
缓存策略取决于数据的类型……例如:
产品目录 → 采用宽松的 TTL(生存时间)即可(允许数据过时);
价格与优惠 → 采用更严谨的 TTL 或基于事件驱动的更新;
支付与余额 → 绝不缓存,或者仅缓存令牌化/聚合后的版本。
进行简单的分类检查,即可保护工程团队免于意外违反合规性要求。
if (data.isRestricted()) { throw new UnsupportedOperationException("Cannot cache PCI/PII data");}熔断器:别让缓慢的依赖项拖累你的下游长尾延迟
响应速度变慢是导致 p99 延迟峰值的最大诱因之一。一个依赖项并不需要完全宕机才会引发麻烦——持续的高延迟就足以造成破坏。如果每个请求都在等待一个性能恶化的下游调用,你就会开始耗尽线程、积压队列,从而将局部减速演变为大范围的长尾延迟问题。
熔断器(Circuit Breaker)的作用是在你的服务与不稳定的依赖项之间划定一道边界。当错误率或超时超过阈值时,熔断器会开启并暂时停止向该依赖项发送流量。这使系统从“等待并积压”转变为一种可预测的结果:快速失败并执行降级逻辑(Fall back),从而保持你自身 API 的响应能力。
Resilience4j:轻量级防护方案:
CircuitBreakerConfig config = CircuitBreakerConfig.custom() .failureRateThreshold(50) .slidingWindowSize(20) .waitDurationInOpenState(Duration.ofSeconds(5)) .build();CircuitBreaker cb = CircuitBreaker.of("recs", config);Supplier<List<Recommendation>> supplier = CircuitBreaker.decorateSupplier(cb, () -> recClient.getRecs(userId));try { return supplier.get();} catch (Exception ex) { return Collections.emptyList(); // fast fallback}当熔断器开启(Open)时:
请求快速失败($< 1$ 毫秒)
不会阻塞任何线程
API 保持稳定
降级:有时“快但不完整”胜过“慢但完美”
降级方案(Fallbacks)能够在依赖项缓慢或不可用时,保持你的“快速路径”完好无损。其核心目的不在于假装一切正常,而在于防止下游的迟缓耗尽你的延迟预算。在许多用户流程中,快速交付一个稍微降级的响应,远比延迟交付一个完美的响应要好。
降级方案应当遵循的原则。
提供有用的内容:即便不是完整数据,也要有参考价值。
具有可预测的快速响应:降级路径本身不能慢。
不产生额外负载:避免在系统已经吃紧时增加负担。
逻辑简单易懂:便于排查问题和维护。
超时(Timeouts)是设计的一部分。如果下游超时被设定为“几秒钟”,它会悄无声息地摧毁一个“低于 100 毫秒”的目标。超时设置必须与你之前设定的延迟预算以及依赖项的 p95/p99 表现相匹配——特别是在扇出(fan-out)路径中,一个缓慢的调用就足以主导整个长尾延迟。
以下示例展示了如果无法快速组装完整页面,则返回缓存快照。这之所以行之有效,是因为它建立在早前讨论过的缓存策略之上——再次提醒,低延迟是全局性的(预算、缓存、超时和韧性模式协同工作):
public ProductPageResponse getPage(String productId) { try { return fetchFullPage(productId); } catch (TimeoutException e) { return fetchCachedSnapshot(productId); // warm, minimal, safe }}降级方案并不能消除故障,但当系统变慢时,它们能有效地界定并限制对用户的影响。
数据分区:减少热点与长尾峰值
分区(Partitioning)能够减少锁争用、缩小索引扫描范围并提高数据局部性。
以下是一个按地域进行数据分区的简单示例:
CREATE TABLE orders_us PARTITION OF orders FOR VALUES IN ('US');CREATE TABLE orders_eu PARTITION OF orders FOR VALUES IN ('EU');应用层需要进行相应的更新,以有效利用分区:
String table = region.equals("US") ? "orders_us" : "orders_eu";return jdbc.query("SELECT * FROM " + table + " WHERE user_id=?", userId);对于读密集型的 API 系统而言,分区是必不可少的。
可观测性:让速度可衡量
高性能系统不仅仅是优秀架构的产物,更是持续可观测性的结果。如果不知道系统在真实流量下何时何地发生了偏移,那么延迟预算、熔断器、缓存层、线程池……这些都毫无意义。
关于低延迟最大的神话就是“一旦实现,大功告成”。事实恰恰相反:除非你主动守护,否则速度会随时间衰减。
这就是为什么高效的工程团队将可观测性视为“一等公民”——它不是调试工具,而是一种持续的性能治理机制。
衡量关键指标:p50, p95, p99 及更多
大多数仪表盘自豪地显示“平均延迟”,这在分布式系统中几乎是毫无用处的。用户真正感受到的是长尾延迟:
p50 → “典型用户”
p95 → “运气稍差的用户”
p99 → “如果这种情况经常发生,就会弃用你产品的客户”
如果你的 p50 是 45ms,但 p99 是 320ms,那么你的系统并不快,它只是偶尔表现不错。
高性能系统追求的是可预测性,而非仅仅是平均值。
使用 Micrometer 进行监控埋点
Micrometer是现代 Java 系统指标衡量的事实标准,它让延迟监控变得极其简单。
以下是为一个 API 端点添加 Micrometer 计时器的示例:
@Autowiredprivate MeterRegistry registry;public ProductInfo fetchProduct(String id) { return registry.timer("api.product.latency") .record(() -> productService.getProductInfo(id));}仅需这一行代码,就能生成:
p50, p90, p95, p99 直方图
吞吐量(每秒请求数)
观测到的最大延迟
用于仪表盘的时间序列数据
SLO(服务水平目标)消耗率信号
还可以添加自定义标签(Custom Tags)以获得更深层次的洞察:
registry.timer("api.product.latency", "region", userRegion, "cacheHit", cacheHit ? "true" : "false");我们内部遵循的一条规则是: 为所有可能影响延迟的因素打标签。 包括:地域、设备类型、API 版本、缓存命中/未命中、是否触发降级等。
这创造了语义化可观测性,与盲目的指标监控截然不同。
分布式追踪:低延迟系统的“真理血清”
指标(Metrics)告诉你某件事花了多长时间,而追踪(Tracing)则告诉你为什么花这么久。
通过使用 OpenTelemetry + Jaeger,你可以映射整个请求的旅程:
Span span = tracer.spanBuilder("fetchProduct") .setSpanKind(SpanKind.SERVER) .startSpan();try (Scope scope = span.makeCurrent()) { return productService.getProduct(id);} finally { span.end();}在 Jaeger 中可视化后,你会看到:
网关处理时间
业务逻辑执行时间
并行调用情况
走缓存路径还是数据库路径
下游延迟
序列化耗时
通过这种方式,团队可以发现那些仪表盘无法揭示的延迟漏洞,例如:
“数据库没问题,但 Redis 每小时会出现一次峰值。”
“API 网关在解析 Header 上就花了 10 毫秒。”
“高峰时段出现了线程池饥饿。”
SLO 与延迟预算:让团队保持诚实的护栏
正如之前讨论的,延迟预算只有在团队对其进行衡量和强制执行时才有效。
一个典型的 SLO(服务水平目标):
目标:p95 < 120 ms
周期:滚动 30 天
错误预算:允许 5% 的请求超过该阈值
SLO 消耗率(Burn Rate)衡量的是你消耗错误预算的速度。消耗率为 1 意味着你正以预期的速度消耗预算(恰好在周期结束时用完);任何大于 1 的数值都意味着消耗过快。当消耗率飙升时,团队应放缓新功能发布,优先处理性能修复(如回滚、减负、优化热点路径、修复缓慢依赖项等)。这是防止“亚 100 毫秒”目标沦为随时间流逝的空谈最实用的方法之一。
一个非常有用的消耗率告警规则:
如果 10 分钟内的消耗率 > 14.4,则触发告警。解读:14.4 是常用的“快速消耗”阈值——如果保持这个速度,你将在约 2 天(50 小时)内用完 30 天的预算,因此必须紧急处理。
它是如何防止问题波及用户的: 消耗率告警的设计初衷是在早期就触发——此时性能退化可能还很轻微,或者仅局限于一小部分流量。这为你争取到了时间去暂停或回滚发布,并在性能下滑演变为大规模、持续性的故障之前修复根本原因。团队通常会将此机制与渐进式交付(灰度/金丝雀发布)及合成监控(Synthetic Checks)配合使用。但其核心关键在于:消耗率告警是一种原生基于 SLO 的早期预警,它直接与用户感知的延迟指标挂钩。
线程池可观测性:隐藏的延迟杀手
线程池是最容易意外破坏延迟预算的地方之一。它们看起来像是性能优化的利器(“并行化下游调用”),但在高负载下会变成瓶颈:线程饱和、队列增长、请求开始等待,原本的“异步扇出”悄然变成了背压(Backpressure)和长尾延迟峰值。最棘手的是,这并不总是表现为 CPU 高占用,而往往表现为等待。
如果没有对线程池饱和度和队列增长的可见性,你只会在 p99 爆炸后才察觉问题。对你的线程池进行埋点:
ThreadPoolExecutor executor = (ThreadPoolExecutor) pool;registry.gauge("threadpool.active", executor, ThreadPoolExecutor::getActiveCount);registry.gauge("threadpool.queue.size", executor, e -> e.getQueue().size());registry.gauge("threadpool.completed", executor, e -> e.getCompletedTaskCount());registry.gauge("threadpool.pool.size", executor, ThreadPoolExecutor::getPoolSize);如果你观察到:
活跃线程数 == 最大线程数
队列持续增长
拒绝次数(Rejection count)增加
……那么你的异步扇出正在演变为异步堆积,这将导致:
重试
超时
连锁式缓慢
p99 的彻底崩溃
在低延迟环境中,线程池监控是不可逾越的底线。
可观测性并非仪表盘——它是一种文化
最重要的洞察在于文化层面:
团队对自身的延迟负责;
每周例行审查仪表盘;
SLO 驱动工程优先级;
性能退化触发故障复盘;
缓存命中率像可用性(Uptime)一样被追踪;
每一次变更都评估“性能爆炸半径”。
高性能系统能保持速度,唯一的初衷是团队在不断地“审视”它。
超越架构:组织如何保持 API 响应速度及未来趋势
构建一个亚 100 毫秒的 API 充满挑战,但随着系统增长保持其一致的速度则更难。随着时间推移,功能蔓延、新依赖、流量模式变化和组织变动都会合力拖慢系统。架构提供了基础,但长期的性能源于习惯、所有权以及将延迟视为头等大事的文化。
来自现实世界系统最可靠的经验很简单:只有当团队视性能为每个人的职责时,快速的系统才能保持快速。
文化让性能长青
高性能组织将性能视为共同责任,而非单纯的后端问题。工程师在设计评审时会常规性地询问:“这增加了多少跳(Hops)?”、“这可以缓存吗?”、“对 p99 最坏的影响是什么?”。当出现问题时,他们实践无责学习:分析长尾延迟、优化模式、调整 SLO 并加强护栏。在这种文化中,性能不是一个特殊项目,而是日常工作方式。
来自真实低延时系统的惨痛教训
在生产环境中反复出现的模式:
线程池会悄无声息地摧毁一切:池子过小导致饥饿,过大导致 CPU 颠簸。配置不当的异步任务池是 p99 爆炸的首要原因。
缓存失效(Invalidation)比缓存命中更关键:只有数据正确时,命中才有意义。如果无法安全地失效,宁可慢一点也不要提供过期结果。
波动比速度更伤人:一个始终保持 50ms 的依赖,远比一个在 10ms 到 300ms 之间波动的依赖更安全。可预测性胜过原始吞吐量。
物理距离胜过算法优化:跨地域调用始终是高延迟的根源。让读取靠近用户,比任何索引技巧都重要。
这些教训构成了“工程肌肉记忆”,正是这种记忆,将那些能够持续保持速度的团队,与那些只能昙花一现实现高性能的团队区分开来。
应避免的反模式
即使是成熟的系统也会掉入预想中的陷阱。
将分段测试环境(Staging)的延迟视为有参考意义的数据。
在没有隔离的情况下过度使用响应式模式。
在在热点路径(Hot path)上进行同步日志记录。
在 API 网关中放置过多的业务逻辑。
使用一个巨大的单体缓存而非多层缓存。
这些反模式会导致“缓慢漂移”,细小的退化不断累积,直到 p99 彻底崩溃。
低延迟系统的下一个前沿
未来十年的快速系统将由智能、自适应的行为定义。
基于实时延迟的自适应路由:请求将自动路由到实时长尾延迟最低的地域、分片或实例。
AI 辅助预测:模型将预测缓存未命中、流量峰值和依赖项恶化,从而实现抢占式优化。
预测性缓存预热:系统利用访问模式,在流量高峰到来前数分钟或数秒预热缓存。
边缘原生执行(Edge-Native):关键逻辑和预计算视图将持续向用户端迁移,使“全球 < 50ms”成为可能。
核心总结:架构是蓝图,文化是引擎
架构可以让你的系统变快,而文化是保持速度的引擎。
那些像监控正确性一样监控 p99、带着延迟预算进行设计、并从退化中学习的团队,才是那些能够在大规模环境下持续交付“瞬时体验”的团队。
持续的低延迟不是运气——它是跨越时间、团队和技术,做出的每一个微小且严谨的决策的结果。
原文链接:




