
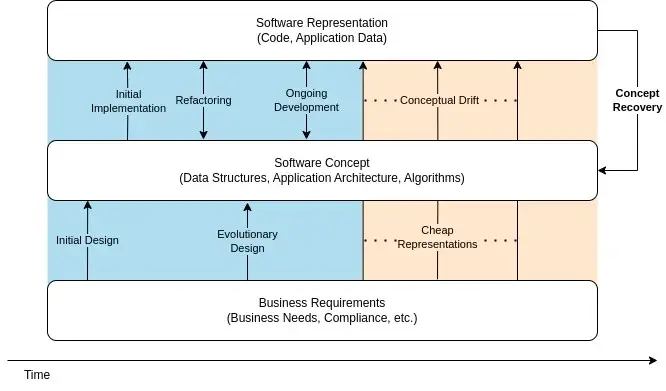
在《没有银弹》一文中,Fred Brooks 认为,只有解决了软件工程的基本复杂性,才能实现软件开发生产力的数量级提升。对他来说,软件工程的基本复杂性在于对软件“相互锁定的部件”的“概念化”。相比之下,在实现中“表示”所选择的概念这一任务相对简单。
如今广泛采用的 AI 辅助软件开发工具,如 Copilot、aider 和 cline,能够在给出某个概念的自然语言描述时轻松生成对应的表示。然而,如果 Brooks 是正确的,这些工具只解决了软件工程的偶然复杂性,而不是“规范、设计和测试[概念结构]”的基本复杂性。
本文分享了我们如何利用大型语言模型帮助我们揭示和增强软件背后概念结构的经验与见解。我们讨论了这些方法如何解决软件工程的固有复杂性,并提升大型、复杂软件现代化项目成功的概率。
遗留系统现代化和概念恢复问题
在遗留系统中,正确对软件概念化是尤为困难的。根据定义,遗留系统是指那些虽已过时但仍在使用的系统,它们成为了业务的关键部分,但大多数工程师不太熟悉它们。
这些系统特别容易受到业务和软件之间的概念漂移的影响。
随着软件变得难以更改,企业可能会选择容忍概念漂移或通过其运营来补偿。当修改软件的难度带来了足够的业务风险时,企业就会进行遗留系统现代化工作。
遗留系统现代化工作展示了概念恢复这一问题。在这些情况下,无论要做出任何更改,都要面临“恢复一个软件系统的底层概念”这一需要大量人力工作的瓶颈。
没有它,企业可能会面临现代化失败,或失去一部分依赖未知或未充分考虑的功能的那些客户的风险。
比如一家最初只向零售客户销售商品的电子商务公司。后来,该公司为批发客户创建了一个独立的业务部门,受其自己的折扣和计费规则的约束。如果新批发业务部门的软件直接依赖于零售业务的实现,就可能发生概念漂移。新批发业务的功能将根据零售业务的规则实现,这样就没法对两个业务部门各自的独立概念建模了。
在经历了大量概念漂移后,对复杂软件的垂直切片进行现代化改造是困难的,因为这些概念往往是庞大、微妙且隐蔽的。幸运的是,利用大型语言模型的技术在概念恢复方面提供了很多帮助,为现代化工作提供了新的加速器。
AI 助力软件现代化
任何软件开发工作的目标都是减少代码的部署周期时长,同时保持可容忍的错误率。我们着手在现代化过程中的多个点开发 AI 干预措施,以减短周期,即使是复杂系统也是如此。在这里,我们主要关注设计阶段的干预措施,这些措施在商业 AI 工具中基本上没有实施。
以完全自动化的方式一起使用所有干预措施,提供了一种快速制作原型和探索解决方案的方法,例如探索多种系统架构的变体。一个认真的现代化工作项目将需要人类专家来适应和验证 AI 生成的输出,但我们发现,使用 AI 减少的劳动负担可以降低工作风险并让项目更加系统化。
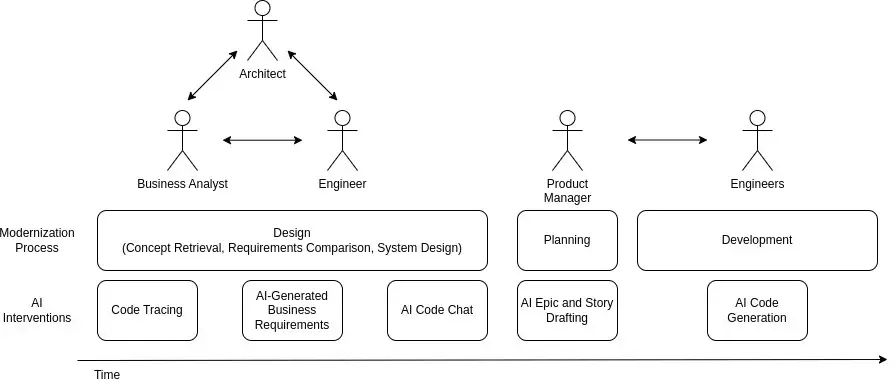
设计阶段的干预
软件现代化设计阶段的目标是执行足够的方法验证,这样才能开始规划和开发,同时尽量减少由于遗漏信息可能导致的返工量。传统上,人们需要在设计阶段花费大量的前期时间来检查遗留源代码、生成目标架构和收集业务需求。这些活动是耗时的、相互依赖的,通常是现代化的瓶颈步骤。
在探索如何使用 LLMs 进行概念恢复时,以有效地服务于执行遗留现代化的团队时,我们遇到了三个挑战:需要哪些上下文以及如何获得它,如何组织上下文以便人类和 LLMs 都能利用它,以及如何支持需求文档的迭代改进。我们下面描述的解决方案可以组合在一起,形成一个管道,以解决这些挑战。
代码追踪为 LLMs 识别相关上下文
什么是追踪?
为了设计用于收集用于现代化任务的有价值代码上下文的工具,我们观察了工程师如何使用现代代码编辑器和静态分析工具来探索他们不熟悉的代码库。工程师使用关键字搜索、正则表达式和源树命名约定来在围绕特定任务的代码库中定位自己的正确入口点。软件绘图工具可以帮助他们可视化软件的结构,像 go-to-definition 和 find-all-references 这样的编辑器功能可以帮助读者浏览相关的代码部分。
通常来说,识别入口点对于架构师和工程师来说是一项低强度的任务,他们习惯于理解软件的高层结构。然而,通过追随代码库中的引用来评估功能和结构是需要大量人力的。因此,我们专注于构建一种追踪代码的方法,目的是将其提供给大型语言模型。
一个“追踪”描述了对抽象语法树(AST)的系统性遍历,结果是一个树状结构,它定义了与现代化任务相关的代码上下文。要执行一个追踪,我们选择一个起点和停止标准,后者反映了重写策略。例如,对于一个表单驱动的应用程序,重写策略可能是“冻结”表单和数据库层,但重写两者之间的所有业务逻辑。一个有价值的追踪将从表单类开始,并在具有数据库访问的节点终止,通过预定义的引用深度来限制返回的代码量。
我们评估了各种工具来解析代码并执行追踪。编译器工具链提供了针对特定语言的 API,而像 tree-sitter 和 ANTLR 这样的工具可以解析多种编程语言,并提供一致的 API。对于我们的工作,我们基于 Roslyn 编译器的 API 构建,因为它为 VB 和 C#.NET 应用程序返回详细的类型信息。我们的语法树遍历器存储了当前符号的类型、其源代码以及与其他符号的关系等详细信息。
收集代码上下文
我们对提供给 LLM 的代码上下文的格式做了实验。AST 包含了代码中每个符号的细节,这可能导致非常细粒度的数据,例如赋值语句的值。基于先前关于LLM代码摘要的研究,我们预计如果提供原始源代码,LLM 将生成更好的代码摘要。因此,我们对比了 markdown 格式的代码上下文与原始 AST。我们使用 H3 标题来标记我们的 markdown 格式代码上下文中每个方法或类的名称。与此同时,我们的 AST 格式类似于嵌套的 ASCII 树结构。我们发现,使用 markdown 格式时,LLM 的摘要更完整。AST 通常产生更技术性的响应,这些响应往往过于详细,以至于损害了整体的连贯性。
收集数据库上下文
在遍历语法树的同时,我们还使用 ANTLR 解析源代码中的 SQL 语法来追踪数据库依赖项。如果发现 SQL,我们解析表和存储过程的名称,并将它们存储在节点上。追踪完成后,我们将收集到的表和存储过程名称与应用程序数据库的 SQL 模式转储进行比较。这使我们能够生成一个 markdown 格式的数据库上下文文件,描述被追踪代码触及的模式部分。与我们的代码上下文类似,每个表或存储过程都收到了一个 H3 标签,后面跟着相关的模式或 SQL。
追踪的好处
追踪的系统性质有助于识别代码和数据库上下文,比手动跳转引用和总结代码的效率更高。我们合作的架构师需要花费一周或更长时间跳转代码,陷入循环,在这一过程中努力理解代码库。相比之下,追踪可以在几分钟内完成,系统化、基于规则的过程为分析代码提供了一种结构化和可重复的方式。
让人类和 LLM 都能用上这些上下文
可视化追踪
架构师和工程师要求提供可视化追踪的代码和数据库上下文的方法,以便他们更好地理解它们的架构和设计。我们为追踪创建了导出功能来实现这一需求。它将代码和数据库上下文序列化为 PlantUML 格式的类、序列和实体关系图。我们尝试提示 LLM 直接从代码和数据库上下文中生成 PlantUML。然而这样做的结果是不可靠的。即使在 50k token 长度的中等上下文下,LLM 也会丢失细节,并且无法一致地遵循 PlantUML 语法。
我们还发现 PlantUML 标记本身就是有用的 LLM 上下文。类图的标记让 LLM 理解了基于代码符号之间的结构关系。与其依赖 LLM 推断两段代码之间的关系,不如使用 PlantUML 中的显式引用,其增加了响应的可靠性。同样,实体关系图总结了应用程序依赖的存储层部分,这带来了更技术性的响应。因此,我们将 PlantUML 标记包含在了发送给 LLM 的代码和数据库上下文中的类和实体关系图中。
恢复业务需求
为了解决概念恢复的核心问题,我们提示 LLM 使用我们收集的代码和数据库上下文生成业务需求文档(BRD)。遵循提示工程的最佳实践,我们设计了一个对技术和非技术背景用户都有用的单一提示。输出包括了总体概述、功能需求、用户界面描述和参考。下面对此做了总结。
在我们与经常从事软件现代化任务的工程师交谈时,我们了解到每个现代化工作项目都可能需要定制化的输出。例如,一些现代化工作需要将某些功能准确从源系统复制到目标系统。目标也可能是淘汰老化的基础设施或淘汰不再支持的语言和框架。在这些情况下,提取功能测试用例特别有价值。其他现代化工作包括对新功能或行为修改的支持。在这些情况下,BRD 可以用来理解通往期望状态的可行路径,因此功能测试用例的价值较小。
由于我们的上下文大小(通常>150k token)大于许多前沿模型的上下文限制,我们设计了一种迭代提示策略。首先,我们估计了我们上下文的 token 计数。然后,我们将上下文分割成可管理的大小,通常约为 50k token,然后迭代提示每个块的摘要。为了估计 token 数,我们使用了 tiktoken。然而,一个简单的经验法则,如 1 个 token 等于 4 个字符,也适用于这个目的。关键是确保我们的分块不会分割代码或数据库上下文的样本。我们会检测代码上下文文件中的 markdown 分隔符,以防止这种情况。
一旦所有块都处理完毕,我们使用专用的合并提示词将输出合成为单个响应。这个提示包括思维链推理、所需部分的检查表,以及检查每个部分完整性的请求。如果你的上下文可以装进一条提示里,我们建议你从这种方法开始。随着长上下文模型(见 Gemini Flash 和 Lllama 4 模型)和推理能力的进展,迭代提示这种方法可能最后就用不着了。
AI 代码聊天使深入查询成为可能
我们收到的反馈是,最初的 BRD 往往会引发一些后续问题。通常,这些后续问题的答案对初始 BRD 来说是宝贵的补充或更新。我们为这些任务尝试了检索增强生成(RAG)方法。然而,RAG 可能需要相当大的调整以确保高搜索相关性,因此我们倾向于那些不需要它们的解决方案,因为我们的用户有不同的查询模式。例如,工程师和架构师关心代码引用,而业务分析师和产品经理对语义含义感兴趣。同时为这两组用户优化是很困难的,因此我们专注于解决用户提出的一些特定后续任务。
任务 1:合并两个 BRD
为了合并两个追踪的 BRD,我们采用了之前描述的迭代提示技术来管理大上下文窗口。通常,用户希望现有的 BRD 用更新的上下文进行更新,因此我们使用合并步骤用更新追踪的细节来更新原始 BRD。这个过程的总成本可能很高。其成本与追踪拉入的代码和数据库上下文的数量成线性关系,加上合并步骤的额外成本。然而,它将 LLM 的注意力集中在每个块上,保留了两个追踪的最佳细节。
任务 2:寻找其他相关上下文
为了找到可能超出初始追踪范围的相关源代码,我们尝试将存储库中的所有代码分解到方法级别,并使用CodeBERT创建嵌入,这些嵌入存储在向量数据库中以供检索。这形成了一个简单的 RAG,用户可以搜索与感兴趣过程或行为相关的代码片段。将最靠前结果返回给用户可以帮助他们寻找代码的入口点,但这种实现有几个缺点。首先,结果返回时没有任何上下文,使用户难以判断其相关性。其次,整体搜索相关性很低。我们发现这个功能不够可靠,无法实现一个真正的自动化 RAG,这种自动化 RAG 中的代码片段被检索、增强并代表用户提交给 LLM。
任务 3:针对当前追踪的目标查询
为了实现对追踪中的代码的目标查询,我们尝试了对整个上下文的迭代查询(见任务 1)和在向量数据库中索引代码(见任务 2)。迭代查询方法产生了更全面的响应,但比使用向量数据库检索更昂贵。我们预计,长上下文模型的进步将进一步提高将大上下文作为单个提示提交的实用性。
总结
将严谨、系统的方法如静态分析与 AI 摘要相结合,可以为现代化提供新的、定制化的方法。自动化和检查静态分析的输出能力,帮助人类专家自信地执行工作,而 LLM 摘要大大减少了准备冗长文档的辛劳。这些优势将来自不同背景的合作者带入软件现代化的过程中。只有当软件团队理解了遗留软件背后的概念,他们才能有效地重写它——无论是否使用 AI 工具。
原文链接:AI Interventions to Reduce Cycle Time in Legacy Modernization




