
亚马逊云科技最近宣布 Amazon MemoryDB 向量搜索功能全面可用,这是一款具备多区域可用性的托管内存数据库。这项新功能提供了超低延迟和在 AWS 所有向量数据库中具有最高召回率的快速向量搜索性能。
Amazon MemoryDB 于 2021 年推出,是一款与 Redis 兼容的持久性内存数据库。目前,它已成为 AWS 上向量搜索的首选托管解决方案,尤其适合那些对峰值性能要求极高的应用场景,如生成式 AI 应用程序。亚马逊云科技开发者布道师 Channy Yun 写道:
有了 Amazon MemoryDB 的向量搜索,你可以使用现有的 MemoryDB API 来实现包括检索增强生成(RAG)、异常(欺诈)检测、文档检索和实时推荐引擎在内的生成式 AI 应用场景。你还可以使用 Amazon Bedrock 和 Amazon SageMaker 等人工智能和机器学习服务生成向量嵌入,并将它们存储在 MemoryDB 中。
开发人员可以使用 Amazon Bedrock 和 SageMaker 等托管服务生成向量嵌入,并将它们存储在 MemoryDB 中,从而实现 RAG 的实时语义搜索、低延迟持久性语义缓存和实时异常检测。
MemoryDB 的向量搜索 支持存储数百万个向量,保证查询响应时间在个位数毫秒级别,并在维持最高吞吐量的同时,提供极低的更新延迟,召回率超过 99%。Yun 补充道:
使用 MemoryDB 的向量搜索功能,你可以将基于批量机器学习模型识别出的欺诈交易,连同正常交易数据一起加载到 MemoryDB 中,通过主成分分析(PCA)等统计分解技术生成它们的向量表示,从而有效地进行欺诈检测。
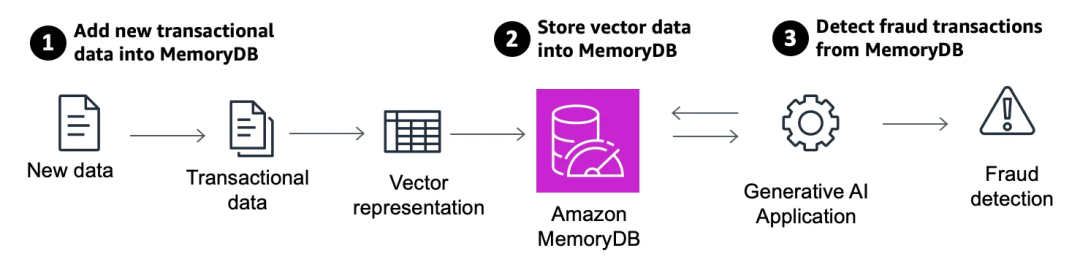
这项新功能在 2023 年的 re:Invent 大会上首次以预览版的形式亮相,最近的全面可用带来了一系列新功能和改进,包括 VECTOR_RANGE,使得数据库能够以极低延迟运行,同时保持持久性语义缓存,以及 SCORE,它提供了更精细的相似性过滤能力。向量字段支持使用平面搜索(FLAT)和分层可导航小世界(HNSW)算法对固定大小的向量进行 K 最近邻搜索(KNN)搜索。
MemoryDB 并非亚马逊云科技提供的唯一一个支持向量搜索的托管数据库。在过去一年中,为了满足生成式 AI 工作负载的需求,OpenSearch、Aurora PostgreSQL、RDS PostgreSQL、Neptune 和 DocumentDB 纷纷引入了与向量相关的功能。美国银行的软件工程经理 Vinod Goje 评论 道:
我一直在关注向量数据库市场的发展,这个市场正在迅速增长,涌现出许多新产品……专家们认为这个市场变得过于拥挤,使得新产品很难在众多现有选项中脱颖而出。
亚马逊云科技数据库专家解决方案架构师 Shayon Sanyal 和 Graham Kutchek 详细说明了 为生成式 AI 应用程序选择数据库时的关键考虑因素。他们建议:
如果你已经在使用 OpenSearch Service、Aurora PostgreSQL、RDS for PostgreSQL、DocumentDB 或 MemoryDB,那么就充分利用它们内置的向量搜索功能来处理现有的数据。对于基于图的 RAG 应用程序,请考虑使用 Amazon Neptune。如果你的数据存储在 DynamoDB 中,OpenSearch 零 ETL 集成的优势将是你进行向量搜索的极好选择。如果仍然不确定,可以将 OpenSearch Service 作为起点。
最近,各大云服务厂商纷纷推出了自己的向量搜索功能,以与 Pinecone 等向量数据库以及无服务器解决方案,入 Momento Cache 展开竞争。例如,InfoQ 先前就报道了 Google BigQuery 和 Microsoft Vector Search。
向量搜索功能在 Amazon MemoryDB 7.1 中可用,并支持所有数据库可用区域的单分片配置。
原文链接:
https://www.infoq.com/news/2024/08/aws-memorydb-vector-search/




