
本文整理自 字节跳动云原生工程师薛英才分享了 基于分布式 KV 存储引擎的高性能 K8s 元数据存储项目 KubeBrain。
KubeBrain 是字节跳动针对 Kubernetes 元信息存储的使用需求,基于分布式 KV 存储引擎设计并实现的、可以取代 etcd 的元信息存储系统,目前支撑着线上超过 20,000 节点的超大规模 Kubernetes 集群的稳定运行。
项目地址:github.com/kubewharf/kubebrain
分布式应用编排调度系统 Kubernetes 已经成为云原生应用基座的事实标准,但是其官方的稳定运行规模仅仅局限在 5,000 节点。这对于大部分的应用场景已经足够,但是对于百万规模机器节点的超大规模应用场景, Kubernetes 难以提供稳定的支撑。
尤其随着“数字化””云原生化”的发展,全球整体 IT 基础设施规模仍在加速增长,对于分布式应用编排调度系统,有两种方式来适应这种趋势:
水平扩展:即构建管理多个集群的能力,在集群故障隔离、混合云等方面更具优势,主要通过集群联邦(Cluster Federation)来实现;
垂直扩展:即提高单个集群的规模,在降低集群运维管理成本、减少资源碎片、提高整体资源利用率方面更具优势。

K8s 采用的是一种中心化的架构,所有组件都与 APIServer 交互,而 APIServer 则需要将集群元数据持久化到元信息存储系统中。
当前,etcd 是 APIServer 唯一支持的元信息存储系统,随着单个集群规模的逐渐增大,存储系统的读写吞吐以及总数据量都会不断攀升,etcd 不可避免地会成为整个分布式系统的瓶颈。
Kubernetes 元信息存储需求
APIServer 并不能直接使用一般的强一致 KV 数据库作为元信息存储系统,它与元信息存储系统的交互主要包括数据全量和增量同步的 List/Watch,以及单个 KV 读写。更近一步来说,它主要包含以下方面:
在版本控制方面,存储系统需要对 APIServer 暴露数据的版本信息,APIServer 侧依赖于数据的版本生成对应的 ResourceVersion;
在写操作方面,存储系统需要支持 Create/Update/Delete 三种语义的操作,更为重要的是,存储系统需要支持在写入或者删除数据时对数据的版本信息进行 CAS;
在读操作方面,存储系统需要支持指定版本进行快照 List 以此从存储中获取全量的数据,填充 APIServer 中的 WatchCache 或供查询使用,此外也需要支持读取数据的同时获取对应的数据版本信息;
在事件监听方面,存储系统需要支持获取特定版本之后的有序变更,这样 APIServer 通过 List 从元信息存储中获取了全量的数据之后,可以监听快照版本之后的所有变更事件,进而以增量的方式来更新 Watch Cache 以及向其他组件进行变更的分发,进而保证 K8s 各个组件中数据的最终一致性。
etcd 的实现方式与瓶颈
etcd 本质上是一种主从架构的强一致、高可用分布式 KV 存储系统:
节点之间,通过 Raft 协议进行选举,将操作抽象为 log 基于 Raft 的日志同步机制在多个状态机上同步;
单节点上,按顺序将 log 应用到状态机,基于 boltdb 进行状态持久化 。
对于 APIServer 元信息存储需求,etcd 大致通过以下方式来实现:
在版本控制方面,etcd 使用 Revision 作为逻辑时钟,对每一个修改操作,会分配递增的版本号 Revision,以此进行版本控制,并且在内存中通过 TreeIndex 管理 Key 到 Revision 的索引;
在写操作方面,etcd 以串行 Apply Raft Log 的方式实现,以 Revision 为键,Key/Value/Lease 等数据作为值存入 BoltDB 中,在此基础上实现了支持对 Revision 进行 CAS 的写事务;
在读操作方面,etcd 则是通过管理 Key 到 Revision 的 TreeIndex 来查询 Revision 进而查询 Value,并在此基础上实现快照读;
在事件监听方面,历史事件可以从 BoltDB 中指定 Revision 获取 KV 数据转换得到,而新事件则由写操作同步 Notify 得到。
etcd 并不是一个专门为 K8s 设计的元信息存储系统,其提供的能力是 K8s 所需的能力的超集。在使用过程中,其暴露出来的主要问题有:
etcd 的网络接口层限流能力较弱,雪崩时自愈能力差;
etcd 所采用的是单 raft group,存在单点瓶颈,单个 raft group 增加节点数只能提高容错能力,并不能提高写性能;
etcd 的 ExpensiveRead 容易导致 OOM,如果采用分页读取的话,延迟相对会提高;
boltdb 的串行写入,限制了写性能,高负载下写延迟会显著提高;
长期运行容易因为碎片问题导致写性能发生一定劣化,线上集群定期通过 defrag 整理碎片,一方面会比较复杂,另一方面也可能会影响可用性。
新的元数据存储
过去面对生产环境中 etcd 的性能问题,只能通过按 Resource 拆分存储、etcd 参数调优等手段来进行一定的缓解。但是面对 K8s 更大范围的应用之后带来的挑战,我们迫切的需要一个更高性能的元数据存储系统作为 etcd 的替代方案,从而能对上层业务有更有力的支撑。
在调研了 K8s 集群的需求以及相关开源项目之后,我们借鉴了 k3s 的开源项目 kine 的思想,设计并实现了基于分布式 KV 存储引擎的高性能 K8s 元数据存储项目—— KubeBrain 。
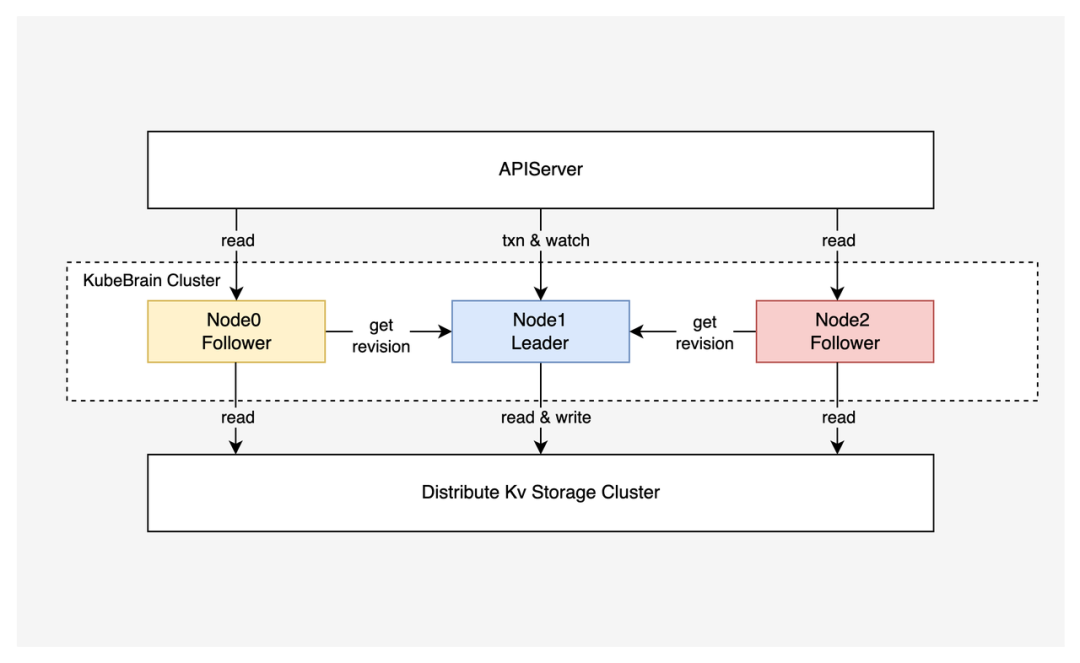
KubeBrain 系统实现了 APIServer 所使用的元信息存储 API ,整体采用主从架构,主节点负责处理写操作和事件分发,从节点负责处理读操作,主节点和从节点之间共享一个分布式强一致 KV 存储,在此基础上进行数据读写。下面介绍 KubeBrain 的核心模块。
存储引擎
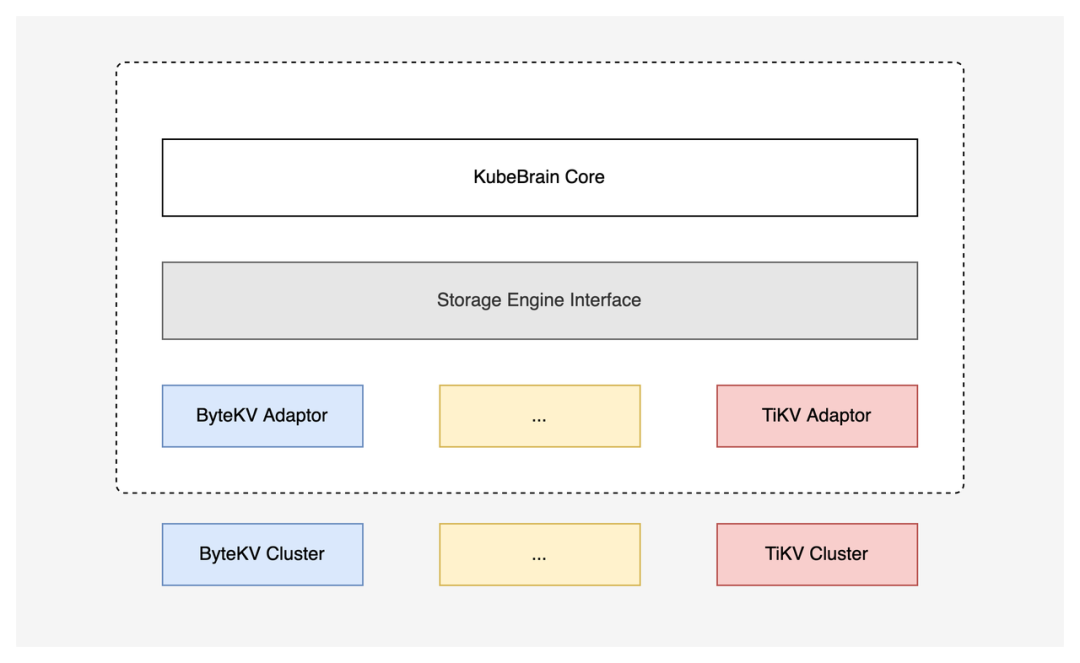
KubeBrain 统一抽象了逻辑层所使用的 KeyValue 存储引擎接口,以此为基础,项目实现了核心逻辑与底层存储引擎的解耦:
逻辑层基于存储引擎接口来操作底层数据,不关心底层实现;
对接新的存储引擎只需要实现对应的适配层,以实现存储接口。
目前项目已经实现了对 ByteKV 和 TiKV 的适配,此外还实现了用于测试的适配单机存储 Badger 的版本。需要注意的是,并非所有 KV 存储都能作为 KubeBrain 的存储引擎。当前 KubeBrain 对于存储引擎有着以下特性要求:
支持快照读
支持双向遍历
支持读写事务或者带有 CAS 功能的写事务
对外暴露逻辑时钟
此外,由于 KubeBrain 对于上层提供的一致性保证依赖于存储引擎的一致性保证, KubeBrain 要求存储引擎的事务需要达到以下级别(定义参考 HATs ):
Isolation Guarantee: Snapshot Isolation
Session Guarantee: Linearizable
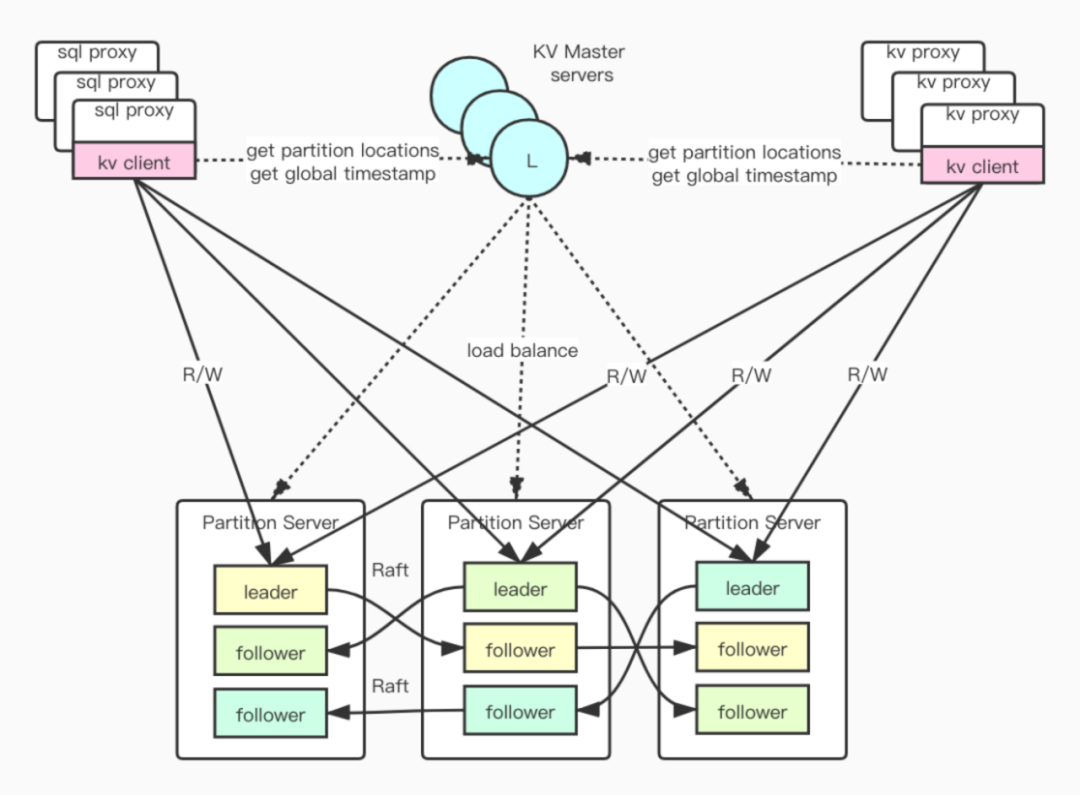
在内部生产环境中, KubeBrain 均以 ByteKV 为存储引擎提供元信息存储服务。ByteKV 是一种强一致的分布式 KV 存储。在 ByteKV 中,数据按照 key 的字典序有序存储。当单个 Partition 数据大小超过阈值时, Partition 自动地分裂,然后可以通过 multi-raft group 进行水平扩展,还支持配置分裂的阈值以及分裂边界选择的规则的定制。此外, ByteKV 还对外暴露了全局的时钟,同时支持写事务和快照读,并且提供了极高的读写性能以及强一致的保证。
选主机制
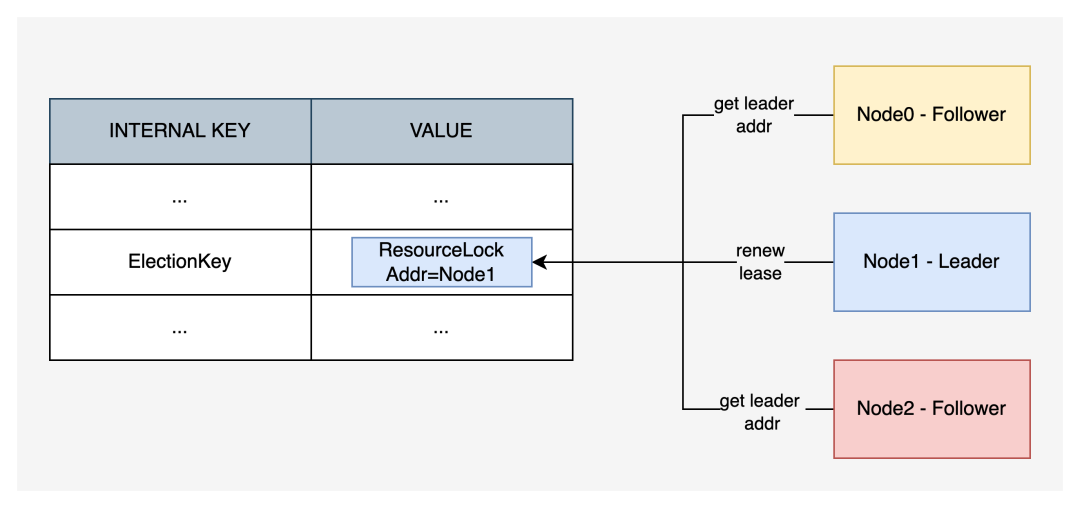
KubeBrain 基于底层强一致的分布式 KV 存储引擎,封装实现了一种 ResourceLock,在存储引擎中指向一组特定的 KeyValue。ResourceLock 中包含主节点的地址以及租约的时长等信息。
KubeBrain 进程启动后均以从节点的身份对自己进行初始化,并且会自动在后台进行竞选。竞选时,首先尝试读取当前的 ResourceLock。如果发现当前 ResourceLock 为空,或者 ResourceLock 中的租约已经过期,节点会尝试将自己的地址以及租约时长以 CAS 的方式写入 ResourceLock,如果写入成功,则晋升为主节点。
从节点可以通过 ResourceLock 读取主节点的地址,从而和主节点建立连接,并进行必要的通信,但是主节点并不感知从节点的存在。即使没有从节点,单个 KubeBrain 主节点也可以提供完成的 APIServer 所需的 API,但是主节点宕机后可用性会受损。
逻辑时钟
KubeBrain 与 etcd 类似,都引入了 Revision 的概念进行版本控制。KubeBrain 集群的发号器仅在主节点上启动。当从节点晋升为主节点时,会基于存储引擎提供的逻辑时钟接口来进行初始化,发号器的 Revision 初始值会被赋值成存储引擎中获取到的逻辑时间戳。
单个 Leader 的任期内,发号器发出的整数号码是单调连续递增的。主节点发生故障时,从节点抢到主,就会再次重复一个初始化的流程。由于主节点的发号是连续递增的,而存储引擎的逻辑时间戳可能是非连续的,其增长速度是远快于连续发号的发号器,因此能够保证切主之后, Revision 依然是递增的一个趋势,旧主节点上发号器所分配的最大的 Revision 会小于新主节点上发号器所分配的最小的 Revision。
KubeBrain 主节点上的发号是一个纯内存操作,具备极高的性能。由于 KubeBrain 的写操作在主节点上完成,为写操作分配 Revision 时并不需要进行网络传输,因此这种高性能的发号器对于优化写操作性能也有很大的帮助。
请求解析数据模型
KubeBrain 对于 API Server 读写请求参数中的 Raw Key,会进行编码出两类 Internal Key 写入存储引擎索引和数据。对于每个 Raw Key,索引 Revision Key 记录只有一条,记录当前 Raw Key 的最新版本号, Revision Key 同时也是一把锁,每次对 Raw Key 的更新操作需要对索引进行 CAS。数据记录 Object Key 有一到多条,每条数据记录了 Raw Key 的历史版本与版本对应的 Value。Object Key 的编码方式为magic+raw_key+split_key+revision,其中:
magic为\x57\xfb\x80\x8b;raw_key为实际 API Server 输入到存储系统中的 Key ;split_key为$;revision为逻辑时钟对写操作分配的逻辑操作序号通过 BigEndian 编码成的 Bytes 。
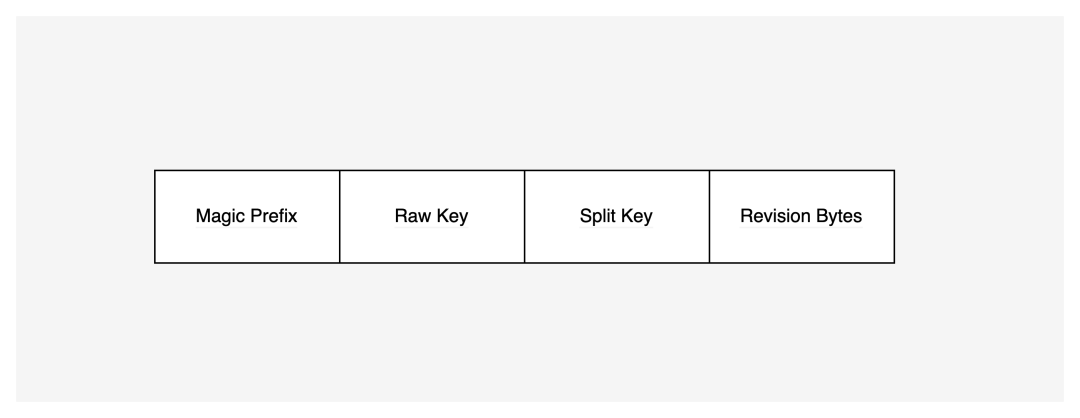
根据 Kubernetes 的校验规则,raw_key 只能包含小写字母、数字,以及'-' 和 '.',所以目前选择 split_key 为 $ 符号。
特别的,Revision Key 的编码方式和 Object Key 相同,revision取长度为 8 的空 Bytes 。这种编码方案保证编码前和编码后的比较关系不变。
在存储引擎中,同一个 Raw Key 生成的所有 Internal Key 落在一个连续区间内 。

这种编码方式有以下优点:
编码可逆,即可以通过
Encode(RawKey,Revision)得到InternalKey,相对应的可以通过Decode(InternalKey)得到Rawkey与Revision;将 Kubernetes 的对象数据都转换为存储引擎内部的 Key-Value 数据,且每个对象数据都是有唯一的索引记录最新的版本号,通过索引实现锁操作;
可以很容易地构造出某行、某条索引所对应的 Key,或者是某一块相邻的行、相邻的索引值所对应的 Key 范围;
由于 Key 的格式非单调递增,可以避免存储引擎中的递增 Key 带来的热点写问题。
数据写入
每一个写操作都会由发号器分配一个唯一的写入 revision ,然后并发地对存储引擎进行写入。在 创建、更新和删除 Kubernetes 对象数据的时候,需要同时操作对象对应的索引和数据。由于索引和数据在底层存储引擎中是不同的 Key-Value 对,需要使用 写事务保证更新过程的原子性,并且要求至少达到 Snapshot Isolation 。
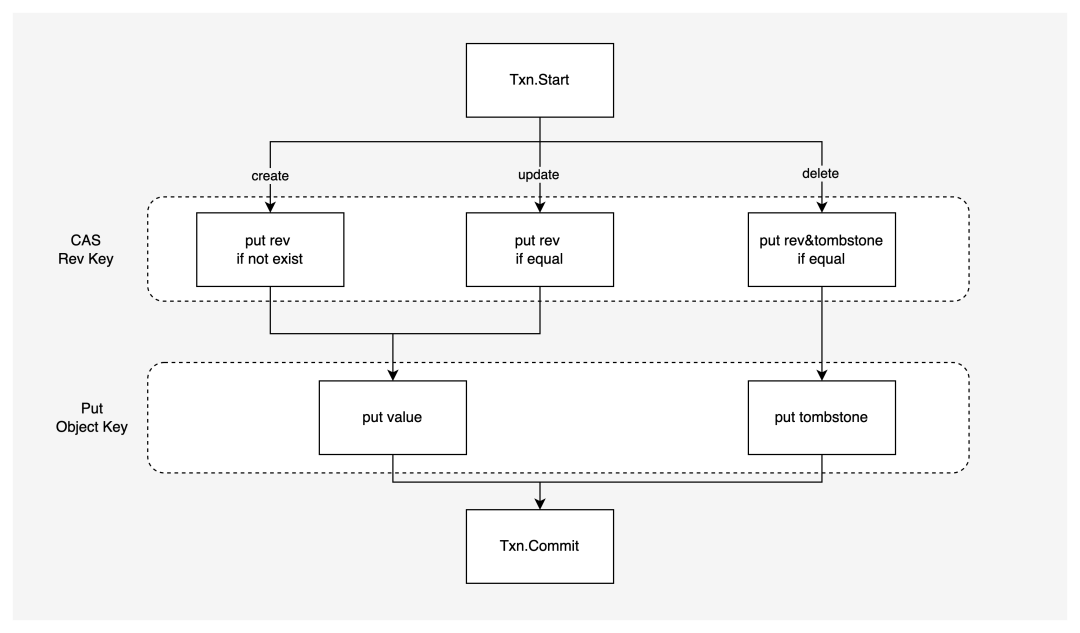
同时 KubeBrain 依赖索引实现了乐观锁进行并发控制。KubeBrain 写入时,会先根据 APIServer 输入的 RawKey 以及被发号器分配的 Revision 构造出实际需要到存储引擎中的 Revision Key 和 Object Key,以及希望写入到 Revision Key 中的 Revision Bytes。在写事务过程中,先进行索引 Revision Key 的检查,检查成功后更新索引 Revision Key,在操作成功后进行数据 Object Key 的插入操作。
执行 Create 请求时,当 Revision Key 不存在时,才将 Revision Bytes 写入 Revision Key 中,随后将 API Server 写入的 Value 写到 Object Key 中;
执行 Update 请求时,当 Revision Key 中存放的旧 Revision Bytes 符合预期时,才将新 Revision Bytes 写入,随后将 API Server 写入的 Value 写到 Object Key 中;
执行 Delete 请求时,当 Revision Key 中存放的旧 Revision Bytes 符合预期时,才将新 Revision Bytes 附带上删除标记写入,随后将 tombstone 写到 Object Key 中。
由于写入数据时基于递增的 Revision 不断写入新的 KeyValue , KubeBrain 会进行后台的垃圾回收操作,将 Revision 过旧的数据进行删除,避免数据量无限增长。
数据读取
数据读取分成点读和范围查询查询操作,分别对应 API Server 的 Get 和 List 操作。

Get 需要指定读操作的ReadRevision,需要读最新值时则将 ReadRevision 置为最大值MaxUint64,构造 Iterator ,起始点为Encode(RawKey, ReadRevision),向Encode( RawKey, 0)遍历,取第一个。

范围查询需要指定读操作的ReadRevision 。对于范围查找的 RawKey 边界[RawKeyStart, RawKeyEnd)区间, KubeBrain 构造存储引擎的 Iterator 快照读,通过编码将 RawKey 的区间映射到存储引擎中 InternalKey 的数据区间
InternalKey 上界
InternalKeyStart为Encode(RawKeyStart, 0)InternalKey 的下界为
InternalKeyEnd为Encode(RawKeyEnd, MaxRevision)
对于存储引擎中[InternalKeyStart, InternalKeyEnd)内的所有数据按序遍历,通过Decode(InternalKey)得到RawKey与Revision,对于一个RawKey相同的所有ObjectKey,在满足条件Revision<=ReadRevision的子集中取Revision最大的,对外返回。
事件机制
对于所有变更操作,会由 TSO 分配一个连续且唯一的 revision ,然后并发地写入存储引擎中。变更操作写入存储引擎之后,不论写入成功或失败,都会按照 revision 从小到大的顺序,将变更结果提交到滑动窗口中,变更结果包括变更的类型、版本、键、值、写入成功与否 。在记录变更结果的滑动窗口中,从起点到终点,所有变更数据中的 revision 严格递增,相邻 revision 差为 1。
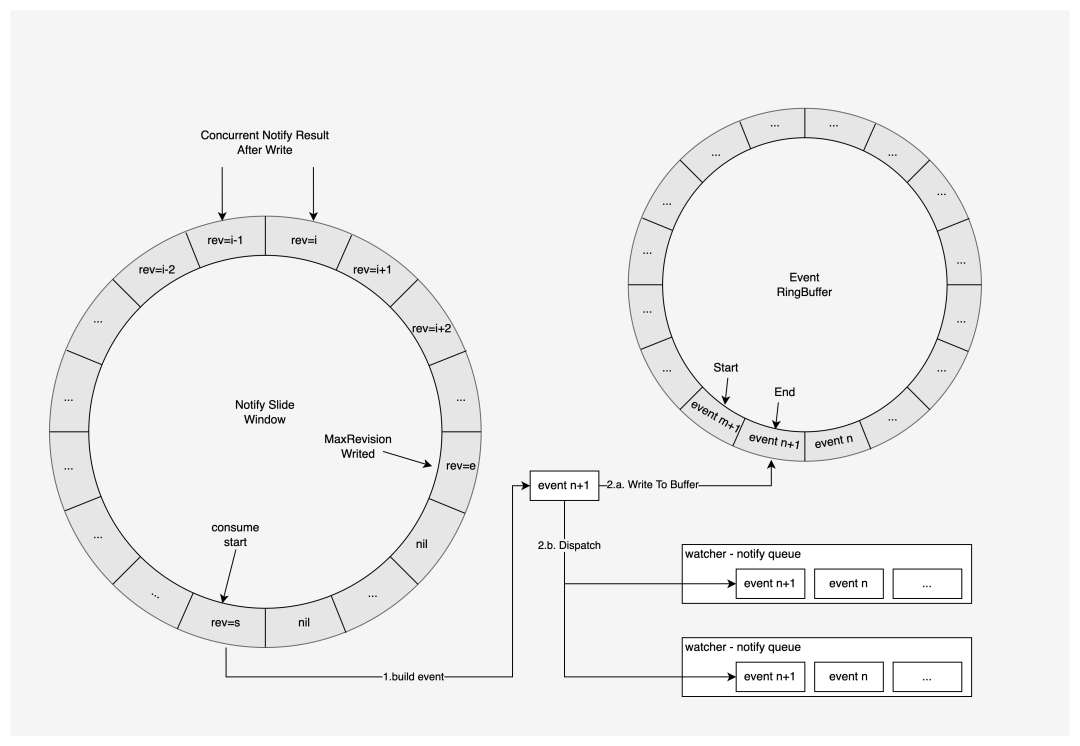
记录变更结果的滑动窗口由事件生成器统一从起点开始消费,取出的变更结果后会根据变更的 revision 更新发号器的 commit index ,如果变更执行成功,则还会构造出对应的修改事件,将并行地写入事件缓存和分发到所有监听所创建出的通知队列。
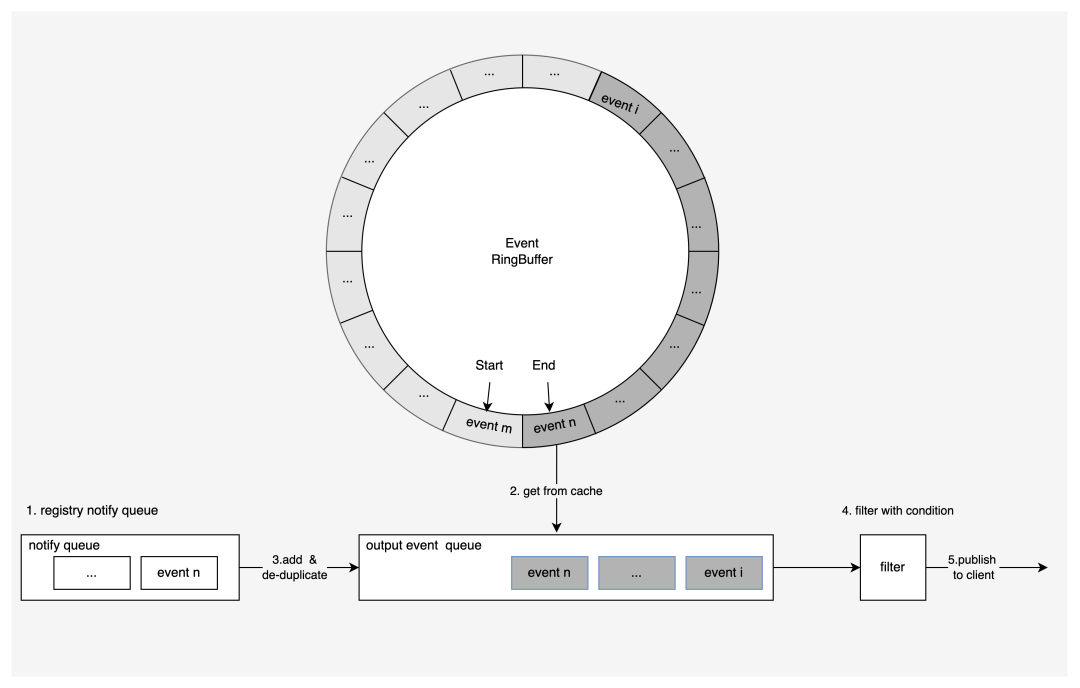
在元数据存储系统中,需要监听指定逻辑时钟即指定 revision 之后发生的所有修改事件,用于下游的缓存更新等操作,从而保证分布式系统的数据最终一致性。注册监听时,需要传入起始 revision 和过滤参数,过滤参数包括 key 前缀等等。
当客户端发起监听时,服务端在建立事件流之后的处理,分成以下几个主要步骤:
处理监听注册请求时首先创建通知队列,将通知队列注册到事件生成组件中,获取下发的新增事件;
从事件缓存中拉取事件的 revision 大于等于给定要求 revision 所有事件到事件队列中,并放到输出队列中,以此获取历史事件;
将通知队列中的事件取出,添加到输出队列中, revision 去重之后添加到输出队列;
按照 revision 从小到大的顺序,依次使用过滤器进行过滤;
将过滤后符合客户端要求的事件,通过事件流推送到元数据存储系统外部的客户端。
落地效果
在 Benchmark 环境下,基于 ByteKV 的 KubeBrain 对比于 etcd 纯写场景吞吐提升 10 倍左右,延迟大幅度降低, PCT 50 降低至 1/6 ,PCT 90 降低至 1/20 ,PCT 99 降低至 1/4 ;读写混合场景吞吐提升 4 倍左右;事件吞吐大约提升 5 倍;
在模拟 K8s Workload 的压测环境中,配合 APIServer 侧的优化和调优,支持 K8s 集群规模达到 5w Node 和 200w Pod;
在生产环境中,稳定上量至 2.1w Node ,高峰期写入超过 1.2w QPS,读写负载合计超过 1.8w QPS。
未来演进
项目未来的演进计划主要包括四个方面的工作:
探索实现多点写入的方案以支持水平扩展 现在 KubeBrain 本质上还是一个单主写入的系统,KubeBrain 后续会在水平扩展方面做进一步的探索,后续也会在社区中讨论;
提升切主的恢复速度 当前切主会触发 API Server 侧的 Re-list ,数据同步的开销较大,我们会在这方面进一步做优化;
实现内置存储引擎 实现两层存储融合,由于现在在存储引擎、KubeBrain 中存在两层 MVCC 设计,整体读写放大较多,实现融合有助于降低读写放大,更进一步提高性能;
完善周边组件 包括数据迁移工具、备份工具等等,帮助用户更好地使用 KubeBrain 。
期待有更多朋友关注和加入 KubeBrain 社区,也欢迎大家在 GitHub 给我们提出各种建议!




