摘要
我在几天内用智能体编程 (Agentic Coding) 构建了一个完整的 AI 应用。
关键的经验是:当数据平台能够原生处理复杂部分时,智能体编程才能真正发挥作用。开源组件、统一的 SQL 接口以及对 AI 友好的工具,是让你能够高效地在现有技术栈上进行构建,而不是与其“搏斗”的关键。
作为 ClickHouse 的解决方案架构师,我一直希望构建一个超越幻灯片和截图的演示,一个能让零售客户立刻代入自身场景的方案:一个名为 ClickShop 的全栈零售分析平台。该应用集实时分析(仪表盘能够在亚秒级查询数十亿行数据)、事务性工作流(订单管理、合同摄取、客户更新)、18 个针对不同业务角色(如 CEO、销售、数据分析师)定制的专业 AI 智能体,以及一个完整的可观测性堆栈于一体。该可观测性堆栈既涵盖了 LLM 追踪(通过 Langfuse 实现提示管理、成本跟踪和评估),也包括了基础设施监控(通过 ClickStack 实现指标、日志和分布式追踪)。我的目标是构建一个足够真实的系统,能够展示给客户并自信地说:“您的生产环境可以就是这个样子。” 然而,挑战在于:我既不是前端也不是后端开发人员,而且我只有几天的时间。这篇博客将详细介绍我是如何构建这个平台的,我做出了哪些架构决策,以及 ClickHouse 数据栈为何能让这一切成为可能。
以下是该应用在实际运行中的界面:一个 CEO 工作区,其中包含实时关键绩效指标 (KPI)、按地理区域划分的营收明细,以及一个能够查询实时 ClickHouse 数据并回答业务问题的 AI 智能体。
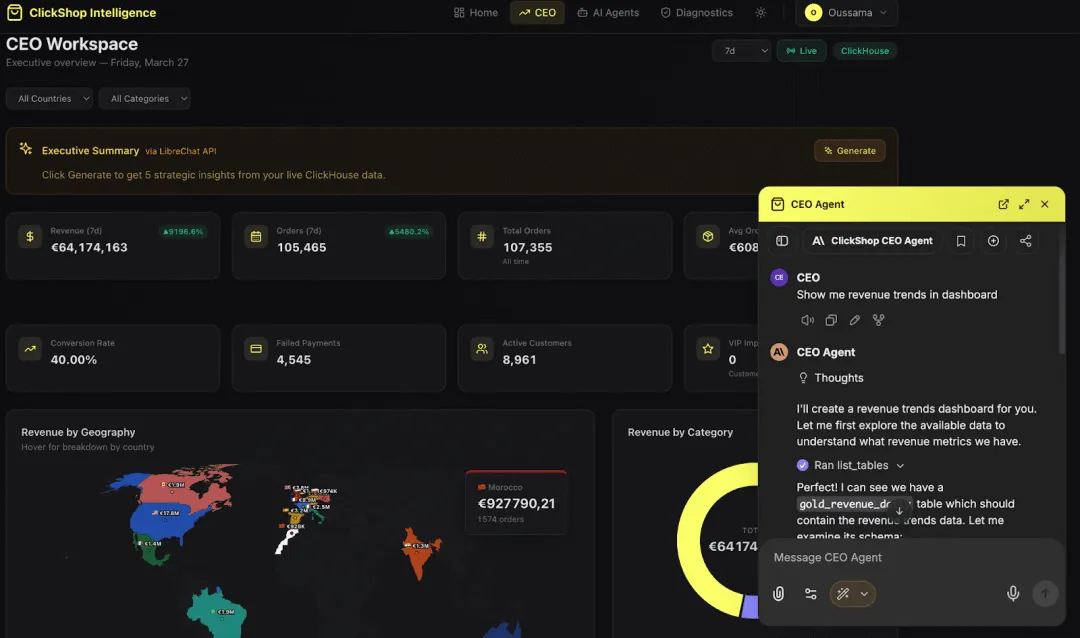
ClickShop 智能界面:高管仪表盘与 AI 智能体接口
待解决的问题
作为一名解决方案架构师,我的大部分时间都用于帮助客户设计数据架构:绘制图表、审查数据模式并解释查询优化。然而,当需要在真实应用场景中展示 ClickHouse 的实际能力时,单纯的幻灯片演示效果有限。我希望构建一个能够让零售客户一目了然,并立即理解该平台如何融入他们现有技术栈的系统。这不是一个简单的“玩具”演示,而是一个能够展现他们日常所需复杂性的真实应用:涵盖分析、事务处理、AI 和监控。
挑战在于,构建这类应用通常需要一个完整的团队耗费数月时间。我两者皆无。于是问题随之而来:一个人,借助 AI 驱动的 IDE 和合适的平台,能否构建出值得信赖的产品?
其架构概览如下:
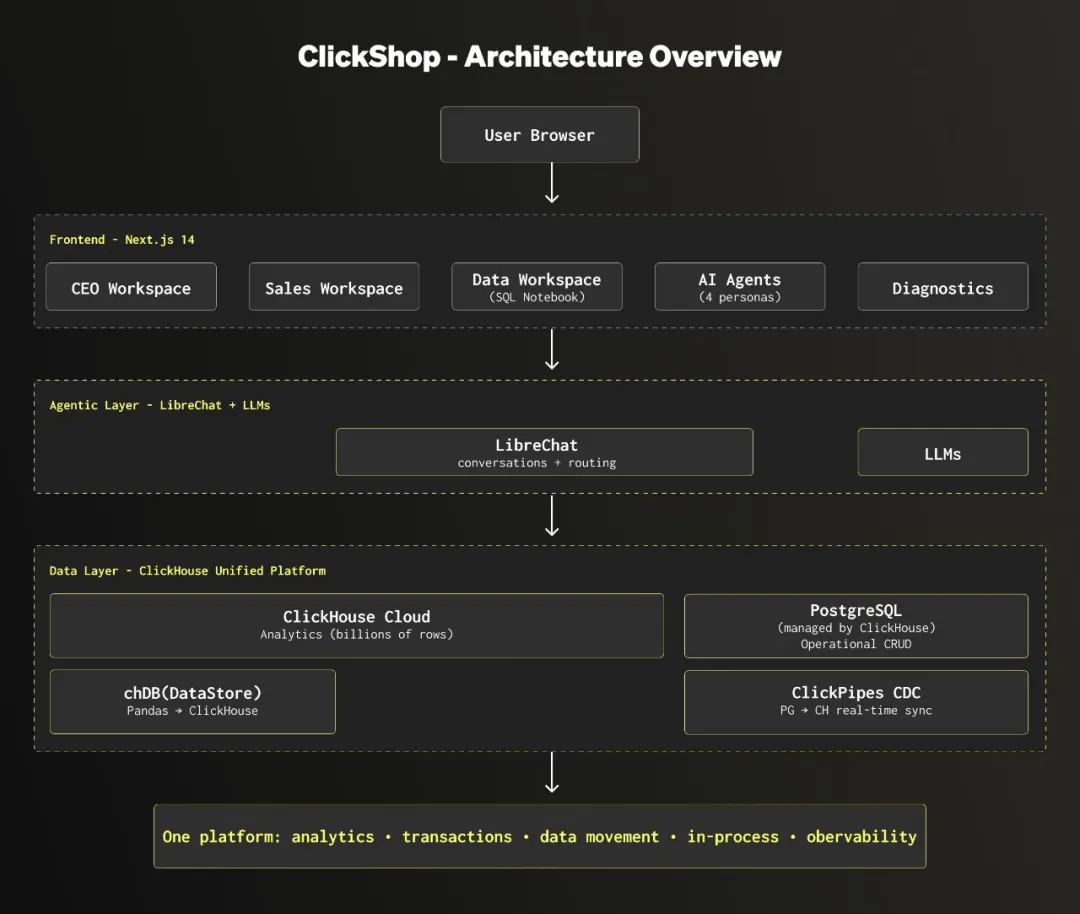
该应用的核心由三个层面构成:
前端层 (Next.js) 为不同业务角色提供定制化工作区。CEO、销售经理、数据分析师等,他们各自拥有专属的仪表板、数据范围和 AI 代理。
数据层 融合了 ClickHouse 和 PostgreSQL 。ClickHouse 负责分析型工作负载,能够实现仪表板和报告所需的数十亿行数据亚秒级查询。PostgreSQL 则处理事务性操作,包括订单管理、客户更新和合同录入。 ClickPipes CDC (Change Data Capture) 负责将 PostgreSQL 的数据变更实时同步到 ClickHouse,确保分析结果始终反映最新状态。对于偏好使用 Python 的数据科学家, chDB (一个进程内 (in-process) ClickHouse 引擎)允许他们运行熟悉的 Pandas 工作流,而实际执行则在底层下推 (push down) 到 ClickHouse。
代理层 ( LibreChat + LLMs) 赋能 18 个专业化的 AI 代理。LibreChat 负责管理对话和路由,每个代理都拥有独立的系统提示 (system prompt)、上下文 (context) 和数据范围 (data scope)。例如,CEO 代理能解释上周收入下降的原因;销售代理可识别当前热门产品;数据代理则协助编写和优化 SQL 查询。
在此基础上,该应用还配备了两个独立的可观察性 (observability) 层。这一区别至关重要,因为对 AI 应用的监控涉及两个截然不同的方面:
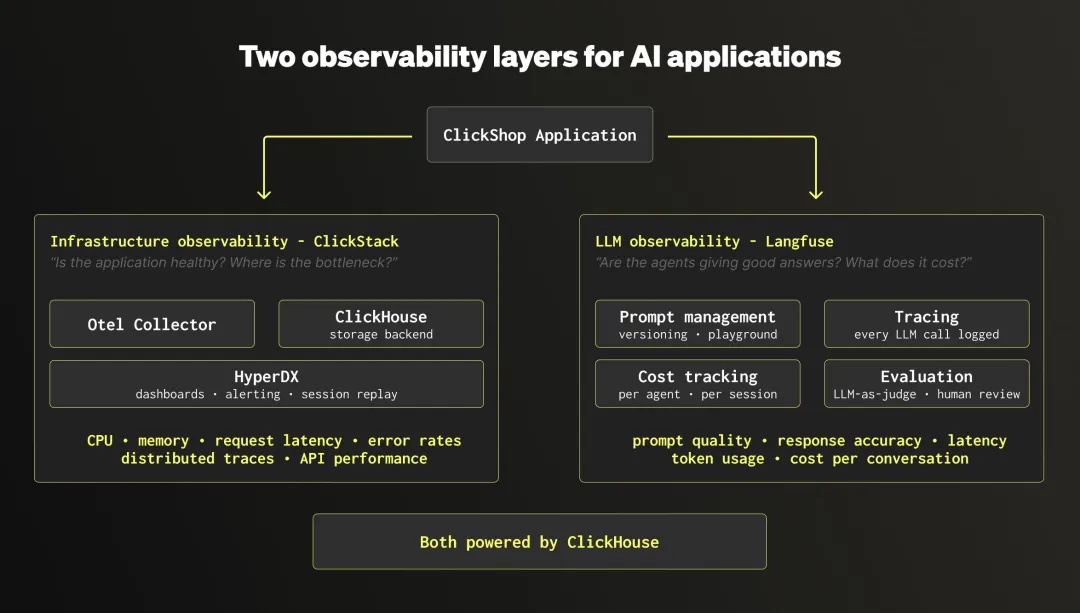
基础设施可观测性 ( ClickStack ):这属于经典的应用程序监控范畴。它通过 OpenTelemetry 收集指标(如 CPU、内存、请求延迟)、日志和分布式追踪,旨在回答以下问题:应用程序是否健康?API 调用是否缓慢?瓶颈究竟位于何处?
LLM 可观测性 ( Langfuse ):这专为 AI 智能体设计。它追踪发送给 LLM 的每个提示 (prompt)、接收到的每个响应、每次调用的成本和延迟,并支持质量评估(包括自动化评分和人工审核)。它旨在回答不同的问题:这些智能体是否提供了高质量的答案?哪些提示需要调优 (tuning)?每次对话的成本是多少?
Langfuse 和 ClickStack 均基于 ClickHouse 运行。结合 ClickHouse Cloud 进行数据分析、由 ClickHouse 管理的 PostgreSQL 处理事务、以及 ClickPipes 负责数据移动,整个技术栈得以在单一平台上运行。
为什么选择智能体编程,又为何是当下?
AI 辅助编程已从最初的好奇心演变为工作流程中的标准组成部分。作为一名解决方案架构师,我注意到相关工具已足够成熟,足以实现我长久以来的一个想法:独立构建一个完整的演示应用,无需依赖工程团队。
此举的动机非常实际。当我与零售客户会面时,交流往往遵循相同的模式:他们希望了解 ClickHouse 如何处理他们的具体用例,这不仅仅是通过基准测试,而是通过一个模拟其真实环境的场景来展现。他们希望看到:具备真实数据的仪表盘、能解答业务问题的智能体,以及能展示底层运行情况的可观测性。幻灯片无法做到这一点,但一个真实运行的应用程序可以。
于是,我决定一试。我选择了 Cursor,这是一款能根据自然语言生成代码的 AI 驱动集成开发环境 (IDE),并为自己设定了一个简单目标:构建一个用于客户会议的零售分析平台,且整个技术栈都运行在 ClickHouse 数据栈之上。
Cursor:AI 驱动的 IDE
本项目中使用的工具是 Cursor,一款能够根据自然语言提示 (prompt) 生成代码的集成开发环境 (IDE)。实际操作中,工作流程如下:您描述需求,Cursor 随即生成代码;您进行审阅,必要时进行调整,随后便可着手下一项功能。
对于本项目,开发循环过程十分直接:
1. 我用自然语言描述一个功能(例如:“创建一个仪表盘,显示过去 30 天按国家划分的收入,查询 ClickHouse”)
2. Cursor 生成前端组件、API 路由和 SQL 查询。
3. 我审查输出,在本地进行测试,并根据需要进行迭代。
4. 功能实现后,我将其推送到 GitHub ,Vercel 便会自动部署。
一个显著的优势在于 ClickHouse 是开源的,并且拥有广泛的文档。大型语言模型(LLMs)已经掌握 ClickHouse SQL、MergeTree 引擎系列等知识。同样,堆栈中的其他开源组件,如 PostgreSQL、LibreChat 和 Langfuse,也具备这一特点。由于这些项目拥有庞大的公共代码库和完善的文档,AI 能够从一开始就生成相关代码,从而减少了反复调整的次数。这是基于开源项目进行构建的一大优势:对于专有闭源数据库,LLMs 无法访问其代码库或内部机制,因此它们更多地是猜测,出错的概率也更高。
Cursor 市场与技能
此外,Cursor 提供了一个市场,用户可以从中安装社区构建的技能(Skills)。技能是小型的知识模块,用于教授 AI 特定工具的最佳实践。在此项目中,我安装了 ClickHouse 最佳实践技能和 Langfuse 技能,这两项技能均可直接在市场中获取。它们能够引导 AI 做出正确的引擎选择、进行适当的模式设计并遵循集成规范,而无需我在每次提示时重复解释。
这里有一个实用技巧:在任何项目结束时,一旦你花费数小时与 Cursor 反复协作并使架构趋于稳固,可以要求 Cursor 将整个对话转化为一项技能。它会记录你所确立的所有决策、模式和约定,因此,当你下次启动类似项目时,便能完全跳过学习曲线。
逐步构建 ClickShop
在本节中,我将逐层讲解应用程序的构建过程。我特意从宏观层面进行阐述,以确保整体方法易于理解和遵循。此处的目的是向您展示项目的全貌。
从数据层开始
我首先着手构建的是数据基础。该应用程序需要处理两种类型的工作负载:事务性工作负载(包括创建订单、更新客户信息、导入合同等)和分析性工作负载(例如,仪表板需要在亚秒级内查询数十亿行数据)。我没有选择两个独立的供应商,而是采用了 ClickHouse 数据栈:由 ClickHouse 管理的 PostgreSQL 用于事务处理,而 ClickHouse Cloud 则负责分析处理。
为了确保所有数据同步,我配置了 ClickPipes CDC。它能够将 PostgreSQL 中的事务数据实时镜像到 ClickHouse 中,且无需管理任何外部管道。在 ClickHouse 环境中,数据遵循 Medallion 架构:镜像的事务数据会首先存储在 Bronze 表中,并与原始事件流汇聚;Silver 表利用物化视图对数据进行清洗和去重;而 Gold 表则对结果进行预聚合,以确保仪表板能够在亚秒级内快速响应查询。
构建前端工作区
数据基础搭建完成后,我使用 Next.js 14 构建了前端界面,并将其部署在 Vercel 上。每个业务角色(persona)都拥有专属的工作区,其中包含根据其特定角色量身定制的仪表板和工具:
CEO 工作区 :展示高管关键绩效指标 (KPIs)、全球收入分布图和趋势分析。
销售工作区 :侧重于销售管道管理、交易详情查询和 PDF 合同导入。
数据工作区 :提供一个交互式 SQL 笔记本,用户可以在其中同时查询 ClickHouse 和 PostgreSQL;此外还集成了 chDB ,这是一个进程内 (in-process) ClickHouse 引擎,它允许数据科学家编写熟悉的 Pandas 代码,而实际执行则在底层下推 (push down) 到 ClickHouse。
诊断页面 :验证所有服务运行状况并允许生成测试数据。
每个工作区都嵌入了各自的 AI 代理 (AI agent),接下来我们将探讨代理层 (agentic layer)。
添加 AI 代理
这些 AI 代理由 LibreChat 提供支持,这是一个集成在 ClickHouse 数据栈中的开源代理平台 (agentic platform)。每个 persona 都拥有其专属的代理,这些代理具备各自的系统提示、数据范围和上下文。例如,CEO 代理专注于宏观业务指标;销售代理擅长处理销售管道和收入相关事务;而数据代理则协助编写和优化 SQL 查询。
除了对话功能,Langfuse 还负责处理 LLM 的可观测性:它能对每个提示进行版本管理,追踪每个代理的响应,按会话记录成本,并通过自动化评分或人工审查来评估质量。
通过可观测性实现闭环
我添加的最后一层是通过 ClickStack 实现的基础设施可观测性。应用程序通过 OpenTelemetry 收集器将指标、日志和分布式追踪导出到 ClickHouse。在此之上,ClickStack 提供仪表盘、告警和会话回放功能。这意味着,当用户加载仪表盘或向代理提问时,我能准确了解发生了什么:包括调用了哪个 API,ClickHouse 查询耗时多久,以及响应是否被缓存。
结合 Langfuse 提供的 LLM 可观测性,这为应用程序带来了两个互补的监控层:一个用于基础设施,一个用于 AI。这两个监控层都运行在 ClickHouse 上。
构建 ClickShop 所用的提示
既然大家对整体架构已有所了解,下面我将分享一些用于构建各层的提示。为了让本文更侧重于方法和架构,我在此对这些提示进行了简化。后续文章将更深入地介绍完整的提示、代码示例和实现细节。
关键在于,好的提示应该像给同事的指令,而非代码。注入的领域知识越多,输出效果就越好。

数据层
"我需要 PostgreSQL 来存储我的业务操作数据(包括客户、产品、订单和支付信息),而 ClickHouse 则用于分析数据(例如页面浏览、购物车事件、结账事件、支付事件和订单事件)。请设计能够反映真实电商平台的 Schema。"
这正是领域知识发挥关键作用之处。我预先明确了双数据库策略,然后 Cursor 为每种数据库引擎生成了正确的 DDL。对于 ClickHouse,它应用了恰当的 ORDER BY 键、LowCardinality 和 TTL 策略;对于 PostgreSQL,它则创建了带有外键和索引的关系型 Schema。
我还从 Cursor 市场安装了两个 MCP 连接器:一个用于 ClickHouse,另一个用于 PostgreSQL。MCP 允许 Cursor 直接连接到每个数据库实例,自动发现其 Schema,并执行查询,我甚至无需打开数据库控制台。这意味着无需使用 clickhouse-client,也无需 psql。
前端工作区
“为我构建一个具有深色/浅色主题的 Web 应用程序。我需要为 CEO、销售经理和数据分析师提供独立的工作区。添加一个着陆页和一个导航栏。”
这个单一的提示就生成了项目的结构、样式、布局和导航。在此基础上,每个工作区都逐步构建,并拥有各自的仪表盘、数据范围和嵌入式 AI 智能体。
AI 智能体
“将 LibreChat 添加到项目中。我希望它嵌入到每个工作区中,用于自由交流,并作为 API 为专用智能体提供支持,每个智能体都能回答关于我数据的特定问题。”
LibreChat 扮演着双重角色:iframe 为用户提供自由形式的聊天体验,而其 API 则驱动着执行特定任务(如欺诈检测、管道健康状况、收入分析、查询优化)的专用智能体。每个智能体都拥有自己的系统提示和数据范围。
通过可观测性实现闭环
“为 LibreChat 智能体集成 Langfuse,它具有原生集成能力。对于 ClickStack,我希望对每个组件实现全面的可观测性:涵盖整个技术栈中每个服务名称的链路追踪、日志、指标和会话回放,并全部通过 OpenTelemetry 发送。”
在大语言模型(LLM)方面,Langfuse 与 LibreChat 实现了原生集成:只需配置少量环境变量,无需编写自定义代码。每次智能体交互都会自动进行追踪,包括会话上下文、提示版本、成本追踪和评估分数。在基础设施方面,ClickStack 则收集分布式追踪、指标、结构化日志和会话回放,所有数据均存储在 ClickHouse 中,并可通过 SQL 进行查询。
部署
“将此项目推送到 GitHub 并部署到 Vercel。确保环境变量已配置。”
Cursor 创建了代码仓库,推送了代码,并配置了 Vercel 部署。此后每次 git push 操作都会触发自动重新部署。
提示中未展示的内容
读完这篇博客,你可能会认为 Agentic 编程是从提示到结果的一步到位过程。并非如此。我上面展示的每个简洁提示背后,都经过了多次迭代,其中 AI 曾误解意图、重构了我不曾要求改动的部分,或是生成了在本地运行正常但在生产环境中却出现问题的代码。你花费在审查和纠正上的时间可能比预期的要多。Agentic 编程虽然速度快,但并非线性发展。本博客中简化的提示只反映了成功的部分,而非完整的探索历程。每一次迭代都有其成本。每次 agent 调用、每次提示重试、每次对话都会消耗 token。Langfuse 的重要性便凸显于此:它能跟踪每个 agent、每个会话、每个用户的成本,从而让你了解预算开销,并识别哪些提示需要优化。
平台的重要性
如果说这个项目能让你从中汲取一点启示,那就是:你所依赖的平台直接影响了你的架构是简单还是复杂。
大多数数据平台并非设计用于直接服务应用程序。它们在并发访问下会面临性能瓶颈,难以同时处理混合工作负载(分析型和事务型),并常常迫使你额外增加缓存层或中间件,仅仅是为了维持可接受的响应时间。随着用户和 agent 数量的增加,架构承受的压力也随之增大。最终,你不得不绕开数据库的限制进行开发,而非在其之上充分构建。
借助 ClickHouse 数据栈,我无需处理上述任何问题。ClickHouse Cloud 负责处理分析型工作负载。由 ClickHouse 管理的 PostgreSQL 负责处理事务。ClickPipes 在二者之间原生同步数据,无需额外搭建外部数据管道。LibreChat 提供 Agentic 层,Langfuse 提供 LLM 可观测能力,ClickStack 提供基础设施监控。所有这些组件都是开源的,它们的数据均存储在 ClickHouse 中,且均支持 SQL。架构之所以保持简单,是因为技术栈保持一致。正如我之前提到的,所有组件都是开源的,这意味着 AI 已经能够很好地理解并与之协作。ClickHouse 也投入大量资源,致力于构建 Agent 友好型技术栈,包括:MCP 连接器、IDE 技能,以及基于 LibreChat 和 Langfuse 构建的完整 Agentic 数据栈。
这使得将智能体编程 (Agentic Coding) 用于构建数据密集型应用成为可能。当你的数据平台能够原生处理这些复杂任务,并且 AI 能够深度理解该平台时,你就可以将精力集中在产品本身,而非繁琐的底层“管道”工作上。由于需要协调的环节更少,迭代速度也会加快。最终,你将得到一个真正能够投入生产的应用,因为它的底层基础就是为此而设计的。
构建于数据之上,而非底层“管道”工作
ClickShop 最初只是一个用于客户会议的演示项目。但它逐渐演变为一个更重要的证明:一个人,凭借合适的数据技术栈 (data stack) 和 AI 驱动的集成开发环境 (IDE),就能在几天内构建一个涵盖分析、事务、AI 智能体 (AI agents) 和可观测性 (observability) 的全栈应用 (full-stack application)。
如果你是一名开发者或构建者,正在寻找一个数据平台来赋能你的下一个项目,我希望本文能为你描绘出一种具体的可能性。ClickHouse 不仅仅是一个快速的分析引擎 (analytics engine)。它是一个完整的数据技术栈,你可以在其中运行事务 (transactions)、移动数据、监控基础设施、追踪大型语言模型 (LLM) 调用,并使用 SQL 查询所有数据。正是这种极致的简洁性,带来了非凡的差异化体验。
现在,轮到你了。选择一个用例,打开你喜欢的 AI 编程工具 (AI coding tool) (如 Cursor、Claude Code、Codex 或任何你偏好的工具),然后开始在 ClickHouse 数据技术栈之上构建你的应用吧。
/END/
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出 &图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com。






