
背景
近期,大量用户反馈系统在运行过程中出现 CPU 利用率与系统负载(load)突发性飙升,甚至引发系统短时卡顿(持续数秒至数十秒)的问题;对于业务来说,轻则导致几百毫秒的抖动,重则连机器都无法 ssh 上去。经分析发现,此类异常现象普遍存在一个显著特征:均发生在系统内存占用率接近阈值(90%-95%)时。用户就发出了灵魂拷问:
“水位这么高了,为什么内核不触发 OOM 杀掉一些进程来释放内存?"
“我宁愿内核 OOM 把我业务进程杀了,我也不希望应用卡顿和系统夯机影响我其他业务!”
其实这个现象的核心原因就是:内核想确保应用实在没内存用了才 OOM。
思想总体是正确的,但是一条思想要满足所有场景也是非常难的。
为什么还不 OOM?
内存水位这么高,为什么还不 OOM!其实主要是由于系统进入了 Near-OOM 状态。现在,我们先回顾一下 Linux 的内存回收机制,如下图所示:
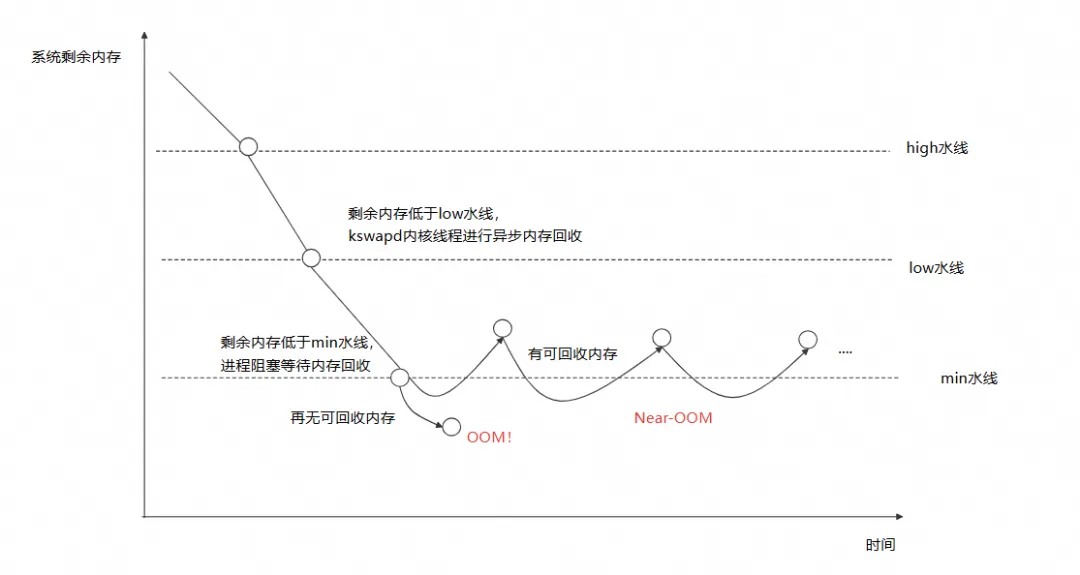
Linux 划分了 high、low、min 三个内存水线。当系统剩余内存低于 low 水线后,内核会唤醒 kswapd 进程会被唤醒开始进行异步的内存回收,此时对系统没什么影响;系统剩余内存低于 min 水线后,内核会阻塞要分配的内存进程尝试尽可能地回收所有可回收的内存(主要是文件缓存以及一些内核结构体缓存),回收的过程中可能涉及到将文件缓存写入磁盘或遍历一些内核结构体,从而导致系统负载飙高、应用被阻塞。如果能成功回收内存并满足申请需求则不触发 OOM。
更糟糕的是,系统可能进入一种 Near-OOM 的活锁状态,即内核一边在尝试回收文件缓存;但是应用运行过程中从磁盘加载代码段等行为也在不断产生文件缓存,那么就会使整个系统负载持续飙高,甚至发生夯机。
所以,内核 OOM 的策略在业务延时敏感的场景,还是太保守了。
那么如果我们希望宁愿 OOM 把我业务进程杀了,我也不希望应用卡顿和系统夯机影响我其他业务?还有什么办法呢?
新 OOM 方案
为了应对 Near-OOM 现象,核心就是“快” OOM,在内核还在犹豫要不要 OOM 的时候,我们就替他做出决定!目前业界已有的方案主要是通过用户态提前杀死相关进程来提前释放内存,比如应用较为广泛的是 Facebook(Meta)推出的 oomd。oomd 目前已经集成于 systemd 中成为 systemd-oomd,且从 Ubuntu 22.04 开始集成于 Ubuntu 中。但是 oomd 方案存在以下问题:
与 cgroupV2 以及 Linux 内核的 PSI(Pressure Stall Information)特性深度绑定。但 cgroupV1 目前仍然是云计算中主流 cgroup 版本,且由于 PSI 功能有一定的性能开销,在大部分云计算场景中都是默认关闭的。
只支持以 cgroup 为粒度杀进程,配置 cgroup 级别的杀进程策略。
所以 oomd 在适用性和灵活性上仍有欠缺。
为了解决上述问题,阿里云操作系统控制台推出了 FastOOM 功能,支持节点以及 Pod 级别的用户态 OOM 配置,通过提前介入杀进程的方式避 Near-OOM 导致的抖动夯机。
FastOOM 同样采取用户态提前杀进程的形式来避免系统进入 Near-OOM 状态,主要分为采集预测模块和 kill 模块:采集预测模块会从阿里云自研操作系统中读取内存压力相关的指标,通过统计学方法对 OOM 发生的概率进行实时预测并判定当前节点或 pod 是否达到相应的内存压力或即将进入 Near-OOM 状态。kill 模块会根据用户配置的杀进程策略,选取对应的进程杀死。
最终所有由 FastOOM 执行的 kill 操作事件都会上报到控制台中心端进行展示,让用户方便了解底层的实际操作(不用担心 FastOOM 偷偷杀死了其他进程)。
(表/FastOOM 与 oomd 对比)
使用 FastOOM 避免 Near-OOM 系统夯机抖动
场景一:配置节点级别策略解决系统 Near-OOM 抖动夯机问题
客户遇到的问题
某汽车行业发现某实例上业务长时间无响应、登录实例也十分卡顿。通过监控发现客户实例使用的内存在某个时间点开始徒增,接近系统的总内存(即 available 非常低),但没有超过系统总内存。
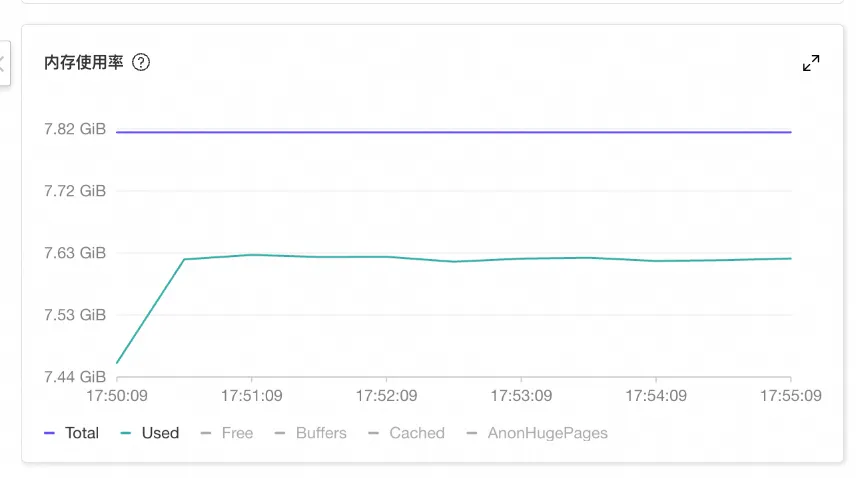
通过 top 命令可以看到系统的 CPU sys 利用率和 iowait 利用率和系统负载都持续飙高,kswapd0 线程占用非常高的 CPU 进行内存回收。
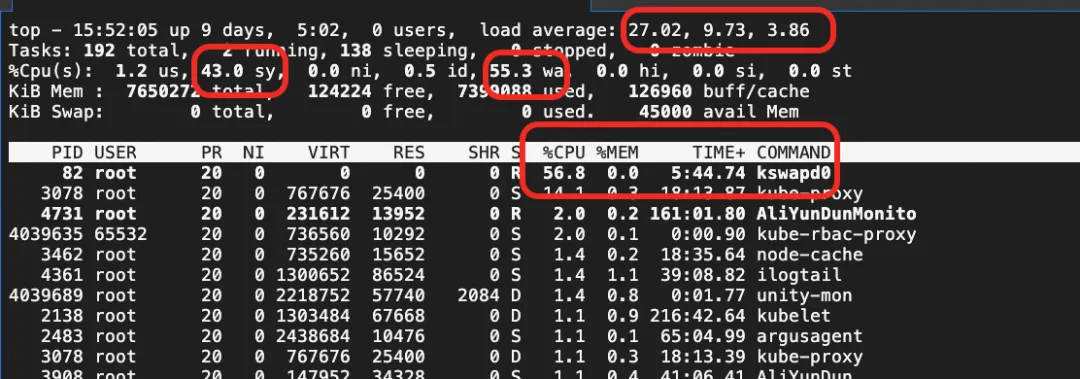
通过操作系统控制台的系统概览可以看到,在发生 OOM 夯(即处于 Near-OOM 状态)的同时,也发生了用户态收包延时,业务发生了抖动。

解决方案
通过配置开启节点级别的 FastOOM 功能,由于业务是实验较为敏感的业务,内存压力选择中,且设置业务程序(以 python 启动,进程名包含 python 子串)为避免被 OOM 进程且设置无关的日志程序优先杀死。
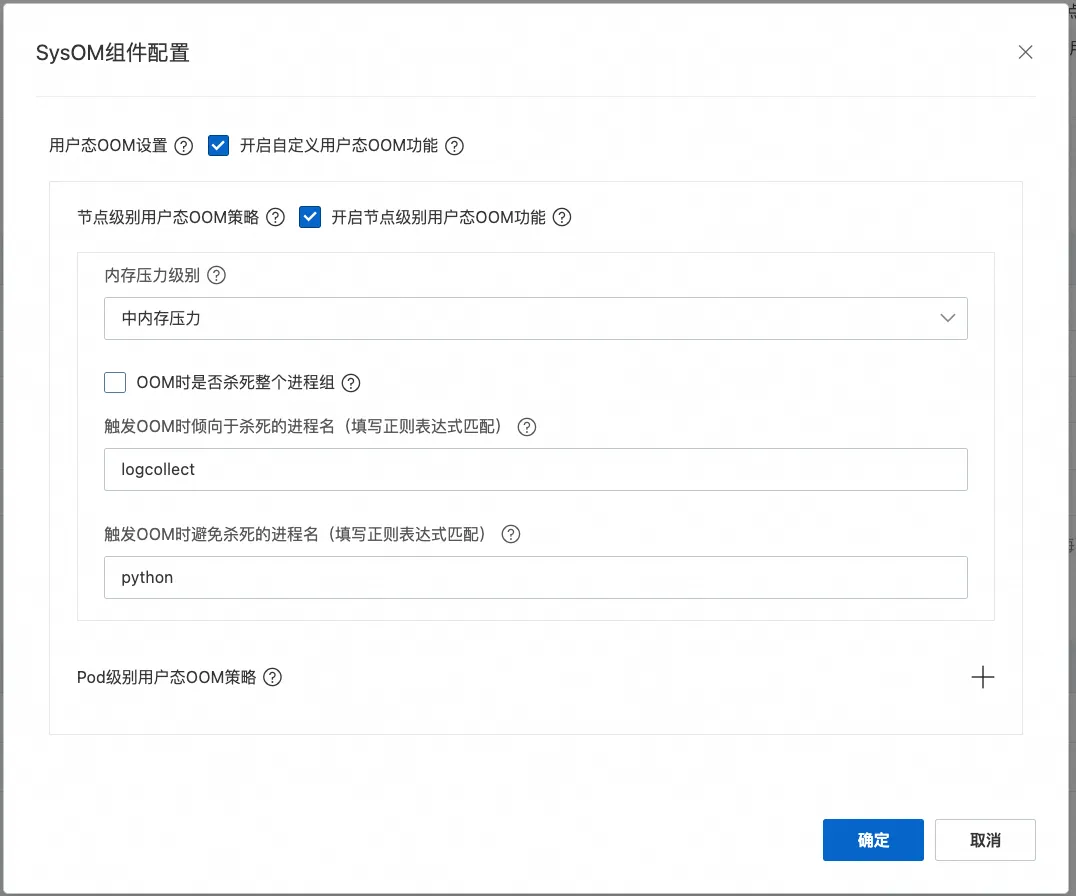
开启后,当节点内存水位处于 Near-OOM 状态时,用户态提前介入,根据配置杀死了如下进程,从而释放了部分内存避免系统进入了夯机状态。通过操作系统控制台的系统概览可以看到 FastOOM 介入的相关记录。
如下图所示,由于 kube-rbac-proxy 和 node_exporter 等进程 oom_score_adj 被设置为接近 999,FastOOM 会匹配内核策略优先杀死这些进程,但是由于杀死这些进程后释放内存较小,仍处于 Near-OOM;因此 FastOOM 杀死了配置优先杀死的 logcollect 进程。

由于用户态及时介入杀死进程释放出内存,使系统避免进入了 Near-OOM 的抖动状态。
案例二:配置 Pod 级别策略解决 Pod 应用抖动夯机问题
客户遇到的问题
在 Kubernetes 环境中,我们是可以为 Pod 中的容器配置对应的内存限制的,和节点 OOM 同理,如果 Pod 中的内存使用接近限制时,内核也会尝试回收 Pod 中所有可回收内存,才触发 OOM,这时候也会导致 Pod 内业务进程的延时阻塞。
某大数据客户会部署一些延时敏感的业务 Pod(即 Pod 中运行了多个业务进程)。业务时不时会存在响应长尾延时,但是网络相关指标一切正常。
后面我们接手问题后,通过 Alibaba Cloud Linux 自研指标(该指标反映容器由于内存回收阻塞的时长)发现,存在非常高的内存回收延时,且时间节点和抖动时间匹配:
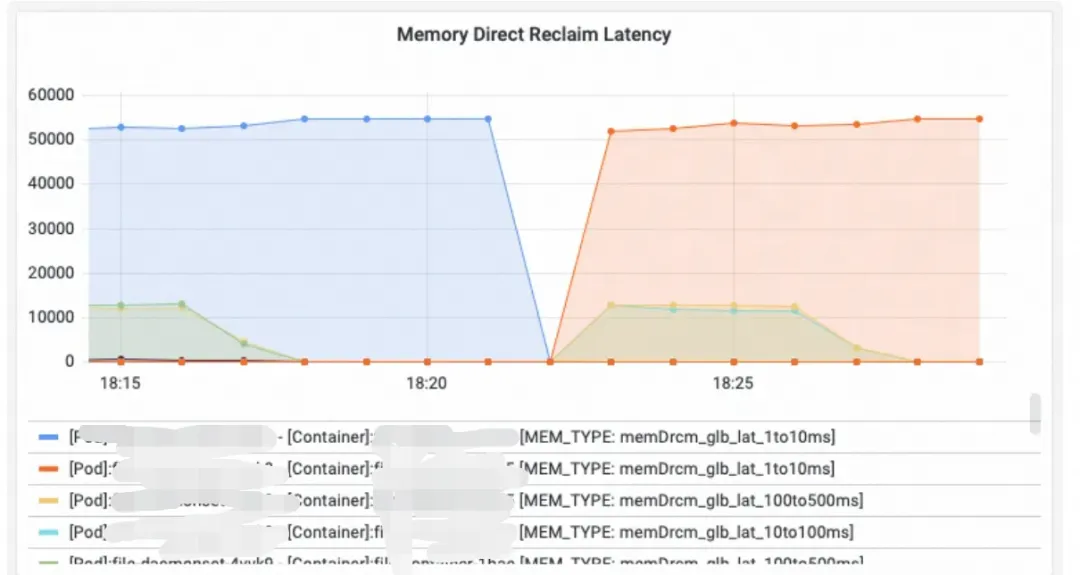
推荐客户配置 Pod 级别的 FastOOM 后,通过提前杀死 Pod 中的相关内存占用进程,避免了内存回收延时的发生,抖动也不再出现。
解决方案
操作系统控制台提供较为灵活的 Pod 级别的 OOM 杀进程策略配置,可以灵活配置 Pod 中容器内发生 OOM 时,避免和优先杀死的进程。
假设在集群中通过名为 test-alinux 的 daemonset 在每一个节点部署了对应的 Pod。
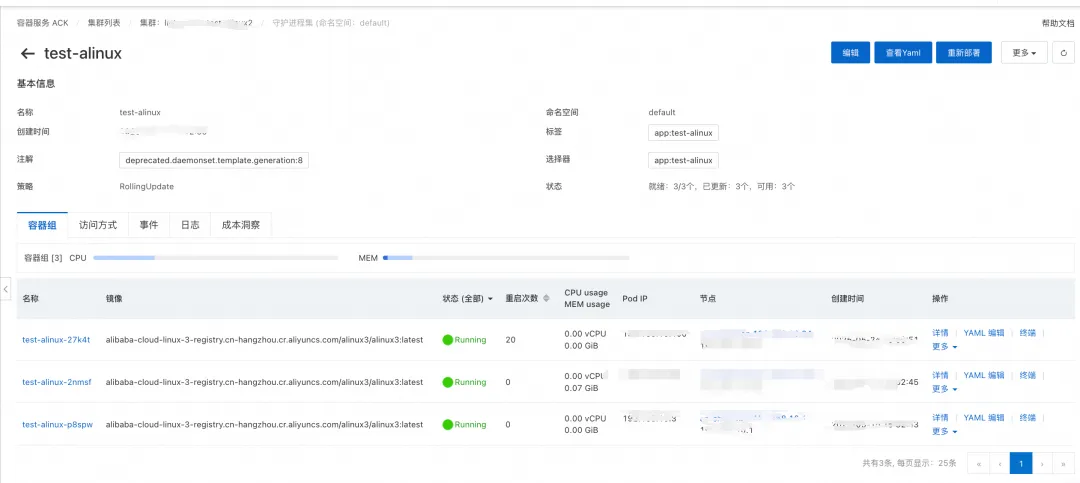
在操作系统控制台中设置 Pod 级别 FastOOM 策略:
为了匹配对应的 Pod,Pod 名称填写 test-alinux(正则表达式会匹配不同节点上的 test-alinux-xxx pod),命名空间为 default。
由于只是希望控制 OOM 时的杀进程策略,将内存压力级别设置为高,则触发用户态 OOM 的时机会近似于内核 OOM 的时机。
对于杀进程策略:配置优先杀死特定进程和避免杀死业务进程和 Pod 中的 1 号进程,从而避免 Pod 重启或影响业务,设置完成后下发至特定节点。
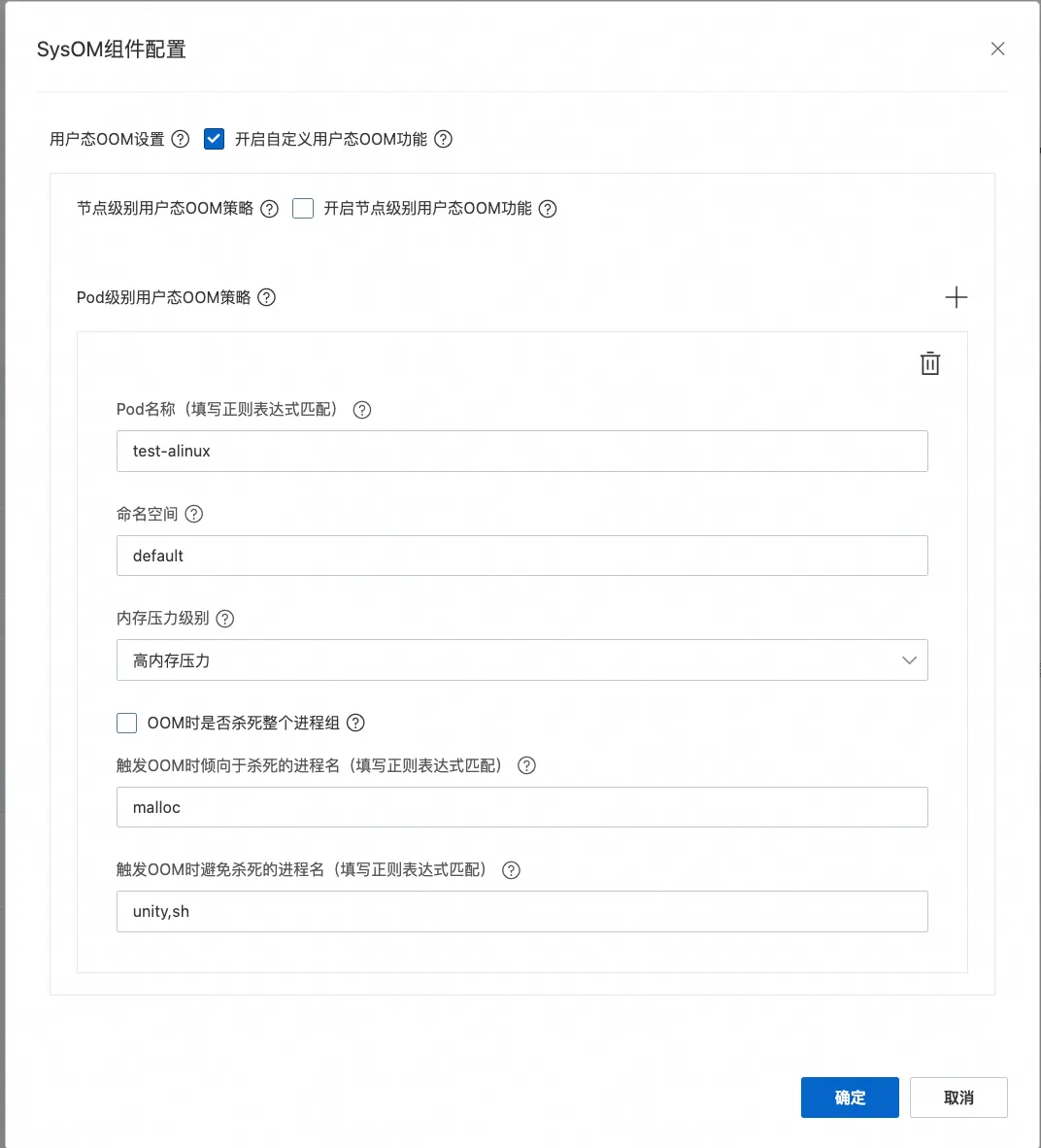
将配置下发到对应节点后,当 Pod 中容器内存使用超过容器 limit 后,发生 OOM;可以通过操作系统控制台系统概览看到 FastOOM 事件记录,可以看到 FastOOM 根据策略杀死了对应的进程,也避免了特定进程被杀死。

总结
人无完人,内核的 OOM 其实也不是万能的。为了能尽可能的回收内存,内核在发生 OOM 前会阻塞申请内存的进程,并尝试回收内存,这对于延时敏感的业务的影响是非常大的;如果内存持续保持在接近 OOM 的水位,还会进入 Near-OOM 的活锁状态导致整机夯机。阿里云操作系统控制台的 FastOOM 功能,通过相关指标,支持节点/容器/Pod 级策略,可精准杀指定进程,轻松弥补了内核 OOM 带来的延时卡顿问题。
联系我们
您在使用操作系统控制台的过程中,有任何疑问和建议,可以扫描下方二维码或搜索群号:94405014449 加入钉钉群反馈,欢迎大家扫码加入交流。

阿里云操作系统控制台 PC 端链接:




