
Agent 正在制造一场“Token 大爆炸”。六年前,OpenAI Token 使用量最大的用户每月能消耗约 10 万个 Token。但在 2026 年,这个数字变成了 10000 亿。
当 Agent 开始吞噬企业软件,一场“Token 大爆炸”已无法避免。
“Token 经济时代已经到来了。”华为数据存储产品线副总裁吴俊杰在做客 InfoQ《C 位面对面》栏目时表示,Agent 的爆发式增长将推动 Token 需求持续攀升,对于部署 Agent 和大模型应用的企业而言,需要考虑的问题已经不仅是能否把 AI 用起来,更重要的是如何在保证体验的同时,将每 Token 的成本控制在合理范围内。而这,与企业的数据基础设施能力息息相关。
过去几年,AI 发展经历了算力、模型、应用三个阶段。如今,AI 正在进入以数据为核心的第四阶段。在这一阶段,数据不再只是训练和推理的“原材料”,而是直接决定模型精度、幻觉水平与泛化能力的关键变量。谁能更高效地组织、检索和流转数据,谁就能在 Agent 时代继续留在牌桌上。
行业据此已经形成了共识。Gartner 预测,在 2026 年,人类智能、机器智能和组织智能之间的界限将继续模糊,企业将以前所未有的方式依赖数据。
但 Agent 吞掉的,真的只是 Token 吗?企业如何摆脱 Token 成本“刺客”?企业 AI 落地真正的卡点又在哪里?在本期《C 位面对面》中,InfoQ 极客传媒总编辑 & 总经理王一鹏对话华为数据存储产品线副总裁吴俊杰,一起聊聊“Token 大爆炸”前夜,数据基础设施何以成为新的变量。
Agent 吞掉的,不只是 Token
表面上,Agent 快速发展带来的是 Token 消耗量的狂飙,但本质上,它更像是对企业的数据能力进行一次前所未有的压力测试。
最明显的,是数据类型上的变化——Agent 产生了许多过去从未存在过的数据类型。比如在 Agent 推理的过程中,会产生 KV Cache 过程数据;随着推理不断深入,还会产生让 AI 能够记住并回溯过往行为的长期记忆数据。
更深层的变化,发生在取数逻辑上。在云计算时代,无论是数据库查询、文件访问还是虚拟化应用,本质上都是无状态、没有上下文关联、一次性完成的访问行为。但到了 AI 时代,Agent 的工作方式更像是一个 7×24 小时持续在线的数字员工,数据访问频次不像过去一样,有波峰、波谷,而是不停地访问。
这种持续不间断的上下文交互,把底层数据基础设施的响应速度逼到了墙角。黄仁勋在不久前举行的 GTC 台北大会上,甚至将记忆管理定位为 Harness 体系里最困难的环节之一。原因在于,整个 AI 的记忆系统,从决定该记住什么样的工作记忆(即 KV Cache),到如何进行高效检索,都在向传统的存储架构发出挑战。
“传统的存储,在 AI 时代已经不能满足 AI 推理的需求了。”吴俊杰坦言,随着百万级上下文、多轮推理成为主流大模型的“标配”,Agent 在推理的过程中需要持续、高频地加载历史对话、知识库内容和实时信息。过去,业务的 I/O 模型和时延要求可能是毫秒级的;但在 AI 时代,这个标准被被提升到了微秒级。数据返回的任何一丝延迟,都会造成算力等待和空转。
这些变化指向的是,数据基础设施,很可能成为企业整个 Token 生产链条中新的瓶颈。而它最直接的后果,就是成本开始失控。
警惕 Token 成本“刺客”
Token 消耗的持续攀升,让成本变成了一个敏感的话题。
很多企业习惯性地将 AI 成本高归因于 GPU 价格和算力投入,但这只是故事的一半。在 AI 建设中,算力部署与电费是看得见的显性开销,真正容易被忽视的,是隐藏在系统运行过程中的隐性成本——算力的浪费。
这种浪费主要体现在三个方面。
第一,算力等数据。 模型在训练过程中,需要持续、大规模的数据供给。如果数据供给的效率满足不了算力需求,算力就只能处于等待状态。当模型规模增长到一定的数量级时,这种等待带来的损失也会被持续放大。
第二,算力独占。 并不是所有的 AI 任务都需要独占一张高性能计算卡,一些相对小型的 AI 项目,如果独占一张算力卡,剩余的计算资源将无法被其他任务共享,造成算力资源浪费。
第三,重复计算。 在多轮次、长序列的推理过程中,由于显存空间不足,部分缓存数据无法保留,很多推理任务被迫截断,最终导致算力卡做大量的重复工作。
三种浪费指向的,其实都是底层的数据基础设施。当数据基础设施的供给能力追不上算力的消耗速度,算力浪费就是必然结果。
那么,如何让每 Token 的成本真正得到控制?
“答案跟整个数据的基础设施息息相关”,吴俊杰认为,无论是训练阶段的数据供给,还是推理阶段的上下文管理、KV Cache 复用,本质上都在影响算力利用率,而算力利用率又直接决定了每 Token 的最终成本。
以训练场景为例,如果存储系统无法持续、稳定地向算力集群提供数据,算力卡就会因为等待数据而空转。华为在其 AI 存储方案中,曾尝试通过横向扩展提升系统带宽能力,最终带宽达到 100 TB/s 级别,并将检查点数据读写时间从十分钟级缩短至秒级。端到端计算能力利用率提升超过 30%,减少 GPU 的无效等待。
到了推理阶段,新的挑战来自于不断膨胀的上下文数据和 KV Cache。当百万级上下文、多轮推理成为常态,系统需要保存和调用大量的记忆数据。如何降低推理过程中对显存资源的依赖,进而降低成本?在日前举行的 2026 华为创新数据基础设施论坛上,华为以 CMS(Context Memory Storage)向业界提供了一个参考样本。
CMS 是业界首个支持异构算力的上下文记忆存储方案,它支持 KV 语义直通或采用专用 DPU 进行语义卸载,并能扩展为 PB 级的共享 KV 缓存池,能让推理过程中产生的大量上下文数据,得到有效的存储,最终使每 Token 的成本下降 30% 左右,同时将推理首 Token 时延降低 90%。
技术层面的优化可以降低 Token 成本,但企业 AI 落地的复杂性,远不止于此。
企业 AI 落地的隐秘真相:卡点背后的系统性困局
企业真正进入 AI 落地阶段后,会发现很多项目卡住的地方,往往并不在模型本身。
吴俊杰把企业在 AI 落地时最常见的卡点归纳成两个:数据语料不够、质量不高,以及算力、AI 专业人才有限。
比如,很多企业以为自己有大量的数据,但到了真正使用时才发现,数据分散、格式不统一、质量参差不齐,能直接变成 AI 语料的部分并不多。
崖州湾国家实验室就是一个典型案例。这个农业领域的国家级实验室,最近几年来正在尝试通过 AI 打造育种 Agent,缩短育种周期。但问题是,海量的育种数据分散在全国数百个科研基地、高校和企业之间,缺少全面、标准化、可共享的表型组数据库、育种知识库,导致基因数据难以和作物性状(如抗旱表现、产量潜力)高效关联,育种周期、预见精度都受到影响。
为此,华为与崖州湾国家实验室联合构建了 AI 数据湖解决方案,帮助实验室汇聚了全国多源头农业数据,实现数据可视、可管、可流动,形成规模化种业数据资源池,并结合数据加工、应用编排、模型工程等工具进一步加工成高质量 AI 语料库。育种 Agent 落地后,能减少 50% 育种周期,育种效率提升 30%。
算力资源方面,并不是每家企业都有条件部署大规模算力集群,和具备一支专业的 AI 人才队伍。如何在有限的资源约束下,把 AI 高质量地部署起来,是大多数企业的真实痛点。
瑞金医院也是如此。作为中国头部医疗机构,瑞金医院虽然在过去积累了上百万份病理切片数据,但手里仅握有 16 张算力卡,这些算力资源根本不足以支撑一个复杂病理大模型的训练,医院也难以负担巨额的硬件扩容成本。同时,数据本身的准备也是一场硬仗,数据清洗、标注、归集需要专业临床医生与数据工程师大量协同,耗时费力。
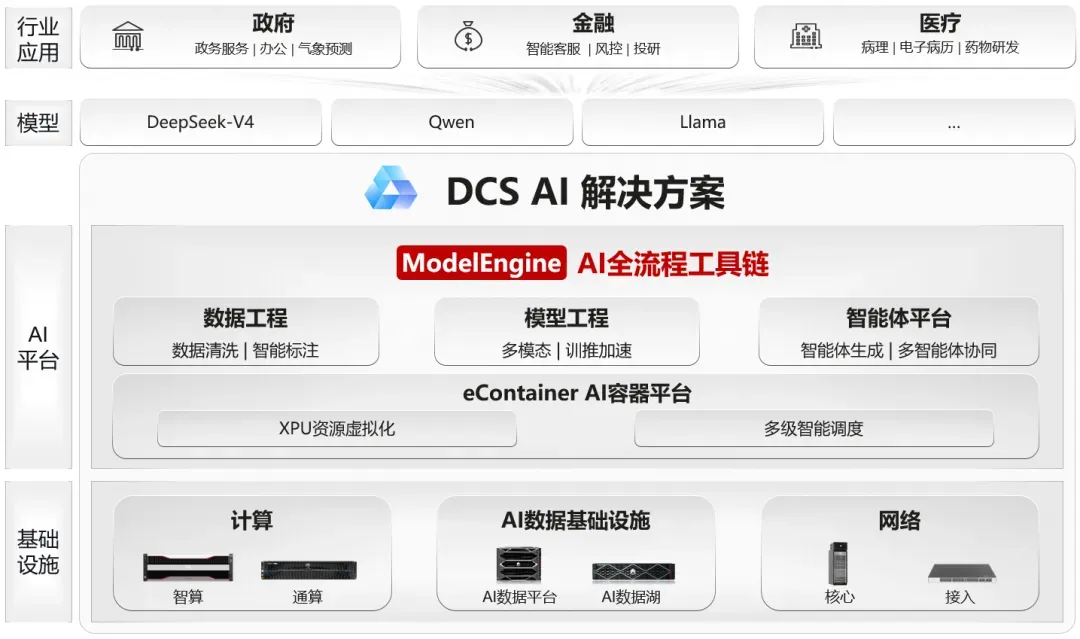
华为通过 DCS AI 解决方案,提供了两层解题思路,从数据工程、模型工程到应用编排打造了一套覆盖全流程的工程化工具:
在数据准备阶段,通过 ModelEngine 工具链实现全流程自动化处理,医生的工作从逐条标注转为批量审核,数据标注效率提升数十倍;
在模型适配阶段,通过模型蒸馏技术,将 671B 通用模型的能力蒸馏到 32B 参数规模的专家模型,同时结合资源调度技术,提升算力卡的资源利用率和应用会话的并发,最终在 16 张卡的资源条件下,成功帮助瑞金医院孵化出具备临床验证能力的 RuiPath 病理大模型。
把两个案例放在一起会发现,企业 AI 落地的卡点,从来不是单点的,而是系统性的。数据语料、算力资源、模型工程、开发工具、数据安全……任何一个环节的短板,都会拖住全局的后腿。割裂地解决单个问题,显然治标不治本。
这也是华为提出 AI DC 数据基础设施全栈方案 的底层逻辑。“企业要加速 AI 的落地,需要考虑建设私有的 AI 技术栈。 华为把它叫做 AI DC 数据基础设施全栈方案,全盘地去考虑数据湖、知识与记忆平台、算力、模型框架,包括 Agent 的开发,以及端到端的数据韧性等,完整的去规划和建设各方面的能力。”

据吴俊杰介绍,这套全栈方案由五层架构组成:数据湖、AI 数据平台、算力管理与调度、模型工程、Agent 开发框架。
第一层是 AI 数据湖,重点解决语料供给问题。华为通过 OceanStor Pacific 全闪分布式存储,实现最优 TCO 存储海量数据;依托 DME Omni-Dataverse 统一数据空间,使能多模态、跨站点数据实时入湖、全局可视可管,同时具备千亿千维向量数据的秒级检索能力,实现高质量数据汇聚与供给。
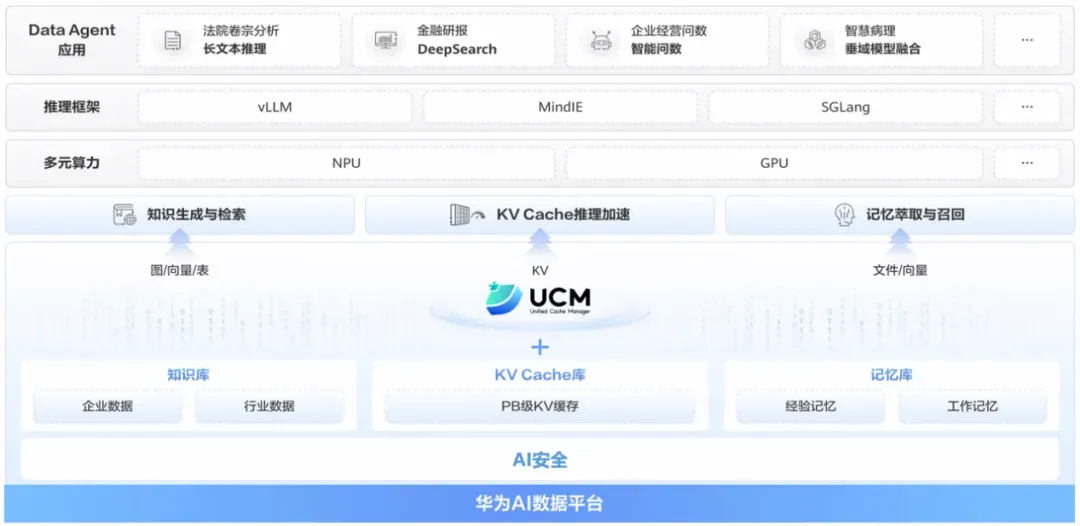
第二层是 AI 数据平台,这也是整套架构中,非常关键的一层。它直面 Agent 落地过程中最棘手的三个难题:知识怎么快速找得到、长上下文推理的效率、以及 Agent 的经验怎么沉淀下来。
在知识处理方面,华为 AI 数据平台能将知识检索精度从 70% 提升至 95%,知识库容量从亿级扩展至千亿级,知识更新实现秒级响应,检索结果全程可追溯;在推理效率方面,依托 UCM(Unified Cache Manager)技术实现 KV Cache 的智能分级管理,打破显存瓶颈,实现首 Token 时延最高降低 90%、推理吞吐提升 2 倍以上,优化推理效率与用户体验;在记忆管理方面,能沉淀 Agent 交互过程中的工作记忆与经验记忆,让 Agent 可以支持多轮任务的连贯跟进、并贴合用户使用习惯提供个性化响应,提升 Agent 推理准确率 30%。
第三层是算力管理与调度。 通过 DCS AI 解决方案中的 ModelEngine 工具链,实现 XPU 算力的虚拟化和细粒度切分,最大可实现 XPU 卡 1:10 切分,做到“一卡多用”,提升资源利用率。
第四层是模型工程。 通过开箱即用的模型工程能力,帮助企业更高效的实现模型部署。同时,提供模型的适配、增训等能力,让通用模型能够高效转化成行业专用模型。
第五层是 Agent 开发框架。 通过 ModelEngine Nexent 智能体平台,用户可以用自然语言直接生成 Agent,大幅降低开发门槛,使 Agent 上线周期缩短 80%;此外,ModelEngine Nexent 还能对 Skill、提示词、记忆实现自动优化,让 Agent 越用越聪明。
从数据源头到 Agent 生产,这五层架构形成了一条完整的链路,更像是一条为 AI 原生应用量身打造的数据“生产线”。
在这条“生产线”上,数据不再只是被存储的静态资产,而是从入湖、加工、检索到注入记忆、驱动 Agent 决策,一路流动、一路增值。如果说模型决定智能的上限,那么这套体系,决定的就是智能能否真正落地。
结语:AI 的下半程在于数据
回到最开始的那个“Token 大爆炸”问题,显然,当下真正值得大家关注的,早就不是 Token 数量本身,而是数字背后,是什么在真正决定 Token 的生产成本、生成质量与价值转化率。
答案,正指向数据。
在 2026 华为创新数据基础设施论坛上,华为提到一个很有意思的判断:AI 的下半程在于数据。如果说 AI 的第一章是算力,第二章是模型,第三章是 Agent,那么第四章,毫无疑问就是数据。
当 Agent 开始批量上岗,成为 7×24 小时工作的数字员工时,企业比拼的不再是谁调用了更多 Token,而是谁能让数据流得更顺、记得更久、算得更值。而数据湖、知识与记忆平台、KV Cache、算力调度、模型工程这些看起来不那么性感的数据基础设施,正在成为这个问题最关键的答案之一。




