
Karrot 将其传统的推荐系统替换为一个可扩展的架构。新架构利用了亚马逊云科技提供的各种服务。该公司希望解决先前解决方案中存在的紧耦合、可扩展性和可靠性差等挑战,并为此选择了一种基于可扩展云服务构建的分布式事件驱动架构。
Karrot 是一个韩国领先的本地社区构建平台,使用推荐系统为用户提供个性化的首页内容。该系统包括推荐机器学习模型和一个特征平台,后者是一个存储用户行为历史和文章信息的数据存储。近年来,随着公司推荐系统的不断演变,显而易见,添加新功能变得越来越困难,而且由于特征存储和摄取过程的碎片化,其系统开始受到可扩展性有限和数据质量差等问题的困扰。
其推荐系统的初始架构与跳蚤市场 Web 应用程序是紧耦合的,特定于特征的代码是硬编码的。尽管架构使用了可扩展的数据服务,如Amazon Aurora、Amazon ElastiCache和Amazon S3,但从多个数据存储中获取数据导致了数据不一致性,并给引入新的内容类型(如本地社区、工作和广告)带来了挑战。
Karrot 工程师 Hyeonho Kim、Jinhyeong Seo 和 Minjae Kwon 解释了使用统一、灵活、可扩展的特征存储的重要性:
在基于 ML 的系统中,各种高质量的输入数据(点击、转换操作等)被认为是一个关键元素。这些输入数据通常被称为特征。在 Karrot,包括用户行为日志、操作日志和状态值在内的数据统被称为用户特征,与文章相关的日志被称为文章特征。为了提高个性化推荐的准确性,需要综合各种类型的特征。一个能够有效管理这些特征并快速将其交付给 ML 推荐模型的系统就成了必不可少的。
该公司为新特征平台设定了雄心勃勃的目标,希望它能支持未来的产品开发和流量增长。技术团队还确定了与服务和摄取流量、总数据量和最大记录大小等相关的技术要求。
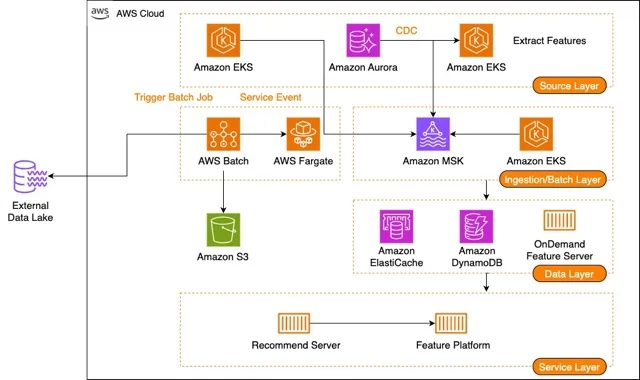
Karrot 特征平台的新架构(图片来源:亚马逊云科技架构博客)
新架构涵盖了三个主要领域:特征服务、流摄取管道和批量摄取管道。特征服务层负责为推荐引擎提供最新的特征数据。工程师考虑了功能和技术要求,并设计了一个多层缓存解决方案和针对特征特性量身定制的专用服务策略。频繁使用的小型数据集将通过位于特征服务器Amazon EKS Pod 中的内存缓存提供服务。使用频率适中的中等特征数据集则从远程 ElastiCache 缓存中获取。对于记录量大、使用频率低的特征类型,则采用统一模式直接从DynamoDB表中获取。此外,团队还创建了一个专用的 On-Demand Feature Server EKS 服务,用于处理动态计算的特征或因合规问题无法持久化的特征。
在处理服务层时,工程师解决了多个与常见缓存问题相关的挑战。他们采用了概率性提前失效(PEE)技术来刷新受欢迎的内容,并主动解决缓存未命中问题,减轻缓存踩踏并改善延迟。他们还采用了独立的软/硬时序触发器(TTL),结合抖动和写穿透缓存机制来缓解一致性问题,并运用负缓存技术减少不必要的数据库查询。
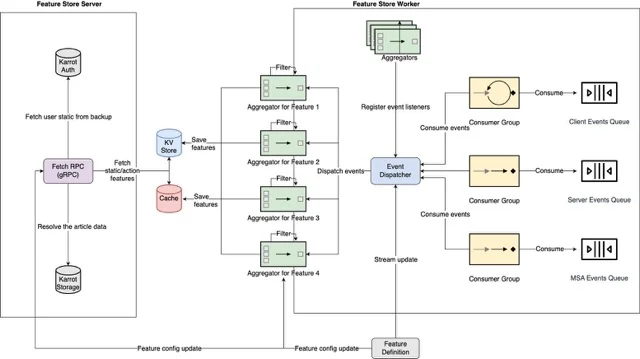
Karrot 特征平台的流摄取管道(图片来源:亚马逊云科技架构博客)
作为特征平台改进的一部分,Karrot 为实时事件和批量模式创建了一个新的数据摄取架构。核心流处理机制专注于处理简单ETL逻辑与数据验证,定制化方案用于处理更复杂的用例,例如从预训练模型中创建内容嵌入,或利用大型语言模型(LLM)丰富内容特征。工程师通过组合使用运行在 EKS 上的事件分发器与聚合器服务,从Amazon MSK获取事件数据,高效处理事件与特征之间的多对多关系。
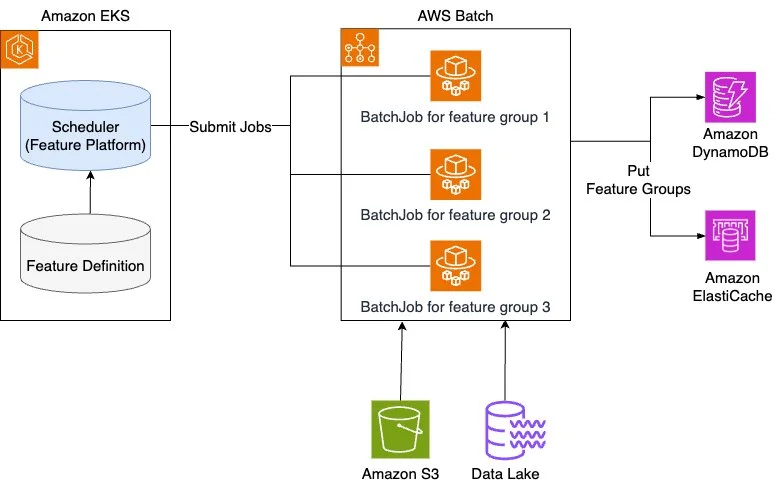
Karrot 特征平台的批量摄取管道(图片来源:亚马逊云科技架构博客)
该团队曾考虑使用Apache Airflow进行批量摄取,但最终选择了AWS Fargate上的AWS Batch,主要是考虑了后者的简单性和成本效益。然而,随着时间的推移,工程师发现了几个需要改进的地方,包括缺乏DAG支持、手动配置并行处理和监控功能有限。
新平台帮助 Karrot 将文章推荐点击率提高了 30%,转化率提高了 70%。该公司在 10 多个不同的空间和服务中使用了新平台,并存储了涵盖许多服务和内容类型的 1000 多个特征。
原文链接:
https://www.infoq.com/news/2025/12/karrot-aws-feature-platform/




