
昨晚,Anthropic 携两款“核弹级”模型炸场——Claude Fable 5 和 Claude Mythos 5。
据介绍,这是 Anthropic 迄今性能最强的一代模型,也是其首次将前沿模型按照风险等级进行差异化开放:面向普通用户的 Fable 5 保留了严格安全限制,而能力完全释放的 Mythos 5 则仅向少量经过审核的网络安全机构和科研组织开放。
在 Anthropic 看来,大模型能力已经进入一个新的阶段:模型不仅能够完成编码、写作和问答任务,还开始展现出执行长期复杂任务、独立开展科研探索甚至发现新科学假设的能力。与此同时,模型能力提升带来的潜在风险,也迫使公司重新设计模型的开放策略。
Anthropic 最强模型性能如何?
按照 Anthropic 的说法,Fable 5 已经超过此前所有公开发布的 Claude 模型。
据 Anthropic 官方披露,Claude Fable 5 定位通用级高性能模型,属于 Mythos 1 级技术梯队,综合性能超越品牌过往所有公开发布模型,在主流 AI 性能基准测试中稳居行业领先水平。
该模型具备突出的复杂任务处理优势,任务复杂度越高、运行周期越长,相较于前代模型的性能优势越显著,同时拥有更长的自主运行时长与更强的长上下文处理能力,可稳定支撑数百万 token 级别的持续性工作任务。
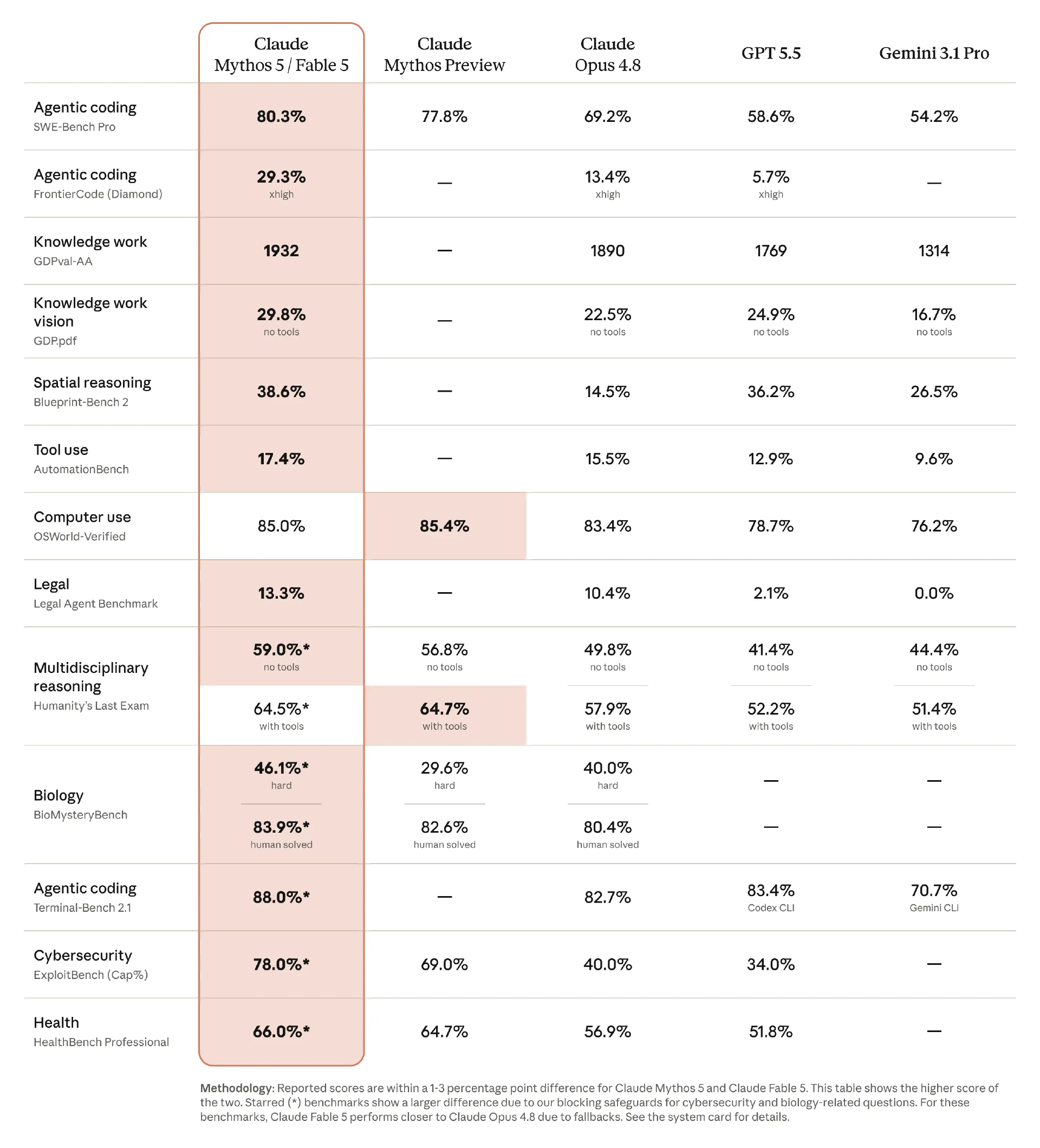
在具体产业落地场景中,Fable 5 展现出全方位的能力突破。
软件工程领域,该模型可实现超大代码库的高效迭代迁移,曾在 1 天内完成需要团队两个月手动攻坚的 5000 万行 Ruby 代码库迁移工作,将数月级工程量压缩至单日完成。
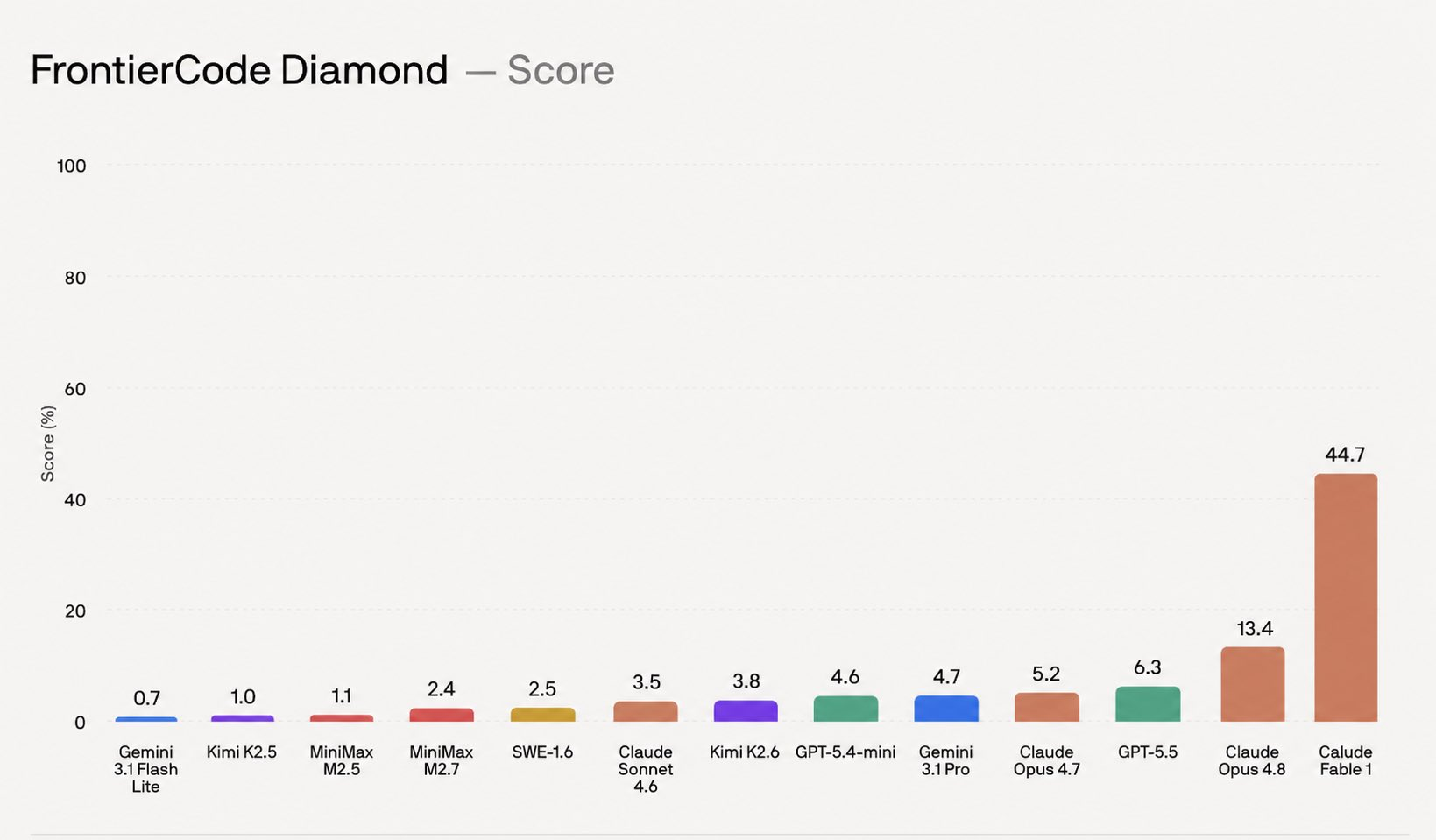
在 Cognition FrontierCode 编码评估中,其中等工作量下的得分领跑全球前沿模型,token 效率创下 Claude 系列新高。
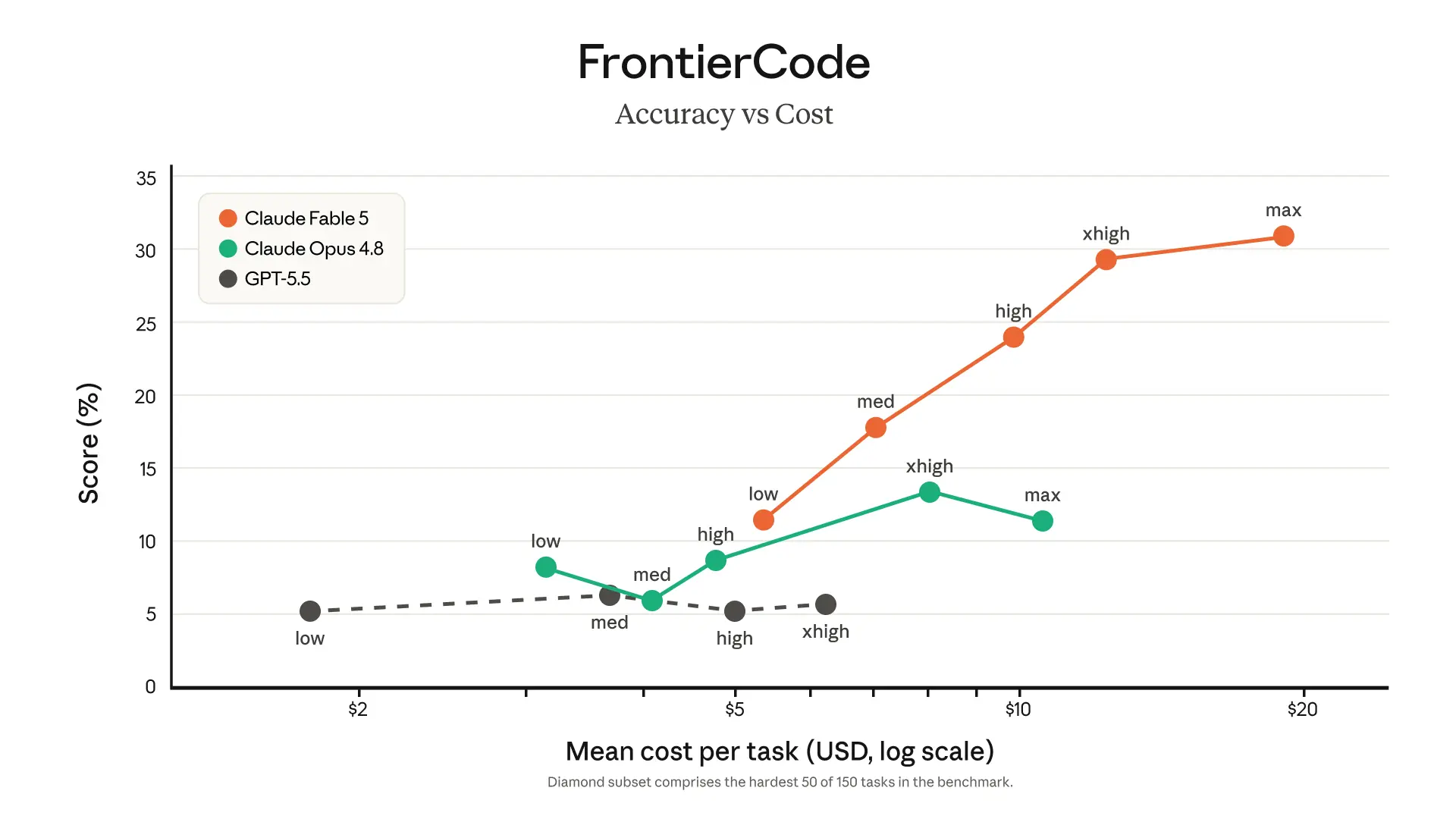
下面是其他模型在 FrontierCode Diamond 测试中的得分对比:
除了软件开发,Anthropic 还将 Fable 5 定位为知识工作工具。
AI 研究平台 Hebbia 的财务推理测试显示,Fable 5 在复杂文档分析、图表解读和问题求解任务上的表现达到所有参测模型最高水平。
量化交易公司 IMC 则表示,该模型已经能够完成事实检索、因果分析、根因定位以及预期收益分析等金融研究任务。
这些案例反映出一个趋势:模型竞争正在从单纯的知识问答,转向专业领域中的复杂推理和决策辅助。
视觉任务方面,它也基本上是当前业内顶尖的视觉专用模型,可精准提取复杂科学数据、仅凭截图还原 Web 应用源代码,甚至依托极简视觉组件独立通关《精灵宝可梦火红》,全程无需地图、游戏状态等额外辅助信息,突破了前代模型依赖复杂辅助工具的技术局限。
这段延时视频记录了 Claude 仅使用游戏截图从头到尾游玩《精灵宝可梦火红》的过程——没有使用任何地图、导航辅助工具或额外的游戏状态信息。早期的 Claude 机器人需要复杂的辅助设备才能玩《精灵宝可梦》;而 Claude Fable 5 仅凭视觉就完成了游戏。
此外,模型的内存与自主迭代能力大幅优化。在卡牌构筑游戏《杀戮尖塔》测试中,搭载持久化文件级内存的 Fable 5,性能较 Claude Opus 4.8 提升三倍,通关高阶关卡的概率显著提升。同时可依托基础物理原理自主推演行星轨道、模拟日食现象,具备极强的自主推理与场景复刻能力。
Claude Fable 5 构建了这个太阳系模拟,从物理学第一原理推导出行星的轨道运动,并用它来预测日食。
Mythos 5:能力更强,但并不向公众开放
相比面向大众开放的 Fable 5,Anthropic 此次同步发布的另一款模型 Mythos 5 显得更加特殊。
从技术角度看,两者基于同一底层模型。
区别在于,Mythos 5 取消了部分安全限制,因此能够释放全部能力。
Anthropic 表示,Mythos 5 目前是其网络安全能力最强的模型。该模型已经部署一些特殊机构中,服务对象主要包括关键基础设施运营方和网络安全防御机构。
目前,普通开发者和企业用户无法直接使用该模型。
在高精尖科研领域,Mythos 5 表现也很抢眼。
生命科学研究中,该模型可将药物设计部分环节效率提升十倍,能够独立完成蛋白质靶点筛选、设计工具运行、误差修复等全套科研工作,无需人工深度干预,目前已筛选出 9 个高潜力药物靶点,覆盖免疫检查点、神经退行性疾病、肌肉疾病等多个研究方向。
科研创新层面,Mythos 5 是 Claude 系列首款可持续产出高质量原创科学假设的 AI 模型。
在盲测对比中,科研人员对其分子生物学假设的认可度达 80%,多项假设已进入实验验证阶段,其中一项关于大肠杆菌蛋白作用机制的假设,已获得独立实验室的研究佐证。基因组学研究中,该模型可自主完成海量单细胞数据归集、定制 AI 模型训练等全流程工作,仅需极少人工干预,其研发的轻量化模型性能优于《科学》杂志刊发的同类模型,且参数规模仅为后者的百分之一,相关研究成果将于近期公开发表。
针对高端模型的滥用风险,Anthropic 为通用开放的 Fable 5 搭建了保守且完善的安全防护体系。由于顶级 AI 能力在网络安全、生物、化学等领域存在双重用途风险,Fable 5 搭载全新独立安全分类器,一旦检测到漏洞利用、攻击性网络任务、高危生物化学研究、模型能力提炼等风险请求,将自动回退至 Claude Opus 4.8 响应处理。
官方数据显示,这套安全机制整体误报率不足 5%,超 95%的用户会话可直接通过 Fable 5 原生能力响应,性能与 Mythos 5 基本持平。
经过超 1000 小时内部红队演练、外部漏洞赏金测试,该防护体系未出现通用越狱漏洞,抵御恶意攻击与越狱尝试的能力优于 Opus 4.7、Opus 4.8 等前代机型,可全面拦截单轮恶意网络攻击策划、漏洞开发等违规请求。
隐私合规层面,Anthropic 同步推出全新数据保留政策,要求 Mythos 级别模型的全量流量数据留存 30 天,仅用于风险研判、攻击溯源与安全优化,不参与模型训练及非安全类用途,同时完善人工数据访问日志记录机制,30 天后自动清理绝大部分数据,筑牢数据安全防线。一致性评估结果显示,Fable 5 与 Mythos 5 的欺骗、违规协作等不一致行为发生率与 Opus 4.8 持平,整体合规稳定性优异。
这么强大的模型,价格如何?
据介绍,这两款模型都已经大幅降价,统一收费标准为每百万输入代币 10 美元、每百万输出代币 50 美元,价格不足前代 Mythos Preview 版本的一半。
订阅服务层面,Anthropic 推出分阶段上线策略,即日起至 6 月 22 日,Pro、Max、Team 及席位制企业版套餐用户可免费体验 Fable 5;6 月 23 日起将暂时从订阅套餐下架,后续需消耗积分使用,待资源扩容后将重新纳入订阅标配体系。
外界评论如何?
这两款性能拉满的旗舰模型发布后,AI 圈很快出现了大量讨论。
前特斯拉 AI 负责人、OpenAI 创始成员之一的 Andrej Karpathy 第一时间给出了高度评价。
他在社交平台表示:
Claude Fable 5 与 Mythos 5 本质上是同一个底层模型,只是在 Fable 上增加了安全防护机制。从基准测试来看,它几乎在所有项目上都以明显优势取得了最佳成绩(SOTA)。但比起排行榜数字,更重要的是它在实际使用中的表现。从定性体验来看,这是一次配得上“大版本号升级”的能力跃迁。
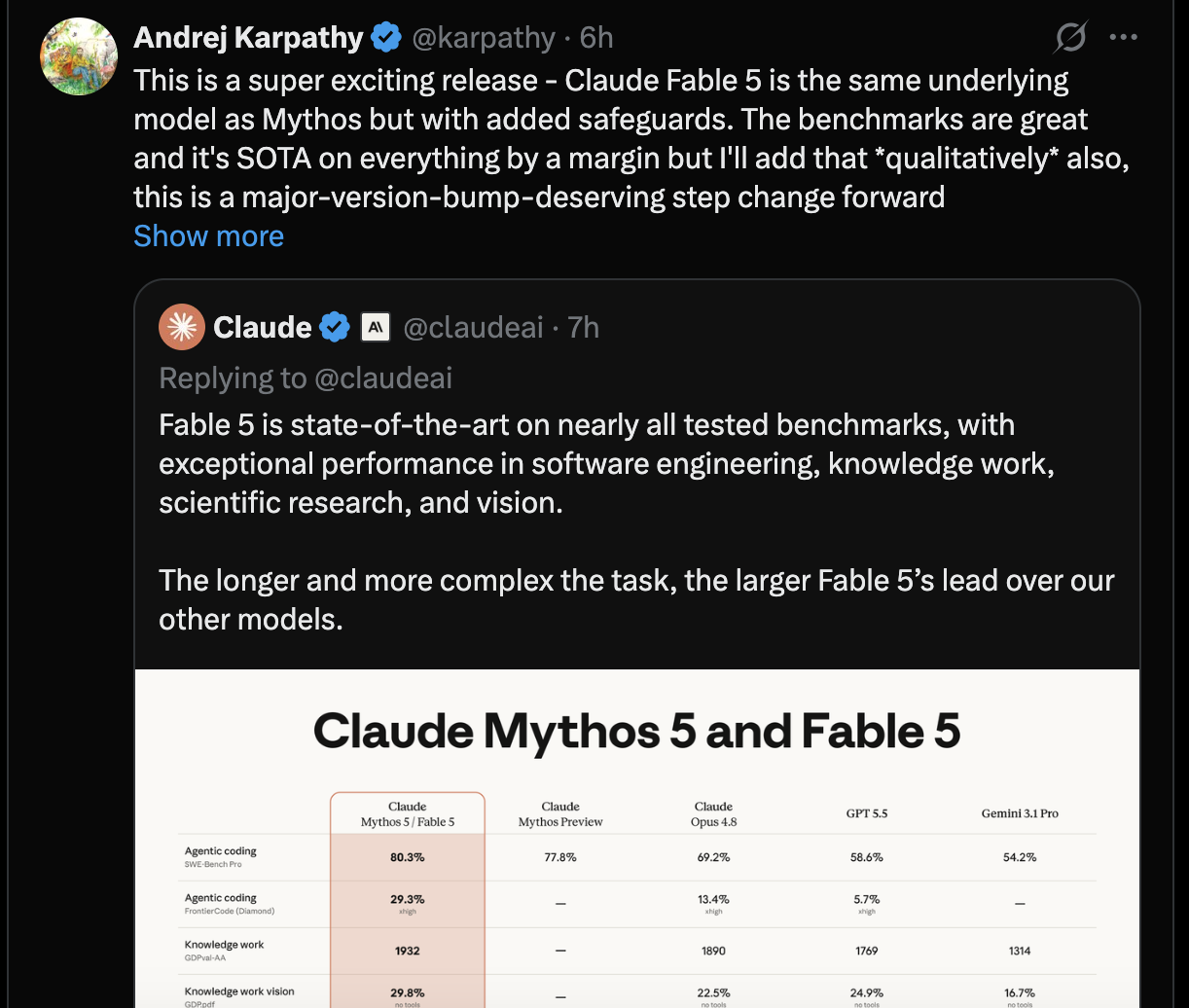
对于长期关注大模型发展的研究者来说,Karpathy 的评价颇具分量。
过去两年,大模型行业经历了多轮“刷榜竞赛”,各家公司不断刷新测试成绩,但用户实际体验未必同步提升。因此,越来越多开发者开始关注模型在真实任务中的表现,而不是单纯比较基准测试分数。
不少开发者认为,这次发布最值得关注的并不是 Anthropic 公布的各种榜单成绩。一位获得大量点赞的评论写道:
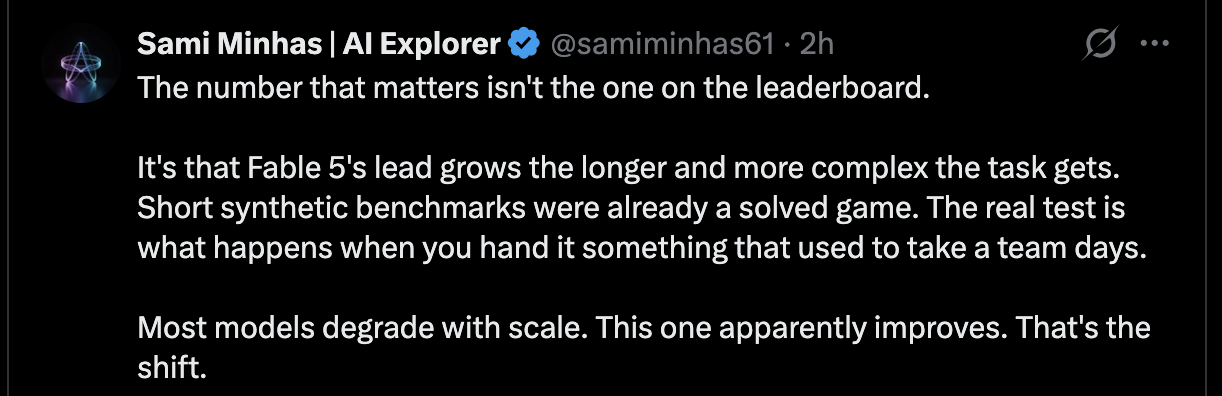
真正重要的数字并不是排行榜上的数字。问题在于,随着任务变得越来越长、越来越复杂,Fable 5 的优势反而越来越明显。短距离的综合基准测试对它来说已经不是挑战。真正需要观察的是,当一个任务需要团队连续工作数天才能完成时,它会表现如何。
这也是 Anthropic 此次反复强调的方向。
无论是 5000 万行代码迁移案例,还是持续数天的科学研究任务,本质上都在展示模型的长期自主执行能力。
在过去,大模型更像一个即时回答问题的助手;而 Anthropic 试图证明,Fable 5 已经开始接近“能够独立完成项目”的阶段。

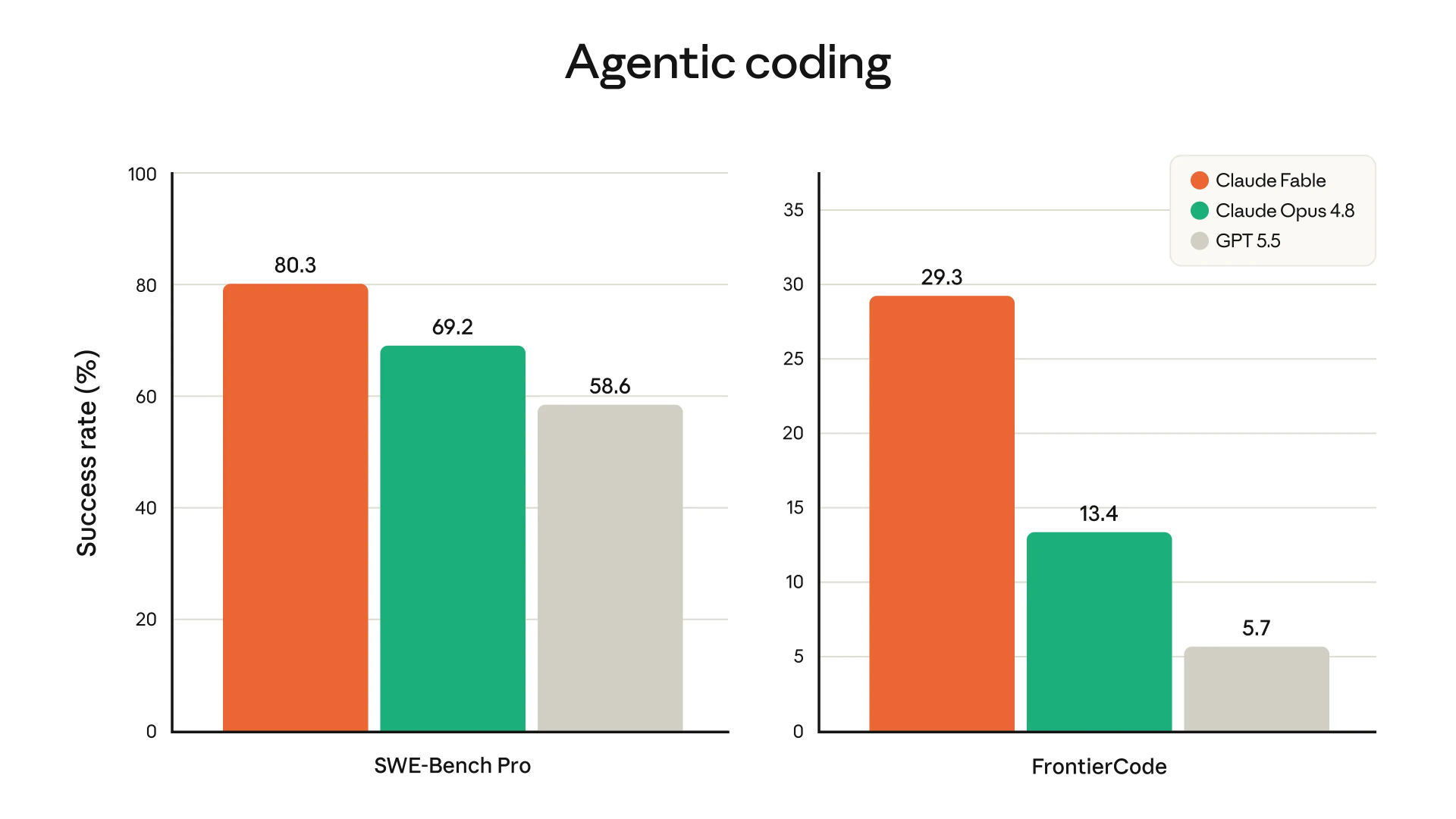
软件工程能力依然是讨论最热烈的话题。有用户特别提到了 Anthropic 公布的编码评测数据:
这些数字令人惊叹,看看每一项指标。智能编码任务的完成率从 69%提升到 80%,这样的增长幅度并不常见。
过去一年,Claude 系列已经逐渐成为许多程序员最常使用的代码助手之一。而从 Anthropic 此次公布的案例来看,其目标已经不仅仅是生成代码,而是让模型能够理解大型代码库、完成跨模块修改以及执行复杂的软件迁移工作。
如果这些能力能够在实际场景中稳定复现,其影响可能比单纯提升代码生成准确率更大。

当然,并非所有人都对这次发布感到兴奋,最常见的争议集中在价格和提升幅度上。
Claude Fable 5 的定价为每百万输入 Token 10 美元、每百万输出 Token 50 美元,有用户对此表示担忧:
按照这个速度发展下去,普通消费者还能跟得上吗?这些模型真的有明显进步吗?还是只是换了个名字,然后提高我们的 Token 消耗额度?
类似观点在近期前沿模型发布中并不少见。
随着大模型性能逐渐逼近天花板,用户对于“代际升级”的感知正在减弱。相比 GPT-3 到 GPT-4 那样的跨越式进步,如今许多模型更新更像是持续迭代。一位长期使用 Claude 进行财务分析的用户就表示:
我认为最大的提升主要体现在软件安全方面,其他能力虽然有所改进,但幅度有限。这些模型开始越来越像智能手机了,每一代都会进步,但已经很难再让人感到震撼。我目前使用 Opus 4.7 处理财务工作,它运行得很好,没有足够理由让我升级。
参考链接:




