
优步(Uber)发布了他们控制大规模变更在服务成千上万个微服务的单体仓库(monorepos)中推出的方法的细节,解决了大规模持续部署中的一个关键挑战。
这家拼车巨头的工程团队面临一个严峻的问题:当单体仓库中的单个提交可以同时影响数千个服务时——比如升级几乎每个优步 Go 服务中使用的 RPC 库——如何最小化问题变更可能造成的损害?
优步的工程技术栈依赖于几个单体仓库,每个主要编程语言一个单体仓库,这些仓库共同托管着数百或数千个服务,所有服务都是基于主干开发并从主分支发布。这种结构支持高度的代码重用和流线型的工作流程,但它带来了一个重大风险:一个单一的提交,比如更新核心 RPC 库,可能会波及到比预期多得多的服务。
通过对 Go 单体仓库中 50 万次提交的分析,团队发现 1.4%的提交影响了超过 100 个服务,0.3%的提交影响了超过 1,000 个优步服务。虽然这些大规模变更在内容上本身并不更危险,但它们带来的潜在破坏性呈指数级增长,尤其是当自动化 CD 管道立即将变更推送到生产环境时。优步早期的安全架构侧重于预部署测试和部署期间的服务级健康监控。但随着部署自动化的扩展,仅靠这些机制无法控制大规模提交带来的影响。
为应对这一情况,优步引入了一个跨服务部署编排层。与每个服务自主决定何时部署变更不同,编排增加了一个全局门控:一个服务中的部署决策现在会考虑其他受影响服务的信号(包括正面和负面)。从架构上讲,这是通过一个轻量级、异步的状态机实现的。定期作业跟踪所有受影响服务的部署结果。系统根据每个阶段的成功或失败阈值推进或推出部署,防止故障的不受控制的蔓延。
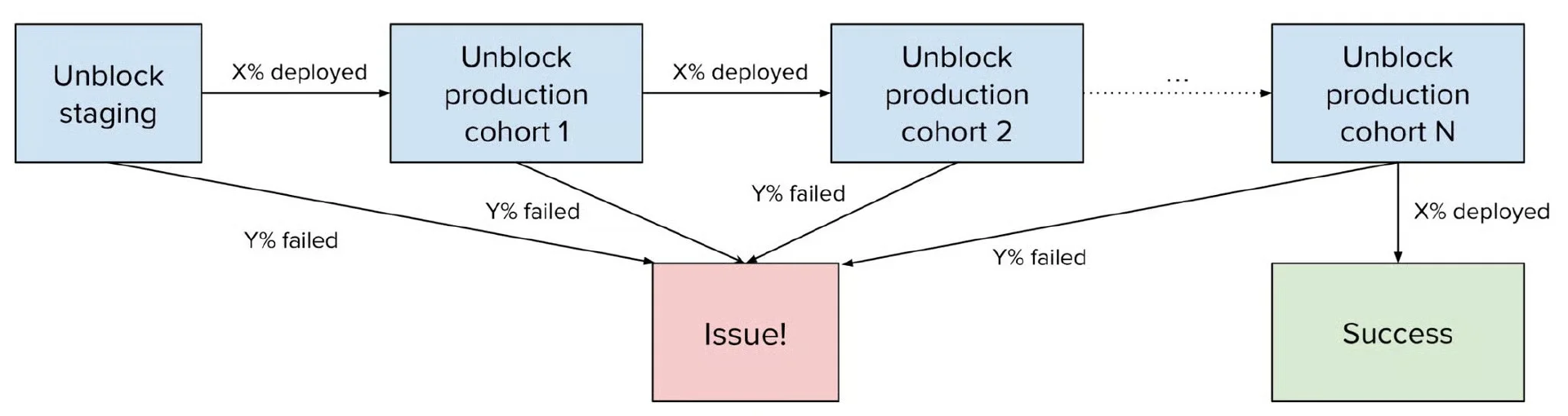
大规模部署的编排状态机。
这种编排方法的核心是服务分层。服务被分为从 0(最重要)到 5(最不重要)的层级。部署分阶段进行:首先部署一部分较不重要的服务。只有当它们成功时,系统才会解锁下一个层级。如果故障超过配置的阈值,部署就会停止,并且通知作者修复或回滚有问题的提交。这种基于队列的部署确保关键服务不会过早地暴露于潜在的风险变更中,并提供了何时继续或何时中止的明确信号。队列阈值和节奏的初始参数选择是凭直觉的,但过于谨慎了,系统经常滞后;关键服务可能被几个部署阻塞,从而造成功能延迟交付。
为了平衡速度和安全性,优步建立了一个 24 小时的最大窗口来解锁所有队列。他们构建了一个模拟器,用历史数据和不同的配置重放编排过程。这使他们能够根据提交时间、部署窗口和队列定义预测部署持续时间。通过调整阈值和队列分组,他们实现了一个更平坦的部署曲线,并在 24 小时内一致地完成,即使在周中启动的变更。部署完成后,各种大规模变更验证了模拟的准确性——系统如预期那样运行,进一步增强了对方法的信心。
如今,这个编排功能不仅支持安全关键的大规模变更,还支持其他场景。一个新兴的用例是在相同服务中部署批量配置,例如 ML 服务端点,其版本推出取决于成功部署到较低层级队列。
包括Google、Pinterest和Airbnb在内的主要技术公司都在运营庞大的单体仓库,并采用不同的策略来扩展规模、构建系统和管理软件的版本控制。优步的方法为管理大规模部署的知识体系做出了贡献。优步所应对的挑战尤其具有现实意义,因为越来越多的组织采用单体仓库架构,因为它们能够实现跨多个服务的原子变更,同时保持代码一致性并减少集成复杂性。
原文链接:
https://www.infoq.com/news/2025/09/uber-monorepo-deployment/




