很久以来,主流 NLP (Natural Language Processing)就在这样的一袋子词里面做文章,有时候也确实做出了蛮漂亮的文章,都是用的基于统计的机器学习。什么是“一袋子词”呢?
NLP 的对象是自然语言文本(speech 不论),具体说来,根据任务的不同,这个对象是语料库(corpus)、文章(document)或帖子(post),都是有上下文(discourse)的 text,作为 NLP 系统的输入。对于输入的 text,首先是断词(tokenization)。断词以后,有两条路可走,一条路是一句一句去做句法结构分析(parsing),另一条路就是这一袋子词的分析,又叫基于关键词(keywords)的分析。所以,一袋子词是相对于语言结构(linguistic structure)而言的。换句话说,一袋子词就是要绕过句法,把输入文字打散成词,然后通过统计模型,来完成指定的语言处理任务。(科学网,立委科普)
一袋子词(bag-of-words)模型在主题分类上做得很好,但是一旦涉及到情感分类,就不是很精确了。Bo Pang 和 Lillian Lee 在 2002 年的电影评论情感分析研究中,精确度才达到 69%。要是用 3 种常用的文本分析分类器(Naive Bayes、Maximum Entropy、Support Vector Machines),精确度能达到大约 80%(取决于采用的 feature)。
那么为什么还要用“一袋子词”模型呢?原因就在于可以帮助我们更好地理解文本内容,并且帮助我们为 3 个常用分类器选择 feature。Naive Bayes 模型也是基于“一袋子词”模型的,所以“一袋子词”模型可以作为一个中间步骤。
数据收集
Ahmet Taspinar 是一名数据科学家、软件工程师,同时也在攻读应用物理学。针对“一袋子词”的情感分析,他进行了一个实验。在他的实验中,他用著名的 Python 爬虫工具—BeautifulSoup,从亚马逊网站上爬取了大量的图书评论。在总共的 213335 本图书评论中随机选了 8 本书的评论。
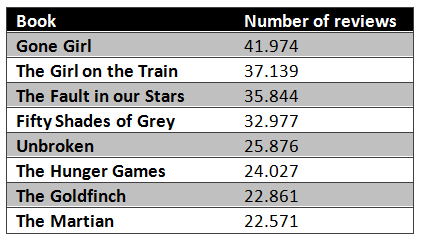
然后,他针对这 8 本书的不同打分,做了一个柱状分布图。从图中可以看到,分布变化趋势还是挺明显的,平均分以上的书,几乎没有 1 分的,远差于平均水平的书,不同等级的评分具有独特的分布趋势。
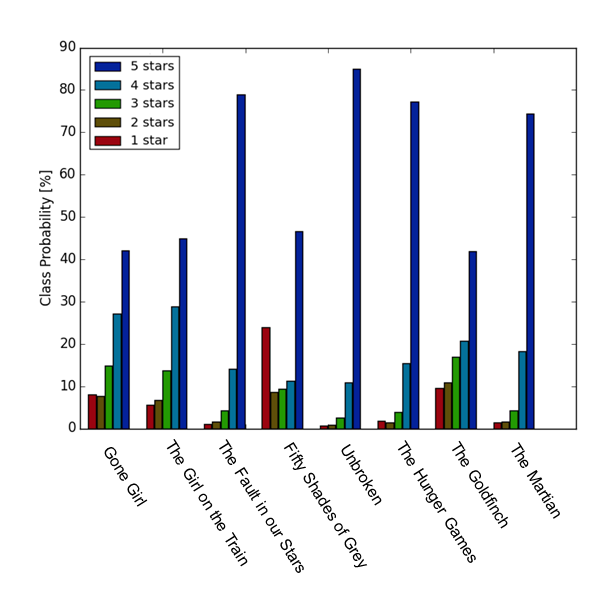
我们能看到,“Gone Girl”的评分分布趋势很漂亮,所以比较适合我们的数据训练;而“Unbroken”、“The Martian”这两本书,1 分的评分量都不太够,所以用于训练“差评”不是很合适。
建立“一袋子词”模型
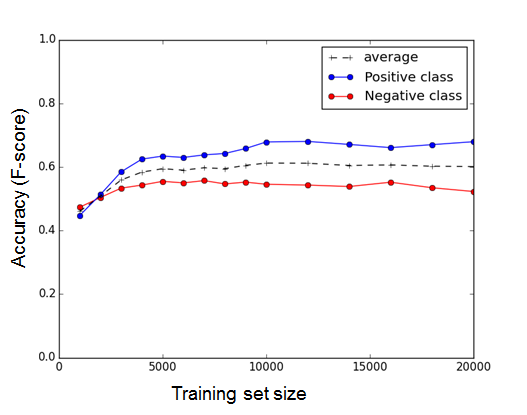
下一步,Ahmet Taspinar 将评论语料数据分成“训练数据集”和“测试数据集”。“Gone Girl”大概有 40000 个评论,所以他用最多一半的评论来训练,用剩下一半评论来测试模型。为了考虑到训练数据集大小对模型精确度产生的效应,他还会将训练数据集的大小从 1000 条评论到 20000 条评论之间来回变换。
“一袋子词”模型是 NLP 中最简单的语言模型之一。它通过追踪每个词的出现次数来建立文本的一元语法模型(Unigram Model),然后它可以用作文本分类器的 feature。在“一袋子词”模型中,你只能考虑单个的一些词,然后给每个词赋予一个特定的主观性得分。这个主观性得分可在情感词汇中查到。如果总分比较低,那么该文本就是“差评”,反之亦然。“一袋子词”很容易做,但是不够精确,因为它没有考虑词的顺序或者语法。简单的改进就是把一元语法模型和二元语法模型(Bigram Model)结合起来用,即不要在诸如“not”、“no”、“very”、“just”等词语后面断句。这样很好实现,但却有意想不到的效果。如果不把一元模型和二元模型结合,仅仅用一元模型,“This book is not good”就会判为“好评”,“This book is very good”和“This book is good”的评分就会一样。
建立“一袋子词”的伪代码如下所示:
list_BOW = []
For each review in the training set:
Strip the newline charachter “\n” at the end of each review.
Place a space before and after each of the following characters: .,()[]:;” (This prevents sentences like “I like this book.It is engaging” being interpreted as [“I”, “like”, “this”, “book.It”, “is”, “engaging”].)
Tokenize the text by splitting it on spaces.
Remove tokens which consist of only a space, empty string or punctuation marks.
Append the tokens to list_BOW.
list_BOW now contains all words occuring in the training set.
Place list_BOW in a Python Counter element. This counter now contains all occuring words together with their frequencies. Its entries can be sorted with the most_common() method.
制作情感词汇
现实问题是,我们怎么通过判断每个词的情感 / 主观得分来判断整个文本的情感 / 主观得分呢?的确,我们可以使用一些开源的词汇库,但是我们不知道这些词汇是在何种状态下、出于何种目的建立起来的。而且,绝大多数的词汇都被分成两类:要么好评、要么差评。
如果用训练数据集的一些统计指标来判断每一个词的主观得分,可能会好一些。为了这样做,Ahmet Taspinar 判断了”一袋子词“中每一个词出现的类概率。这可以通过使用 Panda Dataframe 作为 datacontainer(但只能用 dictionary 或者其他的数据格式来做)。代码如下:
from sets import Set
import pandas as pd
BOW_df = pd.DataFrame(0, columns=scores, index='')
words_set = Set()
for review in training_set:
score = review['score']
text = review['review_text']
splitted_text = split_text(text)
for word in splitted_text:
if word not in words_set:
words_set.add(word)
BOW_df.loc[word] = [0,0,0,0,0]
BOW_df.ix[word][score] += 1
else:
BOW_df.ix[word][score] += 1
这里 split_text 是用于将一句话拆分成单个词的列表的方法:
def expand_around_chars(text, characters):
for char in characters:
text = text.replace(char, " "+char+" ")
return text
def split_text(text):
text = strip_quotations_newline(text)
text = expand_around_chars(text, '".,()[]{}:;')
splitted_text = text.split(" ")
cleaned_text = [x for x in splitted_text if len(x)>1]
text_lowercase = [x.lower() for x in cleaned_text]
return text_lowercase
输出结果为一个包含了每种类型每个单词出现次数的数据列表:
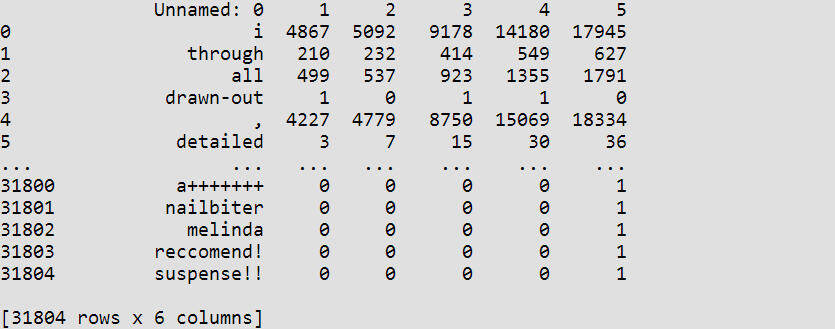
我们可以看到,还是有一些词只出现了一次。这些词在它们出现的这个类里,类概率是 100%。这种分布根本就不能真实反映实际的类分布状况。因此,对于定义一些“出现的临界值”还是不够好;出现次数少于这个值的单词不被列入考虑范围内。
通过用“一行中每个单词出现次数”除以“一行中所有词出现次数之和”,Ahmet Taspinar 得到了一个数据表,这个表包含了每种类型每个单词的相对出现次数。例如:每个单词的类概率图。做完这些后,class 1 中概率最高的单词被认为是“差评”的,class 5 中概率最高的单词被认为是“好评”的。
由此,我们可以从训练数据集中构建情感词汇,并用于衡量测试数据集中的评论主观性。随着训练数据集的大小不同,情感词汇也变得越来越精确了。
判断评论的主观性
通过将“4 star”和“5 star”标记为“好评”,“1 star”和“2 star”标记为“差评”,“3 star”标记为“中立”,并结合下图所示的“好评词”和“差评词”,我们可以使用“一袋子词”模型来判断一个评论究竟是“好评”还是“差评”了,并且精确度能达到 60% 以上。

展望
“一袋子词”通过绕过句法,把输入文字打散成词,然后使用统计模型完成基于关键词的分析。它可以帮助我们更好地理解文本内容,包括使用常用分类器来进行情感分析时,也是必不可少的关键步骤。那么展望未来,使用“一袋子词”来进行情感分析还有以下问题需要解决:
- 使用从 A 书的评论中建立的好评和差评词语,来判断 B 书评论的主观倾向性,其精确度有多高呢?
- 有太多词语本身没有正面或负面的意思,但却容易让人觉得有正面或负面的主观倾向,这些词只有结合上下文才能更好地理解。如果我们考虑二元语法模型(Bigram Model),甚至三元语法模型(Trigram Model),“一袋子词”的精确程度又能提高多少呢?
- 从所有书籍的所有评论中提取情感词汇全集,有没有可能实现?
- 使用“一袋子词”来作为三种常用分类器(Naive Bayes、Maximum Entropy 和 Support Vector Machines)的 feature。




