
刚刚,腾讯混元大模型团队正式发布并开源 HunyuanVideo 1.5,一款基于 Diffusion Transformer(DiT)架构、参数为 8.3B 的轻量级视频生成模型,支持生成 5-10 秒的高清视频。
目前,腾讯元宝最新版已上线该模型能力。用户可通过两种方式即可体验:一是输入文字描述(Prompt),直接实现“文生视频”;二是上传图片配合 Prompt,轻松将静态图片转化为动态视频。
文生视频提示词:一个人在电话里对家人报喜不报忧,用轻快的声音聊天。他脸上努力维持着开朗的笑容,但眼眶却不由自主地泛红,在挂断电话的瞬间,笑容瞬间垮掉,化为一声无声的叹息,手疲惫地捂住眼睛。)
根据介绍,HunyuanVideo 1.5 模型支持中英文输入的文生视频与图生视频。
文生视频提示词:一只破旧的棕色皮质手提箱,黄铜搭扣,静静地躺在明亮的阁楼地板上。起初,搭扣微微颤动,随后弹开,箱盖大开。箱子里装满了深色的泥土。接下来,一段令人叹为观止的延时生长过程开始了:细小的绿色芽破土而出,枝繁叶茂,长成微型树木,鲜艳的花朵竞相绽放。鹅卵石小径逐渐形成,一张小木凳凭空出现,池塘水面泛起涟漪。最终,一个完美精致的微型英式花园在箱子里徐徐展开。固定中景镜头,略微俯拍。明亮的自然光,柔和的阴影,以及细小的尘埃。逼真、神奇、细节丰富的转变,8K 分辨率。
模型还具备强指令理解与遵循能力,能够精准地实现多样化场景,包括运镜、流畅运动、写实人物和人物情绪表情等多种指令;同时支持写实、动画、积木等多种风格,并可在视频中生成中英文文字。
文生视频提示词:一段充满电影感的东京夜景,展现了熙熙攘攘的十字路口。镜头以高角度广角拍摄,展现了人群和霓虹灯,随后迅速拉近,聚焦于一位年轻的女性。她静立于模糊的喧嚣之中,若有所思。画面以忧郁的蓝红色灯光、湿漉漉的沥青路面倒映的影像以及浅景深为特色。
在画质方面,模型可原生生成 5–10 秒时长的 480p 和 720p 高清视频,并可通过超分模型提升至 1080p 电影级画质。
腾讯介绍,此前,视频生成领域的开源 SOTA 旗舰模型至少有 20B,需要超过 50GB 显卡方可部署。HunyuanVideo 1.5 定位为“开源小钢炮”,以极轻量的 8.3B 尺寸实现开源最佳的效果;显著降低了使用门槛,甚至可在 14G 显存的消费级显卡上流畅运行,真正让每一位开发者和创作者都能“玩起来”。
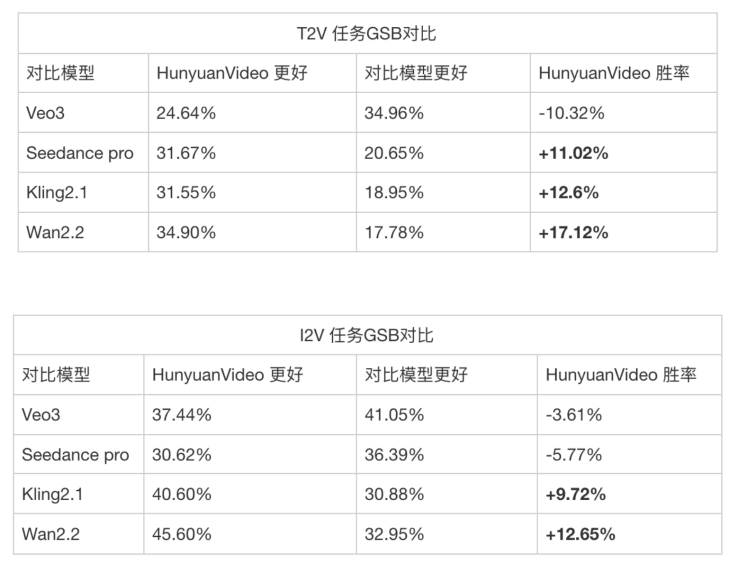
HunyuanVideo 1.5 GSB(Good Same Bad) 评测结果
据悉,HunyuanVideo1.5 通过多层次的技术创新,实现了生成效果、性能与尺寸上的平衡。HunyuanVideo 1.5 创新的 SSTA 稀疏注意力机制(全称 Selective and Sliding Tile Attention, 选择性滑动分块注意力)在保证高质量生成的同时显著提升推理效率,配合多阶段渐进式训练策略,在运动连贯性、语义遵循等关键维度均达到商用水平。
项目相关链接
项目主页:https://hunyuan.tencent.com/video/zh
Github:https://github.com/Tencent-Hunyuan/HunyuanVideo-1.5
Hugging Face:https://huggingface.co/tencent/HunyuanVideo-1.5
技术报告:https://github.com/Tencent-Hunyuan/HunyuanVideo-1.5/blob/main/assets/HunyuanVideo_1_5.pdf




