
周一,半导体行业巨头英伟达发布了新一代人工智能芯片 H200,旨在为各种 AI 模型提供训练和部署支持。
H200 芯片是目前用于训练最先进的大型语言模型 H100 芯片的升级版,搭载了 141GB 的内存,专注于执行“推理”任务。在进行推理或生成问题答案时,H200 的性能相比 H100 提升了 1.4 至 1.9 倍不等。
性能拉升无极限?
据英伟达官网消息,基于英伟达的“Hopper”架构,H200 是该公司首款采用 HBM3e 内存的芯片。这种内存速度更快、容量更大,使其更适用于大语言模型。相信过去一年来花大价钱购买过 Hopper H100 加速器的朋友都会为自己的冲动而后悔。为了防止囤积了大量 H100 的客户们当场掀杆而起,英伟达似乎只有一种办法:把配备 141 GB HBM3e 内存 Hopper 的价格,定为 80 GB 或 96 GB HBM3 内存版本的 1.5 到 2 倍。只有这样,才能让之前的“冤种”们稍微平衡一点。

下图所示,为 H100 与 H200 在一系列 AI 推理工作负载上的相对性能比较:
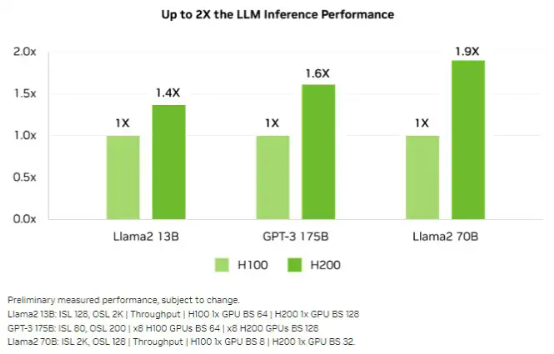
可以看到,相较于 H100,H200 的性能提升最主要体现在大模型的推理性能表现上。在处理 Llama 2 等大语言模型时,H200 的推理速度比 H100 提高了接近 2 倍。
很明显,如果能在相同的功率范围之内实现 2 倍的性能提升,就意味着实际能耗和总体拥有成本降低了 50%。所以从理论上讲,英伟达似乎可以让 H200 GPU 的价格与 H100 持平。

得益于 Tansformer 引擎、浮点运算精度的下降以及更快的 HBM3 内存,今年起全面出货的 H100 在 GPT-3 175B 模型的推理性能方面已经较 A100 提升至 11 倍。而凭借更大、更快的 HBM3e 内存,无需任何硬件或代码变更的 H200 则直接把性能拉升至 18 倍。
哪怕是与 H100 相比,H200 的性能也提高至 1.64 倍,而这一切都纯粹源自内存容量和带宽的增长。
想象一下,如果未来的设备拥有 512 GB HBM 内存和 10 TB/秒带宽,性能又会来到怎样的水平?大家愿意为这款能够全力施为的 GPU 支付多高的价钱?最终产品很可能要卖到 6 万甚至是 9 万美元,毕竟很多朋友已经愿意为目前未能充分发挥潜力的产品掏出 3 万美元了。
英伟达需要顺应大内存的发展趋势
出于种种技术和经济方面的权衡,几十年来各种处理器在算力方面往往配置过剩,但相应的内存带宽却相对不足。实际内存容量,往往要视设备和工作负载需求而定。
Web 基础设施类负载和那些相对简单的分析/数据库工作负载大多能在拥有十几条 DDR 内存通道的现代 CPU 上运行良好,但到了 HPC 模拟/建模乃至 AI 训练/推理这边,即使是最先进 GPU 的内存带宽和内存容量也相对不足,因此无法实质性提升芯片上既有向量与矩阵引擎的利用率。于是乎,这些 GPU 只能耗费大量时间等待数据交付,无法全力施展自身所长。
所以答案就很明确了:应该在这些芯片上放置更多内存!但遗憾的是,高级计算引擎上的 HBM 内存成本往往比芯片本身还要高,因此添加更多内存自然面临很大的阻力。特别是如果添加内存就能让性能翻倍,那同样的 HPC 或 AI 应用性能将只需要一半的设备即可达成,这样的主意显然没法在董事会那边得到支持。这种主动压缩利润的思路,恐怕只能在市场供过于求,三、四家厂商争夺客户预算的时候才会发生。但很明显,现状并非如此。
好在最终理性还是占据了上风,所以英特尔才推出了“Sapphire Rapids”至强 SP 芯片变体,配备有 64 GB HBM2e 内存。虽然每核分配到的内存才刚刚超过 1 GB,但总和内存带宽却可达到每秒 1 TB 以上。对于各类对内存容量要求较低的工作负载,以及主要受带宽限制、而非容量限制的工作负载(主要体现在 HPC 类应用当中),只需转向 HBM2e 即可将性能提升 1.8 至 1.9 倍。于是乎,Sapphire Rapids 的 HBM 变体自然成为 1 月份产品发布中最受关注、也最具现实意义的内容之一。英特尔还很有可能在接下来推出的“Granite Rapids”芯片中发布 HBM 变体,虽然号称是以多路复用器组合列(MCR)DDR5 内存为卖点,但这种内存扩容的整体思路必将成为 Granite Rapids 架构中的重要部分。
英伟达之前在丹佛举行的 SC23 超级计算大会上宣布推出新的“Hopper”H200 GPU 加速器,AMD 则将于 12 月 6 日发布面向数据中心的“Antares”GPU 加速器系列——包括搭载 192 GB HBM3 内存的 Instinct MI300X,以及拥有 128 GB HBM3 内存的 CPU-GPU 混合 MI300A。很明显,英伟达也必须顺应这波趋势,至少也要为 Hopper GPU 配备更大的内存。
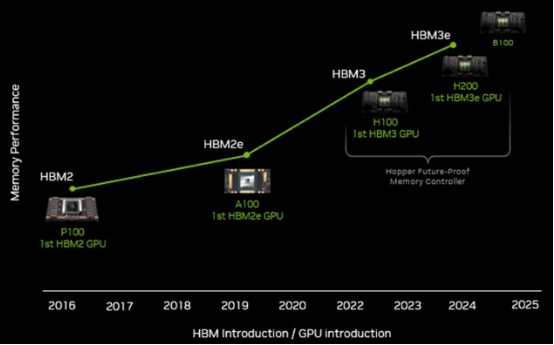
英伟达在一个月前的财务会议上放出技术路线图时,我们都知道 GH200 GPU 和 H200 GPU 加速器将成为“Blackwell”GB100 GPU 及 B100 GPU 之前的过渡性产品,而后者计划在 2024 年内发布。人们普遍认为 H200 套件将拥有更大的内存,但我们认为英伟达应该想办法提升 GPU 引擎本身的性能。事实证明,通过扩大 HBM 内存并转向速度更快的 HBM3e 内存,英伟达完全可以在现有 Hopper GPU 的设计之上带来显著的性能提升,无需添加更多 CUDA 核心或者对 GPU 超频。
明年还有新的大冤种?
身处摩尔定律末期,在计算引擎中集成 HBM 内存所带来的高昂成本已经严重限制了性能扩展。英伟达和英特尔在 Sapphire Rapids 至强 Max CPU 上都公布了相应的统计数字。而无论英伟达接下来的 Blackwell B100 GPU 加速器具体表现如何,都基本可以断定会带来更强大的推理性能,而且这种性能提升很可能来自内存方面的突破、而非计算层面的升级。下面来看 B100 GPU 在 GPT-3 175B 参数模型上的推理能力提升:

因此,从现在到明年夏季之间砸钱购买英伟达 Hopper G200 的朋友,肯定又要被再割一波“韭菜”(当然,这也是数据中心持续发展下的常态)。
最后:H200 GPU 加速器和 Grace-Hopper 超级芯片将采用更新的 Hopper GPU,配备更大、更快的内存,且计划于明年年中正式上市。也正因为如此,我们才认定 Blackwell B100 加速器虽然会在明年 3 月的 GTC 2024 大会上首次亮相,但实际出货恐怕要等到 2024 年底。当然,无论大家决定为自己的系统选择哪款产品,最好现在就提交订单,否则到时候肯定会一无所获。
参考链接:
https://www.nvidia.com/en-us/data-center/h200/




