
作者 | 邓刚、陈晨、周飞强、冯广远、严旭东、朱寒婷、史修磊、金一丹
数据服务是数据中台体系中的关键组成部分。作为数仓对接上层应用的统一出入口,数据服务将数仓当作一个统一的 DB 来访问,提供统一的 API 接口控制数据的流入及流出,能够满足用户对不同类型数据的访问需求。
电商平台唯品会的数据服务自 2019 年开始建设,在公司内经历了从无到有落地,再到为超过 30+业务方提供 to B、to C 的数据服务的过程。本文主要介绍唯品会自研数据服务 Hera 的相关背景、架构设计和核心功能。
背景
在统一数仓数据服务之前,数仓提供的访问接入方式往往存在效率问题低、数据指标难统一等问题,具体而言有以下几个比较突出的情况:
广告人群 USP、DMP 系统每天需要通过 HiveServer 以流的方式从数仓导出数据到本地,每个人群的数据量从几十万到几个亿,人群数量 2w+,每个人群运行时间在 30min +,部分大人群的运行直接超过 1h,在资源紧张的情况下,人群延迟情况严重。
数仓的数据在被数据产品使用时,需要为每个表新生成一个单独的接口,应用端需要为每一种访问方式(如 Presto、ClickHouse)区分使用不同的接口,导致数据产品接口暴涨,不方便维护,影响开发及维护效率。数据在不同的存储时,需要包含 clickhouse-client,presto-client 等等第三方 jar 包。
不同数据产品中都需要使用一些常用的数据指标,如销售额、订单数、PV、UV 等,而这些数据在不同数据产品的实现口径、实现方式都不一样,无法形成数据共享,每个数据产品都重复进行相同的指标建设。因此,在不同数据产品查看相同指标却发现数值不同的情况下,难以判断哪个数据产品提供的数据是准确的。
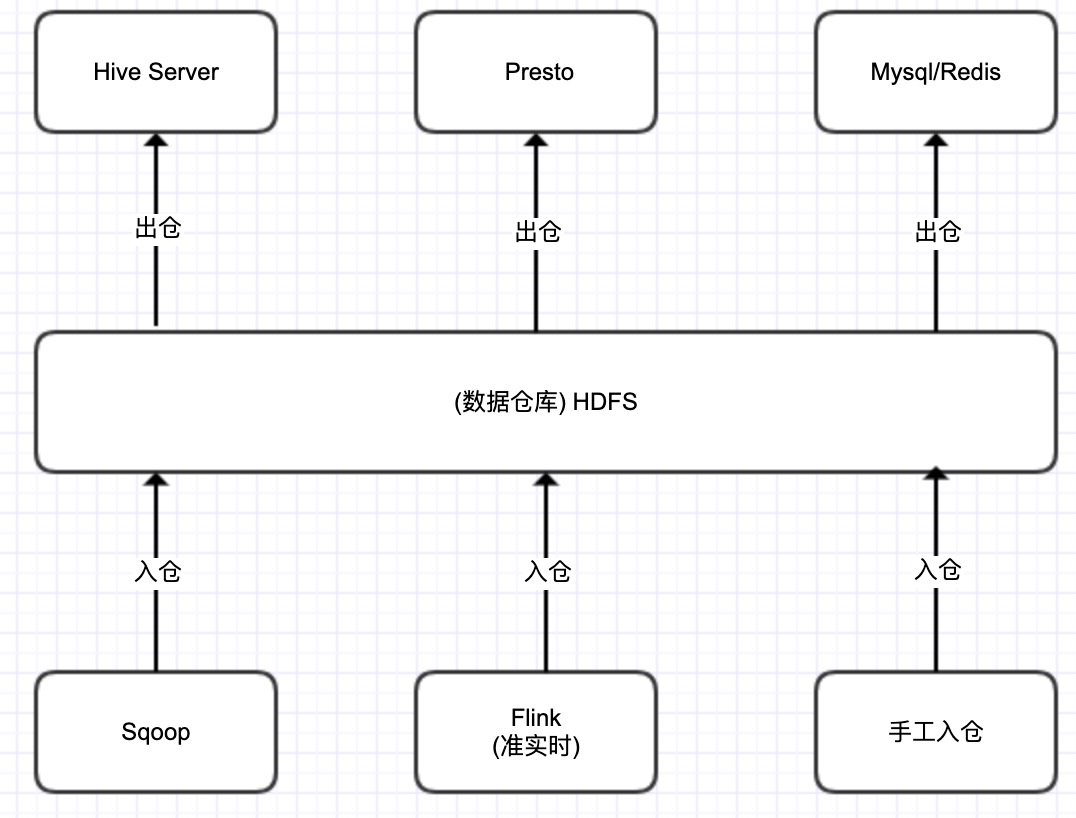
图 1.在统一数仓数据服务之前,数据流入流出方式
为解决以上问题,数据服务应运而生。目前数据服务的主要优势有:屏蔽底层的存储引擎、计算引擎,使用同一个 API(one service),数仓数据分层存储,不同 engine 的 SQL 生成能力,自适应 SQL 执行以及统一缓存架构保障业务 SLA,支持数据注册并授权给任何调用方进行使用,提高数据交付效率。
通过唯一的 ID 标识,数据产品可通过 ID 查阅数据,而非直接访问对应的数仓表。一方面,指标服务统一了指标的口径,同时也支持快速构建新的数据产品。
架构设计
数据服务能给业务带来运营和商业价值,核心在于给用户提供自助分析数据能力。Hera 整体架构基于典型的 Master/slave 模型,数据流与控制流单独链路,从而保障系统的高可用性。数据服务系统主要分为三层:
应用接入层:业务申请接入时,可以根据业务要求选择数据服务 API(TCP Client), HTTP 以及 OSP 服务接口(公司内部 RPC 框架)。
数据服务层:主要执行业务提交的任务,并返回结果。主要功能点包括:路由策略,多引擎支持,引擎资源配置,引擎参数动态组装,SQLLispengine 生成,SQL 自适应执行,统一数据查询缓存,FreeMaker SQL 动态生成等功能。
数据层:业务查询的数据无论在数仓、Clickhouse、MySQL 还是 Redis 中,都可以很好地得到支持,用户都使用同一套 API。
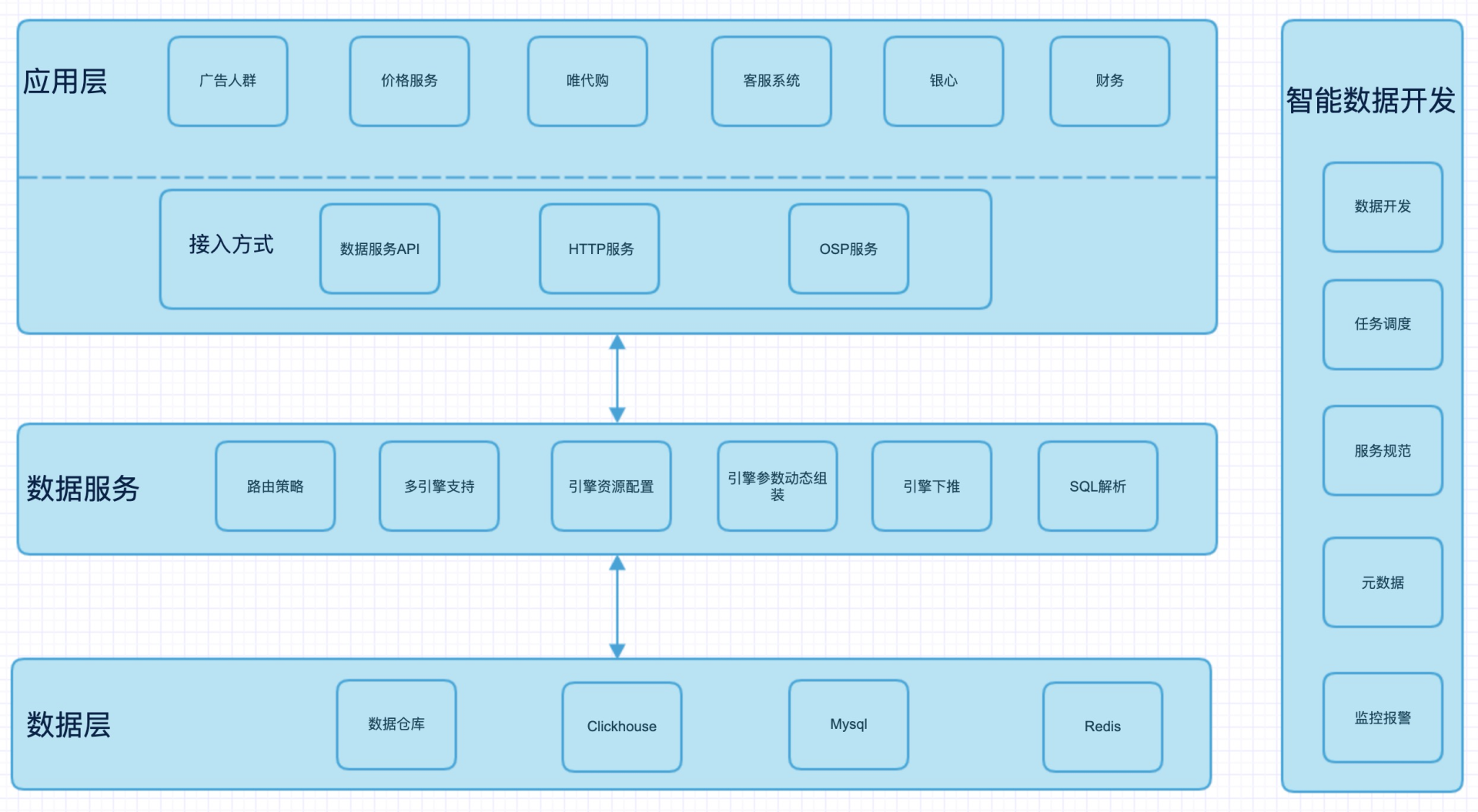
图 2. 数据服务整体架构图
调度系统的整体流程大致包含以下模块:
Master:负责管理所有的 Worker、TransferServer、AdhocWorker 节点,同时负责调度分发作业;
Worker:负责执行 ETL 和数据文件导出类型的作业,拉起 AdhocWorker 进程(Adhoc 任务在 AdhocWorker 进程中的线程池中执行),ETL 类型的作业通过子进程的方式完成;
Client:客户端,用于编程式地提交 SQL 作业;
ConfigCenter:负责向集群推送统一配置信息及其它运行时相关的配置和 SQLParser (根据给定的规则解析、替换、生成改写 SQL 语句,以支持不同计算引擎的执行);
TransferServer:文件传输服务。
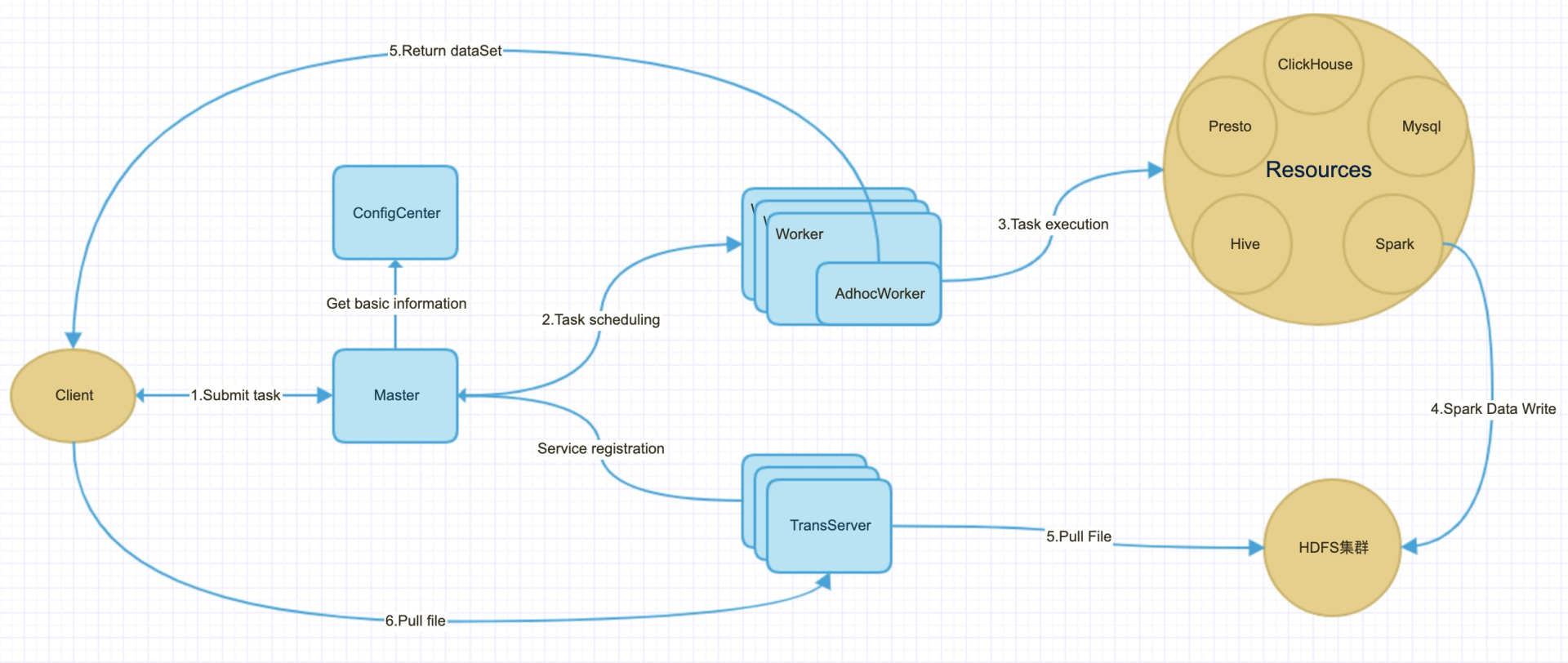
图 3. 数据服务调度流程图
主要功能
Hera 数据服务的主要功能有:多队列调度策略、多引擎查询、多任务类型、文件导出、资源隔离、引擎参数动态组装、自适应 Engine 执行和 SQL 构建。
多队列调度策略
数据服务支持按照不同用户、不同任务类型并根据权重划分不同调度队列,以满足不同任务类型的 SLA。
多引擎查询
数据服务支持目前公司内部所有 OLAP 和数据库类型,包括 Spark、Presto、Clickhouse、Hive 、MySQL、Redis。会根据业务具体场景和要求,选择当前最佳的查询引擎。
多任务类型
数据服务支持的任务类型有:ETL、Adhoc、文件导出、数据导入。加上多引擎功能,实现多种功能组合,如 Spark adhoc 和 Presto adhoc。
文件导出
主要是支持大量的数据从数据仓库中导出,便于业务分析和处理,比如供应商发券和信息推送等。
具体执行过程如下:用户提交需要导出数据的 SQL,通过分布式 engine 执行完成后,落地文件到 hdfs/alluxio. 客户端通过 TCP 拉取文件到本地。千万亿级的数据导出耗时最多 10min。数据导出在人群数据导出上性能由原来的 30min+ ,提升到最多不超过 3min,性能提升 10~30 倍。具体流程如下:
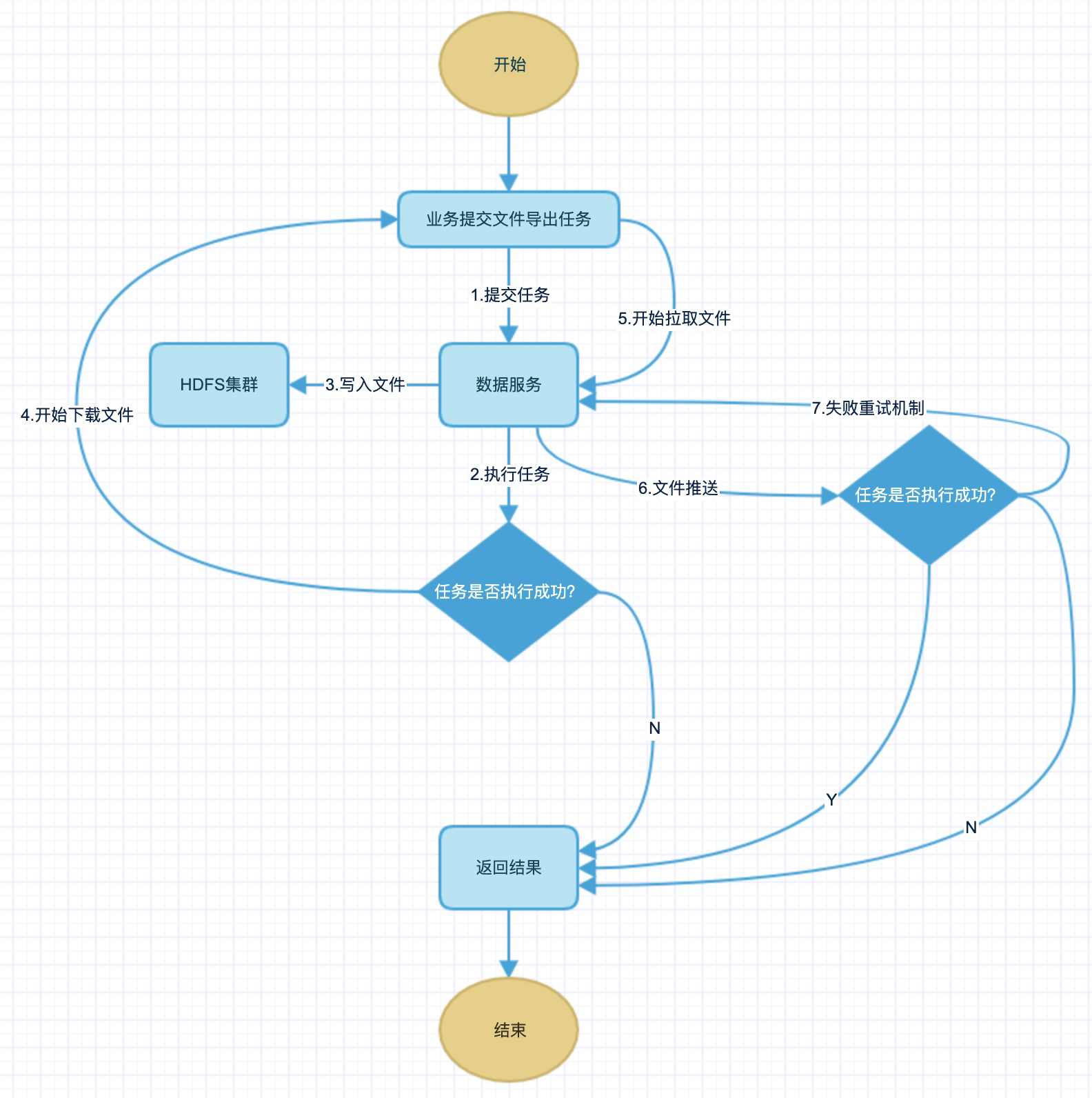
图 4. 数据服务文件下载流程图
资源隔离(Worker 资源和计算资源)
业务一般分为核心和非核心,在资源分配和调度上也不同。主要是从执行任务 Worker 和引擎资源,都可以实现物理级别的隔离,最大化减少不同业务之间相互影响。
引擎参数动态组装
线上业务执行需要根据业务情况进行调优,动态限制用户资源使用,集群整体切换等操作,这个时候就需要对用户作业参数动态修改,如 OLAP 引擎执行任务时,经常都要根据任务调优,设置不同参数。针对这类问题,数据服务提供了根据引擎类型自动组装引擎参数,并且引擎参数支持动态调整,也可以针对特定任务、执行账号、业务类型来设定 OLAP 引擎执行参数。
自适应 Engine 执行
业务方在查询时,有可能因为引擎资源不足或者查询条件数据类型不匹配从而导致执行失败。为了提高查询成功率和服务 SLA 保障,设计了 Ad Hoc 自适应引擎执行,当一个引擎执行报错后,会切换到另外一个引擎继续执行。具体自适应执行逻辑如下图所示:
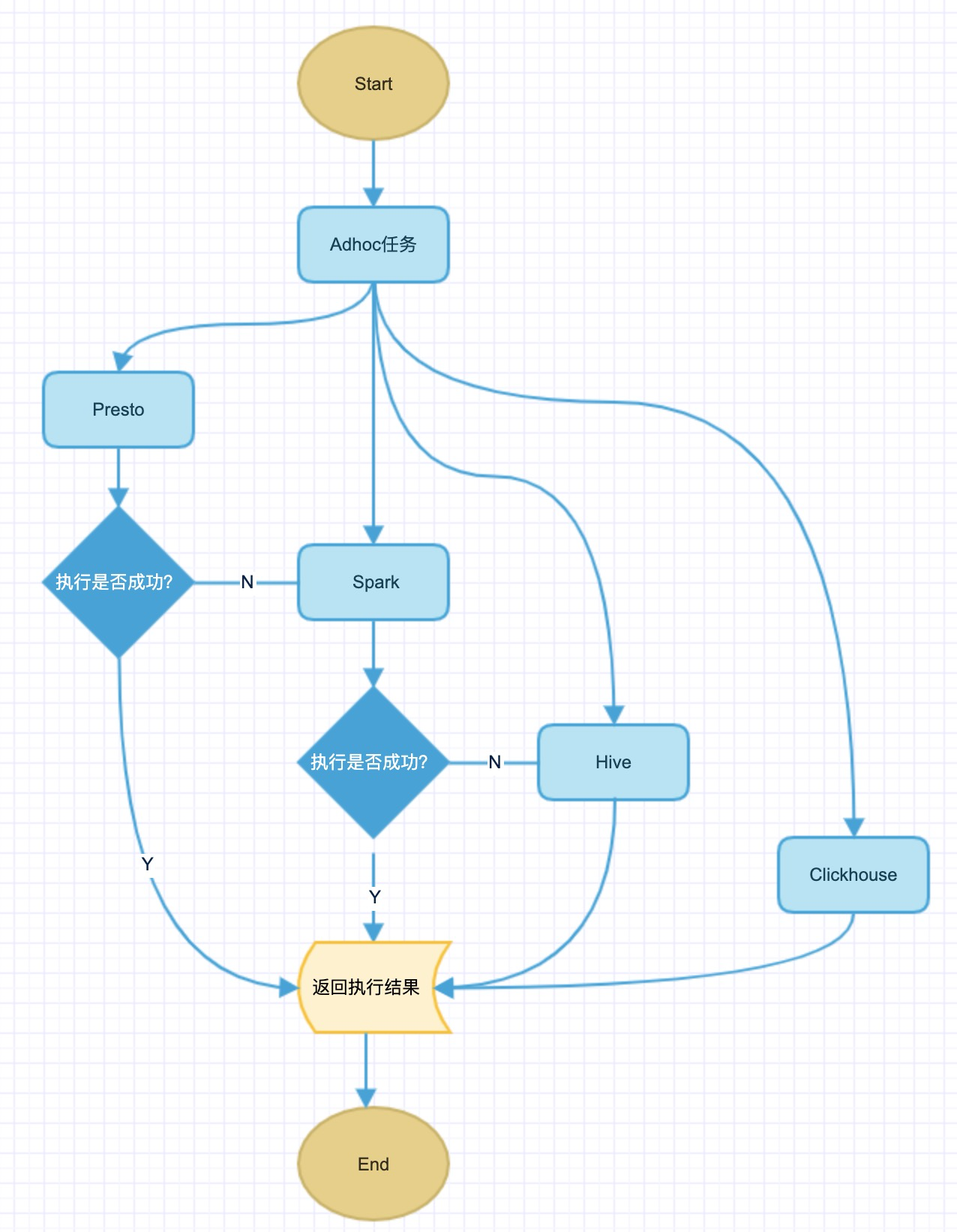
图 5. 自适应 Engine 执行
SQL 构建
数据服务 SQL 构建基于维度事实建模,支持单表模型、星型模型和雪花模型。
单表模型:一张事实表,一般为 DWS 或者 ADS 的汇总事实表。
星型模型:1 张事实表(如 DWD 明细事实表)+ N 张维表,例如订单明细表 (事实表 FK=商品 ID) + 商品维表 (维度表 PK=商品 ID) 。
雪花模型:1 张事实表(如 DWD 明细事实表)+ N 张维表+M 张没有直接连接到事实表的维表,例如订单明细表 (事实表 FK=商品 ID) + 商品维表 (维度表 PK=商品 ID,FK=品类 ID) + 品类维表(维度表 PK=品类 ID)。
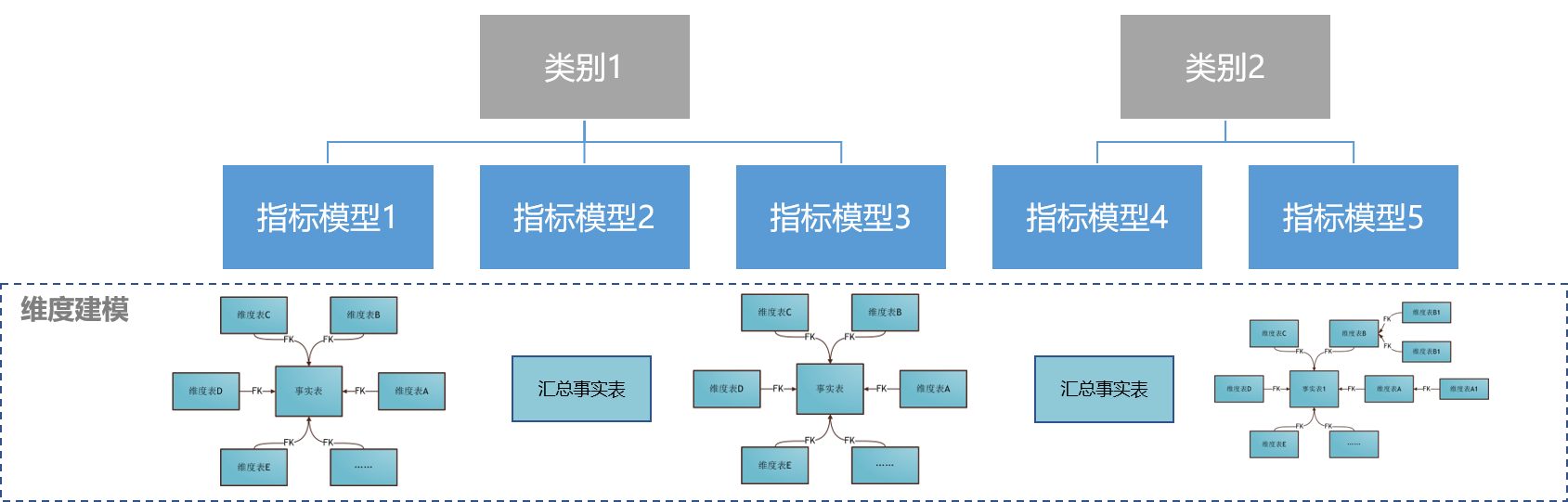
图 6.SQL 维度模型
自定义语法(Lisp)描述指标的计算公式
Lisp 是一套自定义的语法,用户可以使用 Lisp 来描述指标的计算公式。其目标是为了构建统一的指标计算公式处理范式,屏蔽底层的执行引擎的语法细节,最大化优化业务配置和生成指标的效率。
Lisp 总体格式 (oprator param1 param2 ...) param 可以是一个参数,也可以是一个 Lisp 表达式。目前已经实现的功能:
聚合表达式
(count x [y,z...]), count distinct x over (partition by y,z);
在 Presto 中的实现是 approx_distinct(x,e) over (partition by y,z),在 Spark 中的实现是 approx_count_distinct(x,e) over (partition by y,z)。y,z 只在开窗函数模式下才生效。目前也支持嵌套的聚合表达式(sum (sum (max x)))。
条件表达式
case when 实现 when1 为条件 bool 或者被比较值 then1 为对应输出 elseX 为最后的 else 输出
简单模式 (case value val1 then1 [val2 then2] ... [elseVal])
eg:(case subject_id (int 2) (int 1)) -> case subject_id when 2 then 1 end)
查找模式 (case when1 then1 [when2 then2] ... [elseVal])
eg: (case (= subject_id (string goods_base)) (int 2) (int 1)) -> case when subject_id = 'goods_base' then 2 else 1 end
类型标识表达式
(int xx) xx 标识成 数字型
(string xx) xx 标识成 字符串类型
null 直接返回 null
类型转换表达式
(cast bigint xx)
(cast double xx)
(cast string xx)
聚合通用表达式
(func a b c ...) 通用 Lisp 表达式 a 为函数名 后续字段为表达式元素 如 (func bar 1 2 3) 解析为 bar(1, 2, 3)
非聚合通用表达式
(func_none a b c ...) 通用 Lisp 表达式 a 为函数名 后续字段为表达式元素 如 (func_none bar 1 2 3) 解析为 bar(1, 2, 3) ,设置 Lisp 对象的 aggregation 属性为 false
例如:(func_none json_extract_scalar 40079 '$.m_name' )
Lisp 语法的解析
Lisp 的解析和翻译是基于 antlr4 来实现的,处理流程如下:
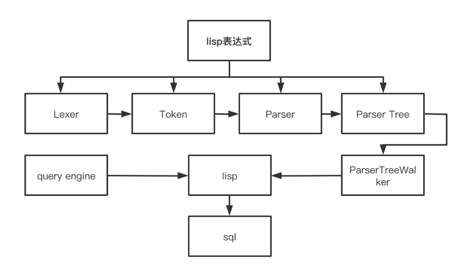
图 7. Lisp 处理流程图
将 Lisp(count x y)表达式通过 antlr 翻译成语法树,如下图所示:
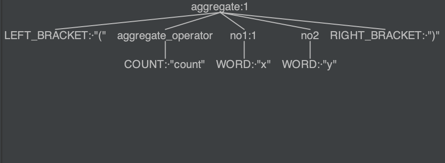
图 8. 语法树
通过自定义的 Listener 遍历语法树
在遍历语法树的过程中,结合指标的 query engine(presto/spark/clickhouse/mysql)元数据生成对应的查询引擎的 SQL 代码(approx_distinct(x,e) over (partition by y))
任务调度
基于 Netty 库收发集群消息,系统仅仅使用同一个线程池对象 EventLoopGroup 来收发消息,而用户的业务逻辑,则交由一个单独的线程池。
选用 Netty 的另外一个原因是“零拷贝”的能力,在大量数据返回时,通过文件的形式直接将结果送给调用者。
多队列+多用户调度
业务需求通常包含时间敏感与不敏感作业,为了提高作业的稳定性和系统的可配置性,Hera 提供了多队列作业调度的功能。
用户在提交作业时可以显式地指定一个作业队列名,当这个作业在提交到集群时,如果相应的队列有空闲,则就会被添加进相应的队列中,否则返回具体的错误给客户端,如任务队列满、队列名不存在、队列已经关闭等,客户端可以选择“是否重试提交”。
当一个作业被添加进队列之后,Master 就会立即尝试调度这个队列中的作业,基于以下条件选择合适的作业运行:
每个队列都有自己的权重,同时会设置占用整个集群的资源总量,如最多使用多少内存、最多运行的任务数量等。
队列中的任务也有自己的权重,同时会记录这个作业入队的时间,在排序当前队列的作业时,利用入队的时间偏移量和总的超时时间,计算得到一个最终的评分。
除了调度系统本身的调度策略外,还需要考虑外部计算集群的负载,在从某个队列中拿出一个作业后,再进行一次过滤,或者是先过滤,再进行作业的评分计算。
一个可用的计算作业评分模型如下:
队列动态因子 = 队列大小 / 队列容量 * (1 - 作业运行数 / 队列并行度)
这个等式表示的意义是:如果某个队列正在等待的作业的占比比较大,同时并行运行的作业数占比也比较大时,这个队列的作业就拥有一个更大的因子,也就意味着在队列权重相同时,这个队列中的作业应该被优先调度。
作业权重 = 1 - (当前时间-入队时间) / 超时时间
这个等式表示的意义是:在同一个队列中,如果一个作业的剩余超时时间越少,则意味着此作业将更快达到超时,因此它应该获得更大的选择机会。
score = 作业权重 + 队列动态因子 + 队列权重
这个等式表示的意义是:对于所有的队列中的所有任务,首先决定一个作业是否优先被调度的因子是设置的队列权重,例如权重为 10 的队列的作业,应该比权重为 1 的队列中的作业被优先调度,而不管作业本身的权重(是否会有很大的机率超时);其次影响作业调度优先级的因子是队列动态因子,例如有两个相同权重的队列时,如果一个队列的动态因子为 0.5,另外一个队列的动态因子是 0.3,那么应该优先选择动态因子为 0.5 的队列作业进行调度,而不管作业本身的权重;最后影响作业调度优先级的因子是作业权重,例如在同一个队列中,有两个权重分别为 0.2 和 0.5 的作业,那么为了避免更多的作业超时,权重为 0.2 的作业应该被优先调度。
简单描述作业的排序过程就是,首先按队列权重排序所有的队列;对于有重复的队列,则会计算每个队列的动态因子,并按此因子排序;对于每一个队列,作业的排序规则按作业的超时比率来排序;最终依次按序遍历每一个队列,尝试从中选择足够多的作业运行,直到作业都被运行或是达到集群限制条件。这里说足够多,是指每一个队列都会有一个最大的并行度和最大资源占比,这两个限制队列的参数组合,是为了避免因某一个队列的容量和并行度被设置的过大,可能超过了整个集群,导致其它队列被“饿死”的情况。
SQL 作业流程
用户通过 Client 提交原始 SQL,这里以 Presto SQL 为例,Client 在提交作业时,指定了 SQL 路由,则会首先通过访问 SQLParser 服务,在发送给 Master 之前,会首先提交 SQL 语句到 SQLParser 服务器,将 SQL 解析成后端计算集群可以支持的 SQL 语句,如 Spark、Presto、ClickHouse 等,为了能够减少 RPC 交互次数,SQLParser 会一次返回所有可能被改写的 SQL 语句。
在接收到 SQLParser 服务返回的多个可能 SQL 语句后,就会填充当前的作业对象,真正开始向 Master 提交运行。
Master 在收到用户提交的作业后,会根据一定的调度策略,最终将任务分发到合适的 Worker 上,开始执行。Worker 会首先采用 SQL 作业默认的执行引擎,比如 Presto,提交到对应的计算集群运行,但如果因为某种原因不能得到结果,则会尝试使用其它的计算引擎进行计算。当然这里也可以同时向多个计算集群提交作业,一旦某个集群首先返回结果时,就取消所有其它的作业,不过这需要其它计算集群的入口能够支持取消操作。
当 SQL 作业完成后,将结果返回到 Worker 端,为了能够更加高效地将查询结果返回给 Client 端,Worker 会从 Master 发送的任务对象中提取 Client 侧信息,并将结果直接发送给 Client,直到收到确认信息,至此整个任务才算执行完毕。
在整个作业的流转过程中,会以任务的概念在调度系统中进行传播,并经历几个状态的更新,分别标识 new、waiting、running、succeed、failed 阶段。
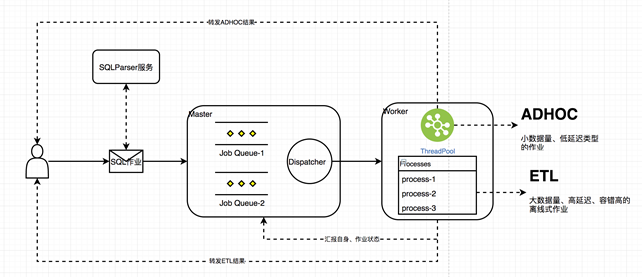
图 9. SQL 作业处理流程
Metrics 采集
数据服务搜集两类 metrics,一类静态的,用于描述 master/worker/client 的基本信息;一类是动态的,描述 master/worker 的运行时信息。这里主要说明一下有关集群动态信息的采集过程及作用。以 worker 为例,当 worker 成功注册到 master 时,就会开启定时心跳汇报动作,并借道心跳请求,将自己的运行时信息汇报给 master。这里主要是内存使用情况,例如当前 worker 通过估算方法,统计目前运行的任务占据了多少内存,以便 master 能够在后续的任务分发过程中,能够根据内存信息进行决策。master 会统计它所管理的集群整个情况,例如每个任务队列的快照信息、worker 的快照信息、集群的运行时配置信息等,并通过参数控制是否打印这些信息,以便调试。
调用情况
目前数据服务每天调用量:
toC: 9000W+/每天。
toB:150W+ /每天(透传到执行 engine 端调用量)。
ETL 任务执行时间基本在 3 分钟左右完成;
adhoc 查询目前主要有 Spark Thrift Server,Presto,Clickhouse 3 种引擎,大部分 SQL 90% 2s 左右完成,Clickhouse 查询 99%在 1s 左右完成,Presto 调用量 50W+/日, Clickhouse 调用量 44W+/日。
解决的性能问题
数据服务主要解决 SLA 方面的问题。如人群计算、数据无缝迁移、数据产品 SLA (数据产品 SLA 部分详情的参见《Clickhouse 在唯品会数据产品SLA问题的探索》),这里用人群举例说明如下:
人群计算遇到的问题:
人群计算任务的数据本地性不好;
HDFS 存在数据热点问题;
HDFS 读写本身存在长尾现象。
数据服务改造新的架构方案:
计算与存储同置,这样数据就不需通过网络反复读取,造成网络流量浪费。
减少 HDFS 读写长尾对人群计算造成的额外影响,同时减少人群计算对于 HDFS 稳定性的影响。
广告人群计算介于线上生产任务跟离线任务之间的任务类型。这里我们希望能保证这类应用的可靠性和稳定性,从而更好地为公司业务赋能。
通过数据服务执行人群计算。
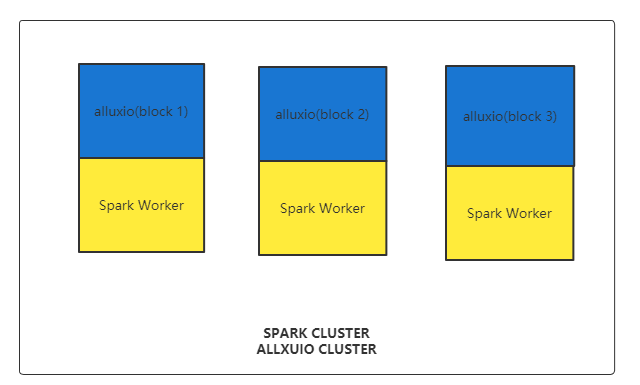
图 10. Alluxio 和 Spark 集群混部
基于 Alluxio 的缓存表同步
将 Hive 表的 location 从 HDFS 路径替换为 Alluxio 路径,即表示该表的数据存储于 Alluxio 中。我们使用的方案不是直接写通过 ETL 任务写 Alluxio 表的数据,而是由 Alluxio 主动去拉取同样 Hive 表结构的 HDFS 中的数据,即我们创建了一个 HDFS 表的 Alluxio 缓存表。基于 HDFS 的人群计算底表的表结构如下:
CREATE TABLE `hdfs.ads_tags_table`( `oaid_md5` string, `mid` string, `user_id` bigint, ......... )PARTITIONED BY ( `dt` string)LOCATION 'hdfs://xxxx/hdfs.db/ads_tags_table'基于 Alluxio 的人群计算底表的表结构如下:
CREATE TABLE `alluxio.ads_tags_table`( `oaid_md5` string, `mid` string, `user_id` bigint, ......... )PARTITIONED BY ( `dt` string COMMENT '????')LOCATION 'alluxio://zk@IP1:2181,IP2:2181/alluxio.db/ads_tags_table'两个表结构的字段和分区定义完全相同。只有两处不同点:通过不同的库名区分了是 HDFS 的表还是 Alluxio 的表;location 具体确认了数据存储的路径是 HDFS 还是 Alluxio。
由于 Alluxio 不能感知到分区表的变化,我们开发了一个定时任务去自动感知源表的分区变化,使得 Hive 表的数据能够同步到 Alluxio 中。
具体步骤如下:
定时任务发起轮询,检测源表是否有新增分区。
发起一个 SYN2ALLUXIO 的任务由数据服务执行。
任务执行脚本为将 Alluxio 表添加与 HDFS 表相同的分区。
分区添加完成之后,Alluxio 会自动从 mount 的 HDFS 路径完成数据同步。
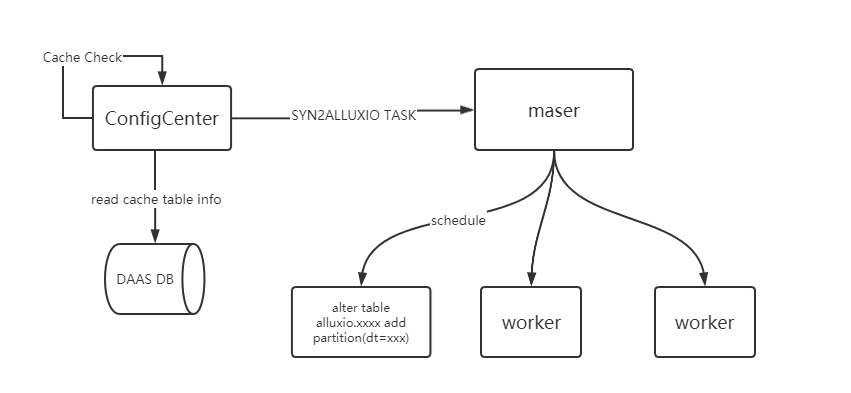
图 11. Alluxio 缓存表同步
人群计算任务
上小节介绍了如何让 Alluxio 和 HDFS 的 Hive 表保持数据同步,接下来需要做的就是让任务计算的 Spark 任务跑在 Spark 与 Alluxio 混部的集群上,充分利用数据的本地性以及计算资源的隔离性,提高人群计算效率。
人群标签计算的 SQL 样例如下:
INSERT INTO hive_advert.cd0000127760_full SELECT result_id, '20210703'FROM (SELECT oaid_md5 AS result_id FROM hdfs.ads_tags_table AS ta WHERE ta.dt = '20210702' and xxxxxxx) AS t上面是一个 Spark SQL 的 ETL,此处的 hdfs.ads_tags_table 即为人群计算依赖的底表,此表为一个 HDFS location 的表。
人群服务通过调用数据服务执行。数据服务根据底表分区是否同步到 Alluxio 决定是否需要下推是用 Alluxio 表来完成计算。如果底表数据已经同步到 Alluxio,则使用 Alluxio 表来做为底表计算人群。
下推逻辑是用 Alluxio 的表名替换原表,假设此处缓存的 Alluxio 表名为 alluxio.ads_tags_table,那么原 SQL 就会被改写成如下:
INSERT INTO hive_advert.cd0000127760_full SELECT result_id, '20210703'FROM (SELECT oaid_md5 AS result_id FROM alluxio.ads_tags_table AS ta WHERE ta.dt = '20210702' and xxxxxxx) AS t依靠数据服务调度系统,通过用户 SQL 改写以及 Alluxio 和 Spark 计算结点混部模式,人群计算任务提速了 10%~30%,详见《唯品会实践案例:基于Alluxio优化电商平台热点数据访问性能》。
小结
虽然截至今天,Hera 数据服务已经支持了很多生产业务,但目前仍有很多需要完善的地方:
不同 engine 存在同一个含义函数写法不一致的情况。这种情况在 Presto 跟 ClickHouse 的函数比较时尤为突出,如 Presto 的 strpos(string,substring)函数,在 Clickhouse 中为 position(haystack, needle[, start_pos]),且这些函数的参数顺序存在不一致的情况,如何更优雅地支持不同 engine 的差异情况还需要进一步思考。
人群计算采用业界通用的 ClickHouse BitMap 解决方案落地,提升人群的计算效率同时扩展数据服务的业务边界。
数据服务支持调度的 HA 和灾备完善,更好地在 K8s 上进行部署。




