
网剧、网综早已成为人们的“休闲佳品”,除了精彩内容,还有各种贴片广告推送。细心的你也许会发现,这些广告仿佛知你所想,懂你所思,常常能击中你的喜好。这是为什么呢?因为这些广告背后,涉及了机器学习与多维时序预测等技术和场景。要讲清楚这背后的故事,首先,我们要了解什么是广告库存。
什么是广告库存?
在计算广告中,库存指的是广告投放机会的存量,广告投放机会由两个要素构成:媒体与流量。
媒体是内容与广告的载体,以视频、音频、文字等不同形式提供内容与广告位;流量则关乎广告投放机会的存量与价值。广告机会的价值取决于流量本身,由高消费潜力用户构成的流量价值自然更高些;广告机会的存量则很大程度由用户的观看习惯、浏览习惯所决定。举例来说,一集 50 分钟的《后翼弃兵》,媒体平台以前贴片、中贴片和后贴片的方式总共设置 4 个广告位,如下图所示。
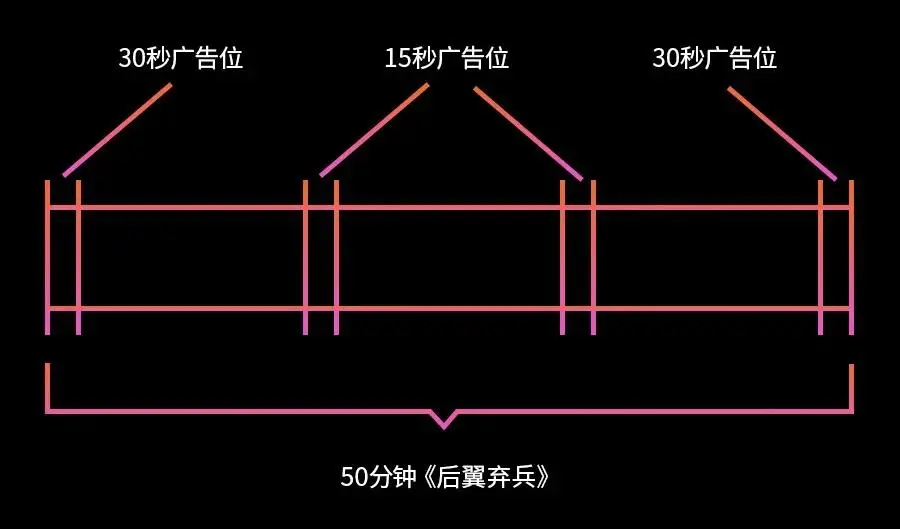
广告机会示意
对于任何一个观看这集《后翼弃兵》的用户,视频中的广告位都是如此设置,但是,至于这 50 分钟的视频到底能提供多少个广告投放机会,那就因人而异了。比如有两个用户,李雷和韩梅梅,李雷将视频从头看到尾,甚至把正片结束后 30 秒的后贴片广告也看完了,那么李雷提供的广告投放机会就是 4;韩梅梅则没那么有耐心,视频看了 1/3,看到第二个广告之后便把视频关掉,那么韩梅梅提供的广告投放机会是 2,即便后面 2/3 的视频内容中还有两个广告位,但是已经没有机会展示出来了。
在计算广告业务中,库存预测扮演着重要角色。对于品牌广告,买卖双方交易撮合的前提是不同定向条件下广告库存的准确预测;效果广告中,对于交易价格随时间波动的媒体流量,如果能够有效预测其在未来一段时间的概率分布,那么作为买方的市场参与者在预算固定的情况下对于流量的竞买会更加游刃有余。
预测广告库存:多维时序预测
基于上面的示例,应该更容易理解:本质上,广告库存是不同用户画像下广告投放机会的存量。那么,广告库存该如何预测呢?既然广告库存取决于流量且按照定向条件(用户画像)划分,那我们自然想到将这个业务问题转化为多维时序预测,一旦有了技术方向,剩下的就是技术选型问题了。无论是从用户视角出发的用户画像,还是从广告主视角出发设置的定向条件,本质上都是不同维度的交叉组合。
例如,给定性别、年龄、所在省份三个刻画维度,至少有 2x100x52 种组合来刻画不同的人群,如果以小时为单位统计不同人群贡献的广告库存,那么每一个人群都有与之对应的库存序列。显然,有多少人群,就有多少广告库存序列——这也正是多维时间序列名字的由来。对于多维时序预测场景,计算广告公司 FreeWheel 至少有 3 种技术方案。
关于 FreeWheel:
作为一家计算广告公司,FreeWheel 为数以千计的欧美客户提供品效广告投放服务,基于长达 14 年的广告投放经验,FreeWheel 致力于打造囊括私有市场和开放市场的统一广告交易平台,为媒体与广告主建立高效连接,力图帮助广告主在以成本优势有效触达目标用户的同时,最大化电视媒体与互联网媒体的流量利用率。
3 种技术方案如下图所示:

不同技术方案优缺点
在 FreeWheel 的业务场景中,我们需要基于种类众多的定向条件(内容来源、地理位置、播放设备、用户画像等)以小时为粒度预测未来 3 个月的广告库存。这样的业务需求至少面临 4 个方面的挑战:
众多定向条件的交叉组合造成维度爆炸,维度爆炸又带来数据分布的长尾效应;
维度爆炸带来的工程复杂度。如果为每个序列构建时序模型,那么工程与运维成本无法想象;
超长时间序列。在传统的金融时序预测中,预测周期往往不超过 120 个时间单元,但在 FreeWheel 的场景中,需要向前预测 2160(24x90)个时间单元;
海量数据挑战。FreeWheel 日投放广告量达到 10 亿级规模,为了向前预测 2160 个时间单元,至少需要回溯同样长的时间周期,也就是说至少要回溯 3 个月的数据,数据规模可想而知。
机器学习团队的主要职能在于利用机器学习算法赋能业务,团队的核心竞争力在于算法,专注于机器学习在计算广告业务中的应用与落地。与专职算法研究不同,算法的应用与落地要求团队同时具备算法钻研与实现、模型调优、工程交付等多方面的能力。受限于团队规模与有限的人力资源,FreeWheel 无法承受庞大的工程与运维成本,因此上表的方案 1 被迅速排除。
方案 2 虽然在一定程度上降低了工程成本,但是训练阶段先聚类再时序预测、推理阶段先预测再反归一化的非端到端流程依然比较繁琐,非端到端解决方案的主要痛点在于工程耦合组件较多,耦合组件过多带来的副作用就是端到端的稳定性较差。为了将后期运维成本降至最低,我们最终还是选择了上表中的方案 3。尽管方案 3 涉及的深度模型复杂度较高、调优挑战较大,但这正是团队的核心价值所在。
技术方案敲定后,接下来需要考虑的是采用哪些技术栈。众所周知,端到端机器学习流水线至少囊括以下环节:

FreeWheel 通常使用 Presto 分布式数据库来拉取数据源,然后利用高效的分布式计算引擎 Apache Spark(Databricks 商业版本)来进行数据预处理、特征工程和样本工程。就机器学习算法来说,Spark 的 ML 算法库提供了丰富的经典算法实现并且支持大规模样本量下的分布式模型训练。不过,对于参数量动辄百万甚至上亿的深度模型来说,模型并行是刚需,Spark 基于数据并行的实现方式便有些力不从心,超大规模的深度学习模型在单点中的存储与更新已然超出硬件资源上限,从而导致模型训练无法顺利完成。
鉴于此,FreeWheel 采用支持模型并行机制的 TensorFlow 来实现自定义的深度学习模型。得益于 Keras Functional API,FreeWheel 很快便实现了定制化的深度网络结构,并在单机环境中跑通了训练流程,接下来便是基于 3 个月体量的大规模样本在分布式环境下不停地迭代、调优模型。对于算法人员来说,网络结构调整、超参调优是“家常便饭”,周而复始的迭代对分布式训练环境的稳定性与运行效率提出了较高要求。就目前来说,TensorFlow 的分布式部署主要有如下几种方式:

三种部署方案各有千秋,基于 Spark 或 YARN 的部署方式适合已经部署 Hadoop 生态的数据和算法团队;而基于 Kubernetes 的部署方式则非常有利于离线模型训练与在线模型服务的融合与统一。不过,对于这三种部署方案,我们不难发现这其中的每一种都需要 TensorFlow 与底层框架的集成与耦合,对于 FreeWheel 机器学习团队来说,没有额外的时间和精力来搭建这样的分布式训练集群。对于一个规模小、专注于算法研究与落地的团队来说,FreeWheel 最需要的是“召之即来、挥之即去”的分布式训练环境,按需而用,用完即弃。于是,FreeWheel 调研了多种云原生的分布式机器学习平台,并最终选择了 Amazon SageMaker 来实现分布式模型训练、调优、部署,从而打通整条端到端大规模机器学习流水线。
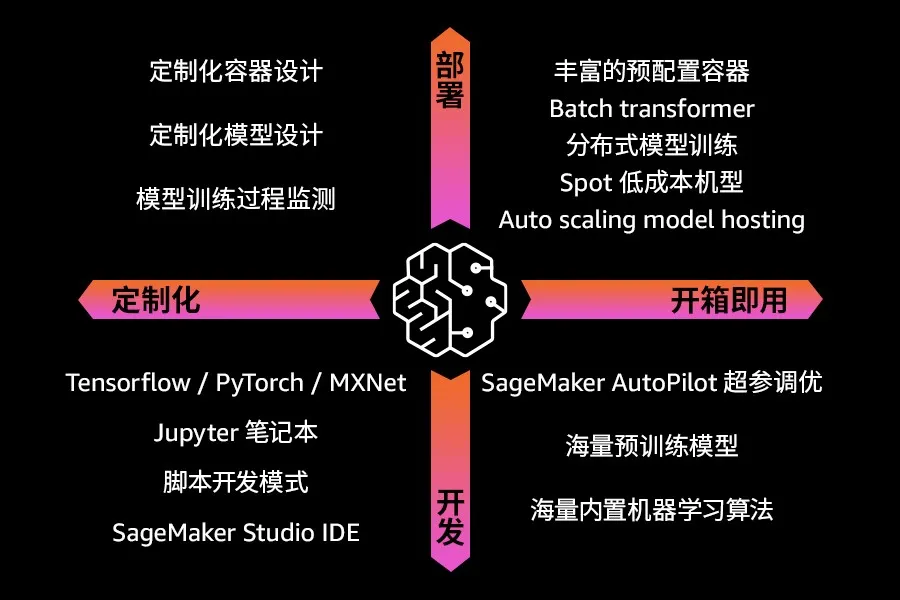
为什么选择 Amazon SageMaker?
Amazon SageMaker 从开发到部署,以开箱即用和深度定制化两种方式提供了完备的分布式功能集合。
在开发方面,Amazon SageMaker 提供的 Jupyter notebook 与脚本模式允许开发者根据业务需要充分定制深度模型,开发者仅需几行框架代码(Skeleton code)即可将现有的 TensorFlow 代码迁移至 Amazon SageMaker,仅需几个有限的参数即可按指定机型、数量自由启停分布式训练集群。对于分布式模型训练,Amazon SageMaker 在模型并行方面支持两种实现方式:参数服务器与 Horovod,在硬件资源方面支持 CPU 与 GPU,这种开放性允许开发者结合业务场景(图像识别、分类回归、时序预测等)灵活地构建运行时环境。
在模型训练过程中,Amazon SageMaker Console 提供的可视化面板让开发者可以及时监测模型训练过程、收敛情况、拟合能力、泛化能力,从而使开发者在下一轮迭代中做到有的放矢。对于模型调优,算法人员最头疼的无疑是超参调优、网络结构变更、激活函数、学习率、优化函数等等,不一而足。对于深度模型,网格搜索和随机搜索逐渐淡出视野,超参调优的趋势是利用机器学习来调优机器学习,即用机器学习的方法来选择超参数;值得一提的是,在 Auto ML 如火如荼发展的当下,作为其中一个门类,超参调优被应用得最为广泛。Amazon SageMaker 的 Auto Pilot 为自动超参调优赋能,允许开发者以开箱即用的方式充分享受 Auto ML 发展的红利。
在部署方面,Amazon SageMaker 提供的 API 允许开发者以按需方式启停分布式训练集群,按需而用、按需付费、用完即停,这完美契合了 FreeWheel 机器学习团队对于分布式训练集群的核心诉求。不仅如此,Amazon SageMaker 自 2017 年底开始支持 Spot 机型,这一机型的支持使 FreeWheel 的云上成本在现有的基础上又降低了至少 50%。Amazon SageMaker 为开发者提供的功能集合完备而全面,鉴于篇幅有限,难以一一陈述。
那么,Amazon SageMaker 如何助力 FreeWheel 实现大规模多维时序预测?效果与收益如何?
2021 年 1 月 13 日,亚马逊 re:Invent 2020 计算广告与营销主题专场会议《Distributed machine learning for digital video and TV ad serving》(Session ID: ADM302)中,AWS 资深开发者布道师王宇博联袂 FreeWheel 机器学习团队负责人吴磊,为您倾情讲述个中细节,敬请期待!




