
2026 年伊始,大模型产业的叙事逻辑正在发生一场深刻的裂变:如果说 2024 年和 2025 年的主旋律是“模型跑通”和“百模大战”,那么进入 2026 年,企业级用户最头疼的问题已经变成了“哪个 API 更好用”以及“如何保证调用不掉链子”。
在这一背景下,1 月 29 日在北京举行的「Ping The Future:智能跃迁,路由新境——清程 AI Ping 产品发布会」显得尤为及时。这场发布会不仅是一次产品亮相,更是对大模型进入“工程化下半场”的一次集体把脉。
为什么在 2026 年的今天,诊断大模型的好坏变得如此重要?为什么“智能路由”会成为像清程极智这样的基础设施公司关注的焦点?这要从目前大模型行业面临的“三大痛点”说起。
目前,企业在接入大模型时,普遍面临着以下三个“既要又要还要”的困境:
痛点 1:API 服务的“盲盒化” (Stability Crisis) 目前的模型 API 市场鱼龙混杂。同一款模型,由不同供应商提供,其响应速度和成功率可能天差地别。企业往往在遭遇大规模调用失败后,才发现后端服务早已“掉线”。
痛点 2:成本与性能的“跷跷板” (Cost TCO) 顶尖模型(如 GPT-5 或同级别国产大模型)极贵,轻量级模型虽然便宜但智力不足。在数以万计的调用中,如何不为了“杀鸡”而动用“牛刀”?
痛点 3:供应商锁定与迁移成本 (Vendor Lock-in) 企业如果只依赖一家模型商,一旦其服务波动或策略调整,业务就会瘫痪。但接入多家 API 又面临协议不统一、负载均衡难等工程化难题。
此外,清华大学教授郑纬民在发布会上指出,当前人工智能基础设施的核心任务正在发生变化。
过去,AI Infra 主要服务于大模型的训练与推理,解决“如何生产智能”的问题;随着模型生态不断丰富和智能体广泛应用,行业正在进入以“智能流通”为核心的新阶段,更加关注模型能力如何在真实业务中高效、稳定地被使用。
他表示,实现智能流通的关键在于智能路由能力建设,其中既包括在多模型环境下为不同任务选择最合适模型的“模型路由”,也包括在同一模型的多种 API 服务提供者之间进行性能与成本优化调度的“服务路由”。两类路由能力协同发展,将形成完整的 AI 任务分发网络,决定人工智能系统的最终效率和使用成本。

图说:清华大学教授郑纬民
清程极智 CEO 汤雄超完整地介绍了清程极智的企业定位和产品布局,他表示,从大模型训练与微调,到推理部署的高性价比实现,再到应用阶段对服务稳定性和使用效率的更高要求,AI Infra 的关注重点正在不断演进。
他介绍,清程极智长期围绕大模型训练、推理和应用三类核心场景开展技术实践,先后推出八卦炉训练系统和赤兔推理引擎,支撑模型在多种算力环境下的高效训练与部署。随着 AI 应用和智能体快速发展,模型能力如何在真实业务中高效流通成为新的关键问题。基于这一背景,清程极智推出 AI Ping,一站式 AI 评测与 API 服务智能路由平台,完善大模型应用阶段的基础设施能力。

图说:清程极智 CEO 汤雄超
在产品发布环节,清程极智联合创始人,AI Ping 产品负责人师天麾对 AI Ping 平台进行了系统地介绍。AI Ping 聚焦大模型服务使用环节,围绕模型服务评测、统一接入与智能路由等核心能力,构建起覆盖“评测—接入—路由—优化”的完整链路。平台以真实业务场景为导向,对不同厂商、不同模型 API 的延迟、稳定性、吞吐与性价比等关键指标进行长期、持续观测。
目前,AI Ping 已覆盖 30 余家中国大模型 API 服务商 ,在统一标准与方法论下对模型服务能力进行对比分析,为企业在复杂的模型与服务选择中提供更加理性的决策参考。
发布会当天,清程极智与华清普智 AI 孵化器(T-ONE Innovation Lab)联合发布了《2025 大模型 API 服务行业分析报告》。该报告基于 AI Ping 平台 2025 年第四季度的真实调用数据与持续性能监测结果,从模型、服务商与应用场景三个维度,对当前大模型 API 服务的供给结构与使用特征进行了系统分析。
报告指出,根据各开源模型请求数据,以总请求量排序,DeepSeek-V3/R1 位居首位、其后为 DeepSeek-V3.2,随后进入高调用梯队的是千问(Qwen)家族的多款模型,包括 Qwen3-32B、Qwen2.5-72B 与 Qwen3-235B-A22B 等。整体而言,头部模型呈现出“少数强势型号占据大盘、同一模型家族内多版本并存” 的结构特征。
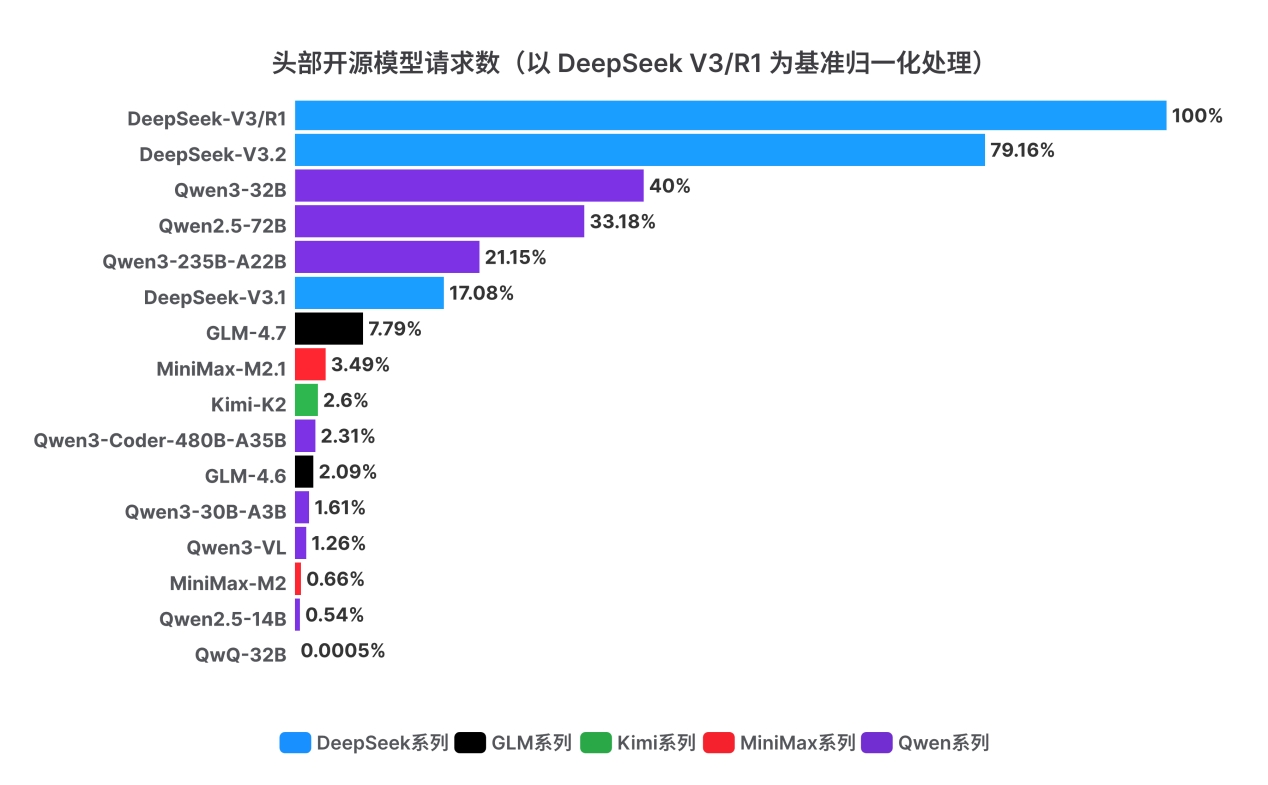
图说:头部开源大模型总请求次数(归一化处理)
同时,报告研究团队观察到,Qwen2.5-72B 的调用量维持在较高水平,这一现象在“新模型加速迭代”的叙事下具有一定反直觉性。一个合理解释是,近期新发布模型在 70B 量级的稠密(dense)架构供给相对稀缺,而部分存量 AI 应用在工程实现、效果调优与线上回归体系上,曾围绕 Qwen2.5-72B 与 Llama3-70B 等稠密模型完成了较为充分的验证与沉淀。在此背景下,终端用户更倾向于继续采用已被业务场景验证的“稳定基线”,而非立即迁移至理论能力更强但尚未完成工程 化与业务闭环验证的新模型。
换言之,模型选择不仅由模型能力上限决定,也受到迁移成本、线上风险与可验证性约束的共同塑造。
类似的“版本并存”现象亦体现在同一模型家族内部:尽管 Qwen3-32B 与 QwQ-32B 同属千问系列模型,参数规模接近且 Qwen3-32B 发布时间更晚,但 从调用结构看,Qwen3-32B 尚未完全替代早期的 QwQ-32B。同样地,DeepSeek -V3.1 与 DeepSeek-V3.2 的推出并未完全挤出 DeepSeek-V3 的存量份额。这表 明,模型迭代并不必然带来“单调替换”,而更常呈现为多版本在不同任务偏好、 推理成本与既有集成依赖下的分层共存。
报告进一步统计了各开源模型被各个平台的支持程度,按模型所属系列进行聚合。
从下图中可见,DeepSeek 是最受服务商欢迎的模型系列。aiping.cn 下共收录 29 家服务商,头部的模型 DeepSeek-V3/R1、DeepSeek-V3.1 均有 23 家服务商支持。如果合并所有支持 DeepSeek 的服务商,共计 24 家服务商支持至少一种 Deepseek 模型。其中的差异是因为 DeepSeek 官方目前仅支持其最新的模型 DeepSeek-V3.2,而不再提供 DeepSeek-V3.1 的服务。
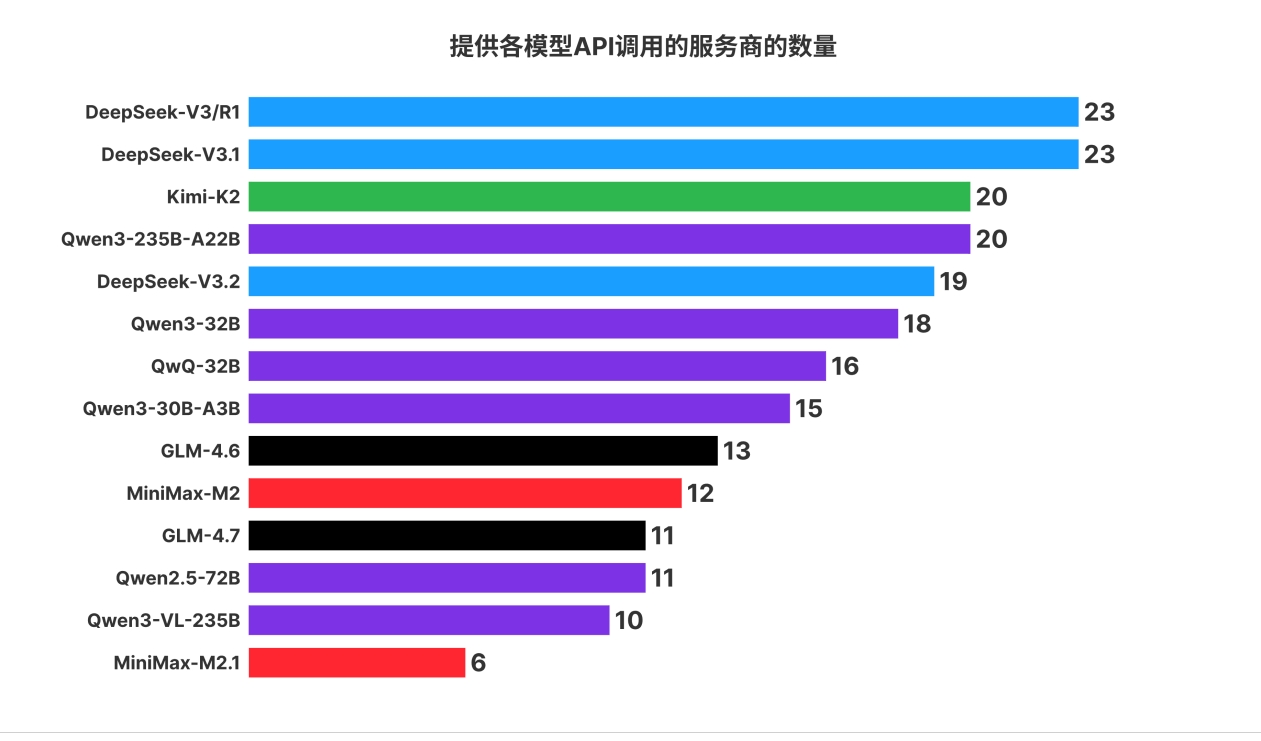
图说:提供各模型 API 调用的服务商的数量
值得一提的是,在模型与服务商高度多样化的背景下,API 服务的核心竞争要素正从“价格差异”转向“交付质量”,包括响应时延、吞吐能力、稳定性与上下文支持等关键指标。
同时,报告通过实证数据表明,在同一模型条件下,引入智能路由机制可在保障可用性的前提下,实现显著的性能提升与成本优化,为大模型 API 服务走向规模化、长期化使用提供了可验证的工程路径。
在圆桌论坛环节,由硅星人合伙人王兆洋主持,来自产业与应用一线的多位嘉宾围绕模型 API 服务的工程挑战、生态协同与产业发展路径展开深入讨论。

参与讨论的嘉宾包括:智谱首席架构师 鄢兴雨、硅基流动创始人 & CEO 袁进辉、投资人 &公众号 thinkingloop 主理人严宽、蓝耘 CTO 安江华、chatexcel 创始人 & CEO 逄大嵬以及清程极智联合创始人 师天麾。与会嘉宾结合各自在模型研发、平台服务与应用落地中的实践经验一致认为,随着大模型应用不断深化,模型服务正在从“可用”阶段迈向精细化运营阶段,评测体系、服务路由与统一管理能力将逐步成为支撑下一阶段规模化应用的重要基础设施能力。
随着 AI Ping 平台的正式发布及生态计划的启动,模型 API 服务这一长期处于“幕后”的关键环节正逐步走向台前。清程极智 CEO 汤雄超表示,未来将通过持续的评测实践与开放协作,推动大模型服务向更加稳定、透明和可持续的方向发展,为人工智能在真实业务场景中的规模化落地提供支撑。




