
LinkedIn 推出认知记忆智能体(Cognitive Memory Agent,CMA),作为其生成式 AI 技术栈的组成部分,旨在构建具备状态感知与上下文理解能力的 AI 系统,使其能够在交互过程中留存并复用知识。该系统主要用于支撑招聘助手(Hiring Assistant)等应用,解决了大语言模型工作流中的一个核心问题:缺乏状态记忆,进而导致无法跨会话保持连贯交互。
CMA 充当应用智能体与底层语言模型之间的共享记忆基础设施层。应用智能体无需通过重复提示词来重建上下文,而是通过这套专用系统来实现记忆的持久化存储、检索与更新。这既实现了跨会话连贯的交互,减少了冗余推理,也能在用户上下文持续变化的生产环境中提供更优质的个性化体验。
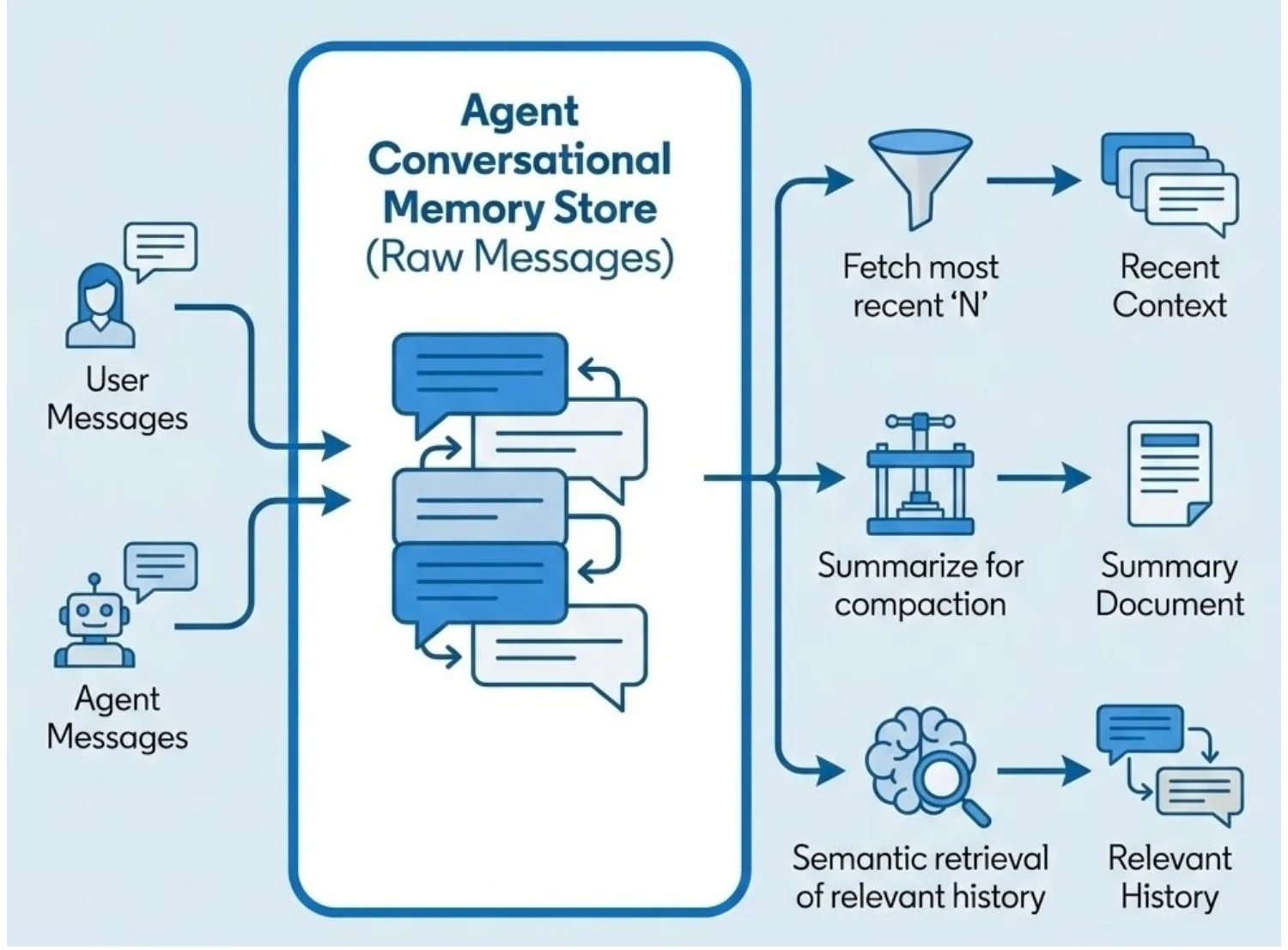
会话记忆层示意图(来源:LinkedIn 博客文章)
该架构将记忆划分为三个不同层级。情景记忆(Episodic memory)用于捕获交互历史与对话事件,让智能体能够回忆过往的交流内容。语义记忆(Semantic memory)存储从交互中提炼出来的结构化知识,支持对用户、实体及偏好等持久化信息进行推理。程序记忆(Procedural memory)对已习得的工作流程与行为模式进行编码,帮助智能体优化任务执行策略。三层记忆协同作用,使智能体的行为从单次响应升级为长期自适应演进。
LinkedIn 工程师 Xiaofeng Wang 在一篇帖子中指出:
记忆是构建生产级智能体最具挑战性、同时也最具价值的核心模块之一,它能够实现真正的个性化、交互连续性与规模化适配。
CMA 在多智能体系统中同样扮演着关键角色。与让每个智能体各自维护独立上下文不同,CMA 提供了一个共享记忆底座,让负责规划、推理与执行的各类专业智能体可以共同访问。这一共享层减少了状态冗余,提升了协作效率,并确保分布式工作流输出结果的一致性。
从系统层面来看,CMA 集成了多种检索与生命周期管理机制。近期上下文检索用于保障短期相关性,语义搜索则支持对长期历史交互的调取。通过摘要进行记忆压缩有助于控制存储容量增长,并在规模化场景下维持系统的性能。这些机制也带来了关键的工程挑战,包括相关性排序、过期内容管理以及不断演变的用户上下文的一致性维护。
LinkedIn 杰出工程师 Karthik Ramgopal 强调了智能体系统向持久化上下文转型的重要性,他表示:
优秀的智能体 AI 不是无状态的:它会记忆、适应与积累。实现这一目标的核心能力之一便是突破上下文窗口限制的记忆能力。
在运营层面,持久化记忆系统带来了分布式系统中经典的权衡问题。确定需要存储哪些内容、何时进行检索以及如何处理过期数据已成为保障系统正确性的核心问题。
MLOPS 数据工程师 Subhojit Banerjee 强调:
缓存失效是计算机科学中公认的难题之一,很高兴你们明确提出了这一点。提取这类记忆的挑战在于如何准确识别情景边界、处理内容时效性和解决冲突。
在招聘等面向用户的应用场景中,LinkedIn 还将人工校验融入工作流程。这种人机结合的方式能够确保 AI 生成内容始终贴合用户意图与业务需求,尤其适用于高风险决策场景。
CMA 体现了 AI 系统从无状态生成向有状态、记忆驱动的智能体这一更广泛的架构转变。LinkedIn 将 CMA 定位为构建自适应、个性化、协作式智能体系统的横向平台。这一方向也凸显出业界日益增长的共识:生产级 AI 系统并非仅由模型决定,而是由围绕模型构建的记忆、上下文管理及基础设施层共同定义。
【声明:本文由 InfoQ 翻译,未经许可禁止转载。】
查看英文原文:https://www.infoq.com/news/2026/04/linkedin-cognitive-memory-agent/




