
生成式 AI 的投资回报远超预期?Snowflake 调研全球 1900 位企业与 IT 专业人士后发现平均 ROI 高达 41%!点击下载完整报告
Agentic AI 及其影响
Agentic AI 以其类人的自主决策能力,正在深刻重塑现代技术图景。与传统自动化相比,它的不同之处在于能够结合推理、规划和执行,独立完成复杂任务,无需人类持续干预。
凭借该能力,企业得以精简工作流程、降低人力成本,从而实现卓越的运营效率。Agentic AI 通过智能分析情境、灵活适应动态变化、执行复杂多步流程,不仅大幅提速完成任务,更同步提升了任务处理的精确度与规模扩展能力,最终为各行各业带来颠覆性的商业成果。
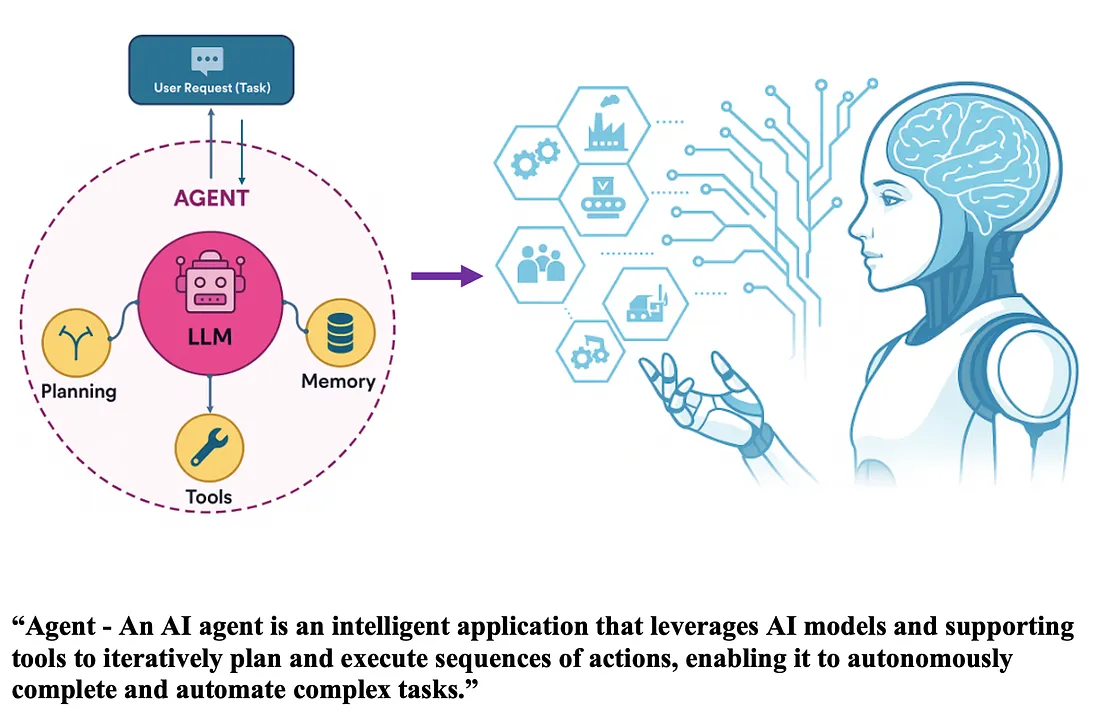
当前,针对 Agentic AI 的起源、发展、技术架构及使用方式,业界已开展了广泛的研究,发表的内容也很丰富。有鉴于此,本文将不再赘述基础知识,而是聚焦于 Agentic AI 部署所带来的安全挑战,并阐释 Snowflake 如何有效地应对与化解这些风险,为其顺利应用扫清障碍。
Agentic AI 及其安全隐忧
尽管 Agentic AI 以其自主的、类人推理能力正变革自动化与决策领域,但这一创新也伴生出一套特有的风险。要确保其安全且规模化地落地应用,解决这些挑战势在必行。
以下,我们将探讨企业必须予以重视的若干重大安全隐患。
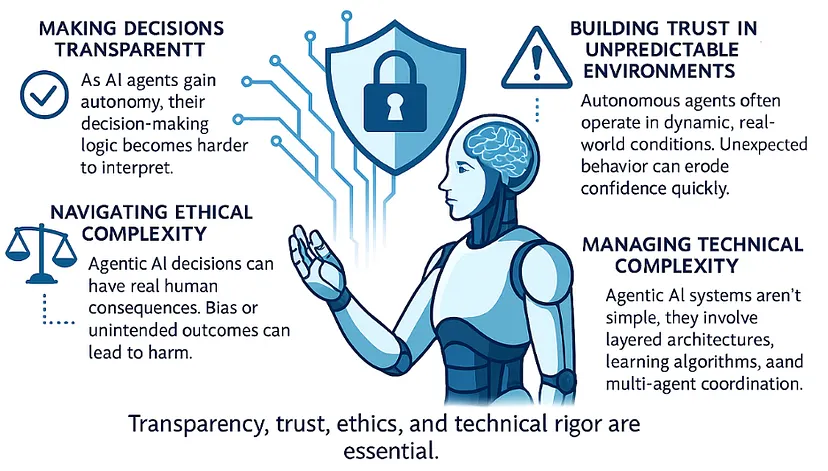
确保决策透明:AI 自主性越高,其决策逻辑变得越难理解。
其重要性何在?用户、企业及监管方都需明确知晓 AI Agent 的决策缘由。如果缺乏透明度,信任将难以维系。
在不可预知的环境中建立信任:自主智能体通常在不断变化的现实世界条件下运行。任何意外行为都可能令信任基础迅速瓦解。
其严重性何在?在医疗和金融等领域,系统的不可预测性已非“不便”可以形容,而是构成了切实的危险。
伦理复杂性的应对之道:Agentic AI 的决策关乎现实影响,任何偏见或非意图的后果,都可能造成危害。
其利害关系在于:伦理上的失误,可能招致法律纠纷并损及声誉。
应对技术复杂性的挑战:Agentic AI 系统本身结构复杂,通常包含多层架构和多种学习算法,并需协调多个智能体间的协作。
其重要性在于:系统的复杂性会显著增加开发、规模化部署以及维护的难度与挑战。
以 Snowflake GPA 框架化解 Agentic AI 安全隐患
为应对自主式 AI 应用中的潜在安全隐患,Snowflake AI 研究团队推出了一套稳健的解决方案——Agent GPA(目标-计划-行动)框架。
Agent GPA(目标-计划-行动)框架围绕 Agentic AI 的完整运作周期(即目标设定、计划制定与行动执行)展开系统性评估。此框架的突出优势主要体现在以下几个方面:
全面诊断:除了开展结果检查外,还能追踪目标、计划与行动全流程中的问题;
逻辑链路剖析与优化:精确定位并修正智能体逻辑中的缺陷;
规模化监管:使大语言模型能够开展可靠的评估工作,大幅降低对人工标注的依赖;
规范化部署:保障目标明确、计划周密且执行到位;
新一代评估体系:融合多步推理能力与外部工具调用,构建面向自主智能体的先进评估范式。
GPA 框架包含五项评估指标,以帮助验证智能体的合理性与真实性。

经 TRAIL/GAIA 数据集验证,Agent GPA 框架表现出显著优异的性能,为应对 Agentic AI 落地安全挑战开辟了路径。详细阐述 Snowflake GPA 框架的研究论文已正式发表,题为:《您的智能体目标、计划与行动是什么?评估智能体目标、计划与行动一致性的框架》。
在 Snowflake AI 可观测性平台中查看 Agent GPA 框架评估指标
用户可通过开源框架 TruLens 来使用 Agent GPA 框架,实现对 AI 的评估、追踪与优化。此外,也可直接通过 Snowflake AI 可观测性平台调用此框架,用以校验智能体的目标、计划与行动是否一致。
如下所示,可通过 Snowflake AI 可观测性平台,导出并评估特定 RAG 应用的 GPA 框架评估指标:
1. 通过 TruLens 库进行指标的调用与跟踪:
> 启用 TruLens-OpenTelemetry,开启追踪与可观测功能。

> 设置元数据(包括应用程序名称和版本),并创建 Snowpark 会话以存储实验数据。

> 完成实验运行的配置,并将运行实例添加至 TruLens。

> 使用已备好的测试集启动实验运行。启动后,系统会读取您在该次运行中配置的数据集输入,并批处理地调用应用程序。

评估指标为衡量 RAG 应用的准确度与性能提供了量化依据;
指标采用“LLM 裁判”范式计算:由一个大语言模型根据给定信息,输出一个 0 到 1 的评分及相应的解释说明。

RAG 评估框架基于三个核心维度:上下文相关、依托性和答案的相关性;
通过此类针对性评估,可准确定位 RAG 系统性能问题的根源;
此类评估也“无需参考答案”,即无需借助基准数据。

2. 分析指标,迭代优化
> 查看所有应用程序,按以下路径进入:Snowsight→AI & ML→Evaluations

> 查看某个应用程序对应的所有运行:选择该应用程序,即可显示运行列表。

> 查看某次运行的评估结果:选择该运行,即可查看其汇总结果以及每条记录对应的详细结果。

> 查看某条记录的详细信息:选择该记录,即可查看其完整的执行过程追踪、元数据以及相关的评估结果。

由上述结果可见,本次 RAG 应用的三个核心评估维度(答案相关性、上下文相关性与依托性)得分分别为 1.0、0.83 和 1.00,这表明了该应用在当前场景下的真实可靠性。如有需要,我们可以回溯推导步骤,依次验证模型、流程、计划、目标及行动的合理性,并通过迭代修正来确保其达标。
点击链接立即报名注册:Ascent - Snowflake Platform Training - China




