
演讲嘉宾 | 尹辰轩、北银金科高级算法专家
大模型的出现让一切需要与人进行交互的领域都有了新的技术方案,投顾领域也将迎来大模型时代。通用型的大模型,在专业领域上的深度思考以及幻觉风险使得在投顾这种强合规领域上应用速度慢。
本文整理自北银金科高级算法专家尹辰轩 6 月份在 AICon 2025 北京站 的分享《大小模型协同在智能投顾领域的应用》。本次演讲分享了大小模型协同架构下的大模型投顾方案,利用传统量化小模型的精准性和高性能,结合大模型 Agent 的搭建,实现问题识别、任务扩写、API 调用小模型以及答案融合。该方法可以基于任意基础大模型进行行业级扩展,经过测试,基本解决幻觉问题,并大大优化了回答的深度。
12 月 19~20 日的 AICon 全球人工智能大会将在北京举办!聚焦企业级 Agent 落地、上下文工程、AI 产品创新等多个热门方向,围绕企业如何通过大模型提升研发与业务运营效率的实际应用案例,邀请来自头部企业、大厂以及明星创业公司的专家,带来一线的大模型实践经验和前沿洞察。
以下是演讲实录(经 InfoQ 进行不改变原意的编辑整理)。
智能投顾的前世今生
在智能投顾这一业务场景中,我们尝试用“大小模型协同”的架构,对传统金融业务做了一次 AI 原生的再创造。
先回到“智能投顾”本身。这个概念早在十年前就已进入公众视野。2008 年次贷危机后,传统人工投顾因销售道德风险而备受质疑,硅谷随之诞生了两家明星公司——Wealthfront 与 Betterment。有人把这次迁移称作“ToC 金融从华尔街搬到硅谷”。彼时的智能投顾几乎完全依赖“小模型”:无论是 Black-Litterman、均值 - 方差、Risk Parity 这类资产配置框架,还是打分选股、基金筛选等工具,本质都是参数有限的规则引擎。只要轻轻扭动一两个旋钮,收益曲线就可能彻底改向。这种“黑箱”被少数销售机构掌控,佣金落袋后,盈亏却由投资者独自承担。Wealthfront 与 Betterment 的创举,是把所有算法公开、回测、可复制;2013 年,美国金融业监管局甚至专门出台指引,强制要求这类公司把模型透明化。
国内跟进得并不慢。2014 年,行业里陆续出现“拿铁智投”“考拉智投”等原型;同年我回国加入京东,也参与了“京东智投”的雏形设计。2017 年,招商银行推出“摩羯智投”,第一次把智能投顾带进大众视野。然而十年过去,市场始终不温不火。原因并不复杂:投顾圈里常说“三分投、七分顾”,顾问与投资的差异在于“交互”。过去的做法简单粗暴——填一份风险测评,系统吐出一张组合清单,用户照单交易即可。假如王思聪和我都被定为 C5 激进型,系统给出的方案几乎一模一样;可事实上,我们的现金流、负债、储蓄习惯天差地别。没有持续对话,就无法让用户真正理解“为什么给我这个方案”,更谈不上在市场波动中每周、每月与他复盘、调仓。在大模型出现之前,这种高频、人性化、且合规的交互几乎不可能实现。
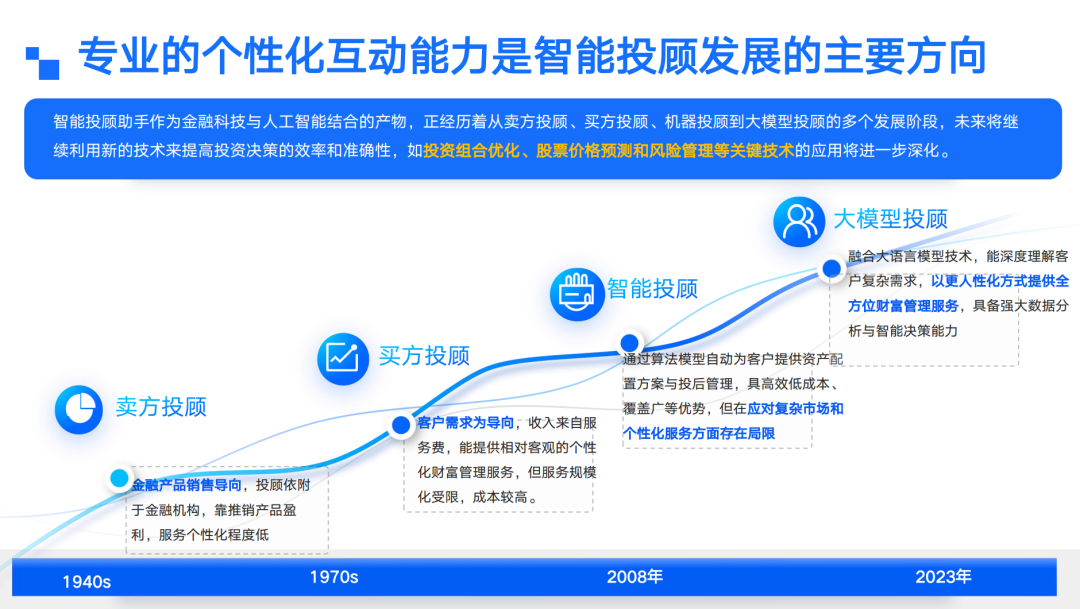
2023 年起,大模型的能力让上述想象落地。国内各家都在迅速拥抱:蚂蚁把原本集成在“支小宝”里的理财问答模块拆成独立品牌“蚂小财”,既满足高合规要求,又能为不同持牌机构(如广发证券、中加基金)建立专属知识边界。在我个人的横向测试里,蚂小财的幻觉比例最低,给出的解释也最易读。同花顺的“问财”则胜在数据:作为老牌数据供应商,它把大模型与 SQL、API 两种主流技术路线同时跑通,分时行情、技术指标选股都能一句话完成;只是语义理解略逊,遇到非标准化提问就容易“跑题”,幻觉也相对明显——我猜测是任务规划链路在高合规场景下容错率太低。至于京东的“京小贝”,目前仍停留在“升级后的客服问答”,距离真正解决用户问题还有一段路要走。

大模型投顾的功能架构
我最近在牵头规划一套面向头部业务的大模型功能架构,核心思路可以用一句话概括:让大模型负责“对话与规划”,让小模型负责“精确计算”。
最底层是数据层,逻辑朴素——有什么数据就接什么数据,不挑不拣。上一层跑的是 DeepSeek:改写、扩写、输出之外,更重要的是任务规划。规划一旦落地,就路由到对应的小模型集群;小模型再把量化结果回灌给大模型,由它翻译成用户听得懂的语言。
ToC 与 ToB 的场景差异在这里被放大。ToC 的问题往往发散,两三轮就结束;ToB 的问题却像连续剧,需要连续追踪,且对幻觉零容忍。幸运的是,头部业务的需求高度收敛,几乎可以被枚举:我现在的财富状况如何?这笔钱怎么投?我不喜欢某只基金,有没有替代?这些意图都可以提前归类,并在任务规划、模型路由、结果封装三个阶段做工程化固化。
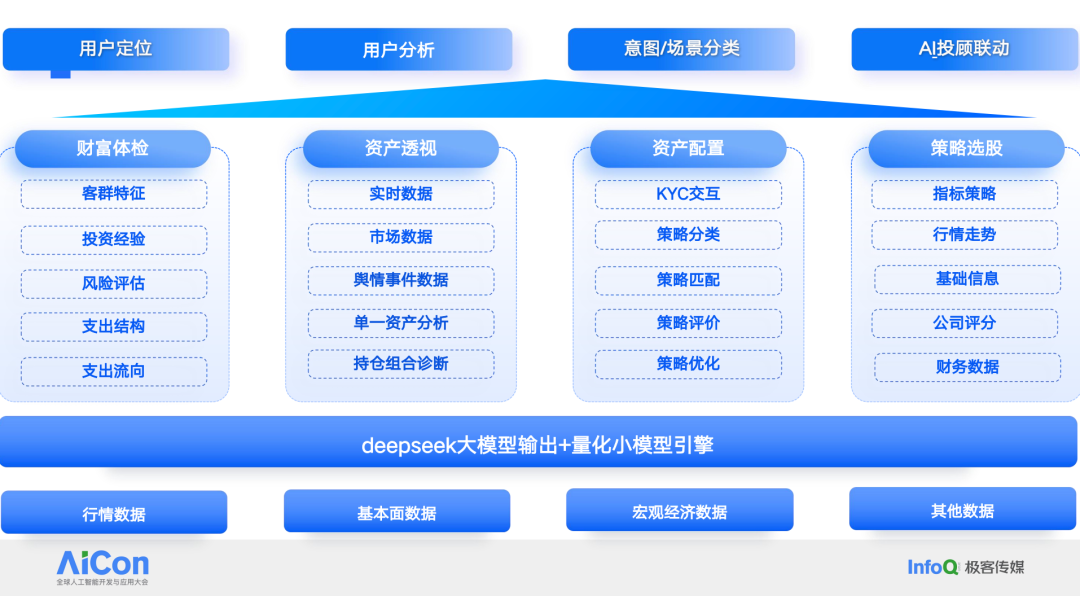
说到小模型,我把它压缩成五类,足以覆盖 95% 的投研投顾需求。
第一类是“基本模型”,只输出最原子的指标,例如某基金过去三年的年化收益率,既可以直接展示,也可以作为更高阶模型的入参。
第二类是“资产推荐模型”,按资产维度拆分:股票、债券、商品……每类资产再挂载各自的量化框架——基本面、技术、舆情、事件驱动,推荐理由因此可追溯。
第三类是“归因模型”,其中一个小功能是 OCR 持仓分析:用户把散落在招商银行、天天基金、支付宝、各家券商的持仓截图上传,系统解析成本、市值,再叠加产品表现与风险偏好,生成统一报告,既方便客户复盘,也成为我们获客的新抓手。
第四类是“资产配置模型”,内置 Black-Litterman、Risk Parity 等引擎,根据风险等级、流动性、负债水平实时调用。
第五类是“分类预测模型”,面向大类资产走势,用一套可扩展的量化算法实现:输入条件不同,输出即时重算。为了让大模型知道何时调用哪台“计算器”,每个小模型都配了一条特征向量:算法名称、适用客群、输入规格、输出形式……全部向量化并打标。这一步粗看繁琐,却是整个系统可解释、可复现的基石。
大模型给出答案之后,我们特意做了一层“二段交互”的 Chatbox。今年资本收缩,AI 预算虽在,却比去年谨慎得多,原因不难体会:除了把大模型当成问答挂件或旧系统的语音助手,真正跑通商业模式的案例仍屈指可数,B 端尤甚。很多老机构烟囱林立,我所在的公司就有四百余套系统,同一条业务链上甚至重复建设;把大模型简单外包在这些烟囱外,只能锦上添花,无法脱胎换骨。
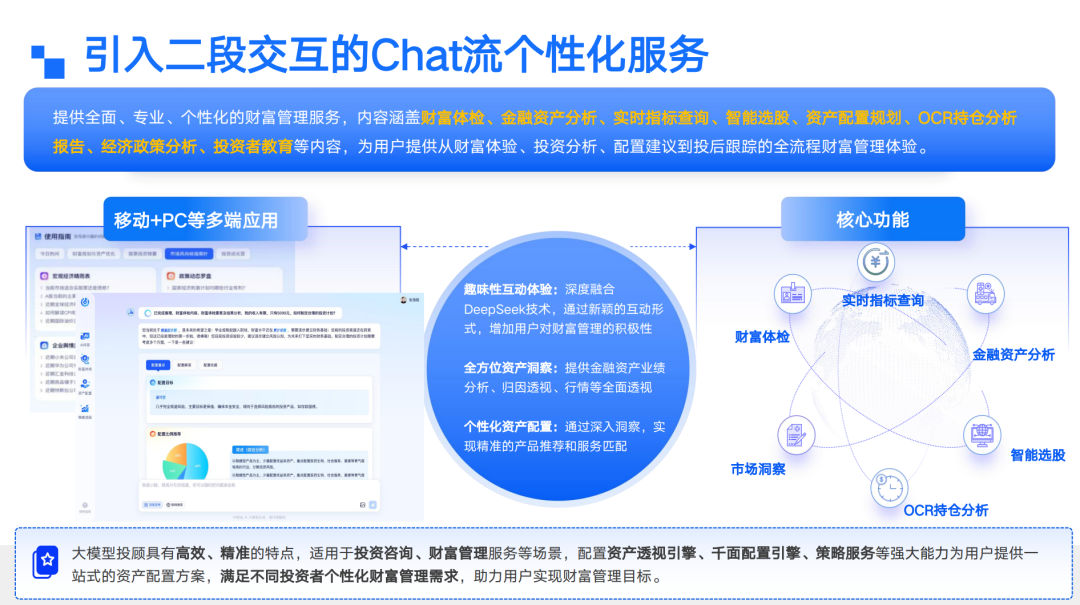
我们的做法是在对话流里埋入“意图识别”。当大模型判断用户需要更深层操作时,不再输出长篇文字,而是直接推送一张卡片——卡片背后就是原有功能页面被打散后的 API。用户点击卡片即可进入该页面,继续完成第二段交互。这样,知识不再被锁在各自孤岛,而是以 API 的形式按需注入对话;大模型不必全知全能,只要能听懂意图,再调用相应模块即可。既省了训练成本,又提高了 B 端场景的准确率,也让旧系统第一次以原生的方式被串联起来。
大小模型协同架构
我们在大小模型协同中要解决的核心问题有三点:幻觉、专业深度、算力成本。
幻觉容忍度低在银行业务里,大模型 1% 的错误可能直接抬高 1% 的不良率,这是不可接受的。C 端场景 99% 的准确率已经足够好,但在 B 端必须逼近 100%。
专业深度不足大模型在通用领域表现不错,但面对量化投研任务仍显稚拙。例如,让它用 Black-Litterman 模型基于近三个月数据为 C3 风险等级用户生成基金组合,输出往往空泛;同样参数交给小模型,可直接给出可验证的结果。
算力成本实测发现,整个链路中大模型占比越高,响应时间越长。若全程使用大模型,回答需 40–50 秒;提高小模型占比后,时间可压缩到 20 秒以内,算力成本直接减半。
在银行场景里,大模型哪怕只错 1%,都可能让不良率直接抬升 1%,这是底线问题;而在 C 端,99% 的准确率已经足够交差。同样一句话,交给大模型去跑量化投研,往往只给出一堆看似合理却经不起复现的结论;换成小模型,同样的 Black-Litterman 输入立刻能输出可验证的组合权重。更现实的是钱和时间:实测发现,整个链路中大模型占比越高,响应时间越长。若全程使用大模型,回答需 40–50 秒;提高小模型占比后,时间可压缩到 20 秒以内,算力成本直接减半。
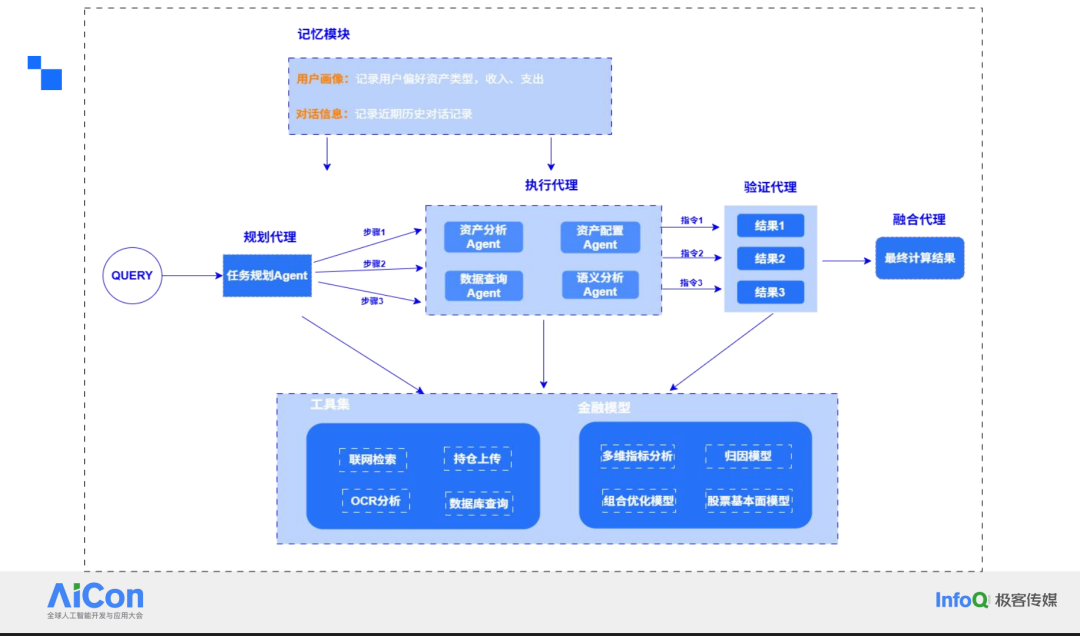
落到工程上,我们把用户 Query 的处理拆成两步。第一步用 DeepSeek 的 Chain-of-Thought 做扩写,把口语、错别字、倒装句统统翻译成带推理链的结构化意图,省去再训专用分类器的麻烦。第二步交给任务规划 Agent:如果用户问“XX 基金怎么样”,系统自动拆成基本信息、业绩曲线、基金经理、舆情事件等子任务,再决定由谁执行——简单事实大模型直接回,数值指标甩给小模型,舆情缺位就 RAG 现抓,图表需求按模板渲染。整个链路里,原有业务规则和量化引擎原封不动,仅以 API 形式被大模型按需调用,协同而不是替代。
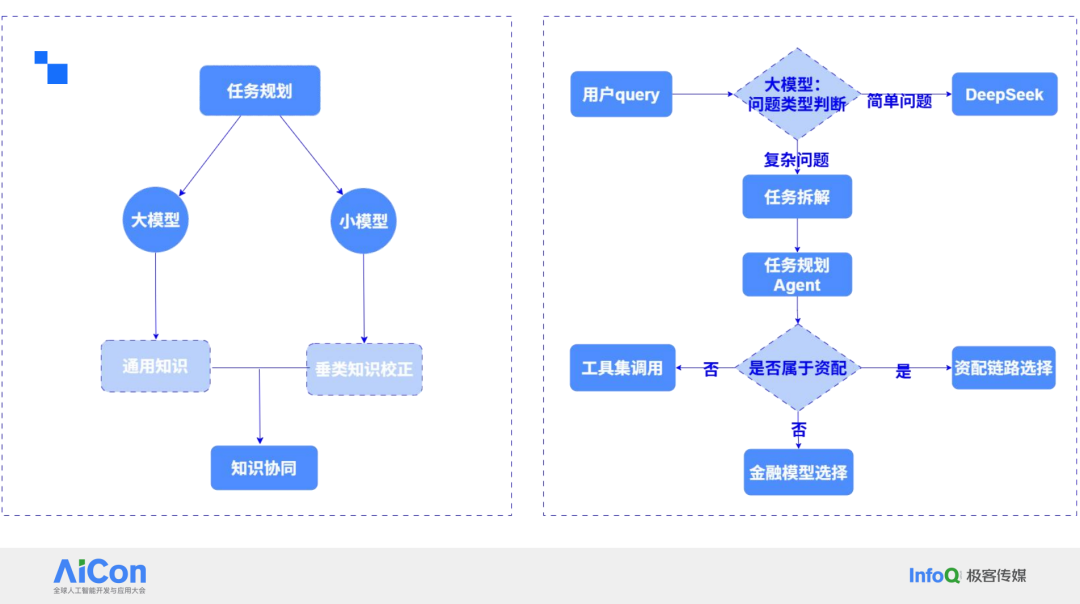
Agent 流程编排
在我们的实践中,Agent 流程安排是一个比较成功的方案。扩写部分基于 DeepSeek 的不同提示词来实现,不同场景下会有不同的扩写方案。这些方案可能会要求大模型按照某种结构输出结果。DeepSeek 是一种语气敏感型加形式敏感型的模型。例如,语气方面,如果要求以专业语气输出、按照报告形式输出,DeepSeek 都会非常敏感。
实际上,让大模型进行扩写并不需要使用参数过高的模型。例如,没有必要使用 671B 参数的模型来进行扩写,32B 的模型已经足够。我们发现,在每个节点上,如果节点有专业用途,可以使用小参数的大模型,甚至是更小参数的专训模型。例如,在任务拆解和内容分段过程中,小参数模型甚至最小的 0.5B 的大语言模型都可能解决问题。目前,我们最大的专训模型是一个 7B 的模型,用于资产配置等意图分类。因此,在每个环节都可以进行优化。
以最常见的 Query 为例,任务拆解后,小模型位于 Agent 之后。无论是使用 Dify 还是其他 MaaS 平台,我们发现现在的 MaaS 平台都支持代码节点或 HTTP API 节点。我们将小模型打包成服务端,直接放在每个 Agent 后面。在 Agent 上,通过提示词和小模型的介绍来确定在什么情况下调用这条链路中的小模型。输出回答后,可能直接调用小模型、查询数据,或者进行联网检索。这些结果出来后,会进行达人融合。达人融合实际上也是一个小型参数的大模型,其主要工作是对回答进行语言润色,调整结构,输出表格等,最终实现对用户问题的回答。
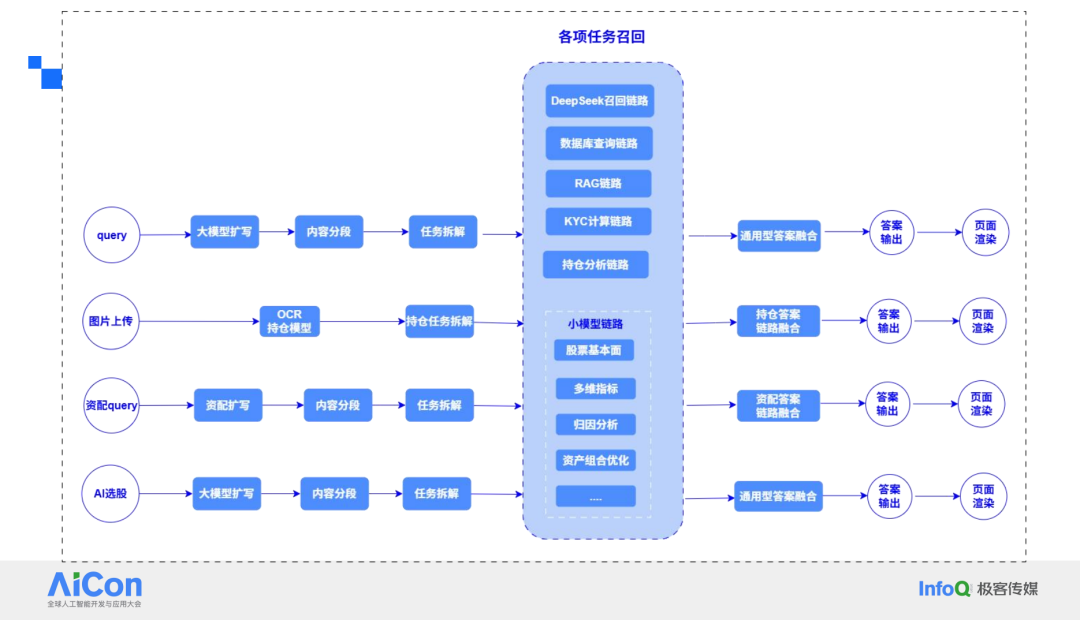
在指标查询流程中,我们目前还在使用转 SQL 的方式。但我个人认为,在数据查询过程中,转 API 的形式也是一条不错的路。在 ToB 业务中,虽然目前有一些如字节的 Data Agent 等 API 出现,但我认为通用性上还没有一套完美的 Text to SQL 解决方案。如果场景确定,Text to SQL 是很准确的实现方式。其优势在于,只要写成 SQL,查询结果一定是准确的。最终,我们将这个任务落在了选股或选基的业务场景中,通过一些指标挑选出所需的理财产品。
大小模型协同的价值与效果
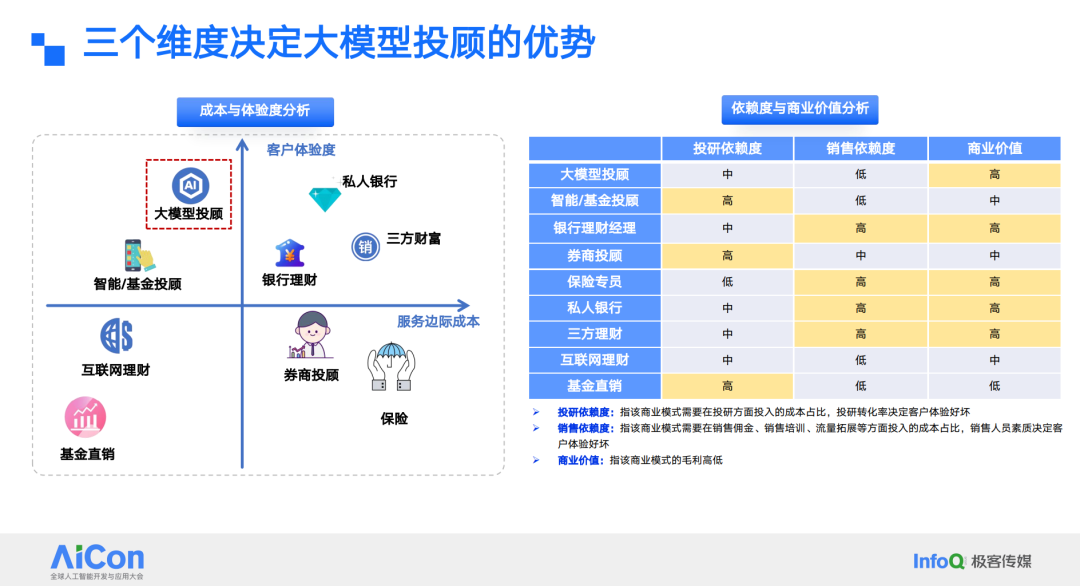
大模型投顾的最大优势在于其互动性和用户体验。与传统的机械化自动化推荐客服相比,大模型投顾在这些方面确实表现出色。从成本角度来看,大模型的固定成本较高,但相比完全依赖人工的方式,总体成本可以节省很多。
在算力方面,我提出了一个概念,即大模型的深度与算力比。这有点类似于自动驾驶领域的情况。对于任何从事自动驾驶的公司来说,将自动驾驶技术做到 90 分的水平,其成本是可控的,因为它们可以利用一些公开的插件或通过 API 接口来解决问题。然而,当技术水平超过 90 分之后,每提升一分所需的投入都会呈指数级增长。
对于金融领域,训练一个通用知识大模型的成本并不高。例如,接入一个通用大模型后,上传一些知识库,编写一些提示词,并搭建一个 Agent,就可以构建一个所谓的金融行业大模型。但是,如果要进一步深入,比如要求模型在投研方面达到专精水平,特别是在撰写股票或上市公司财报方面精通所有财务指标,那么深度训练所需的算力成本将会非常高昂。在这种情况下,将这些专精任务拆分为小模型引擎会更加高效,因为这样可以大幅提高深度算力的利用效率。在相同的专业度下,通过小模型实现的深度回答所需的算力,远远低于将这些知识内化于大模型所需的算力。
我个人认为,大模型的参数主要是对语言规律的总结。由于人类的逻辑和部分知识已经内化于语言逻辑之中,因此当大模型进行语言规律的输出和解码时,它似乎具备了某些知识或逻辑。然而,更复杂、更深入的逻辑可能无法仅通过通用型训练来实现。
去年,我还提到过 Scaling Law,即大模型训练投入算力带来的回报是递增的。但今年,自从 DeepSeek 出现之后,我再也没有听到有人提及这个问题。一定程度上,这是因为 DeepSeek 节省了很多算力。在这个过程中,我认为通过数学量化模型和小模型高度凝练出来的知识,更具深度算力可比性。
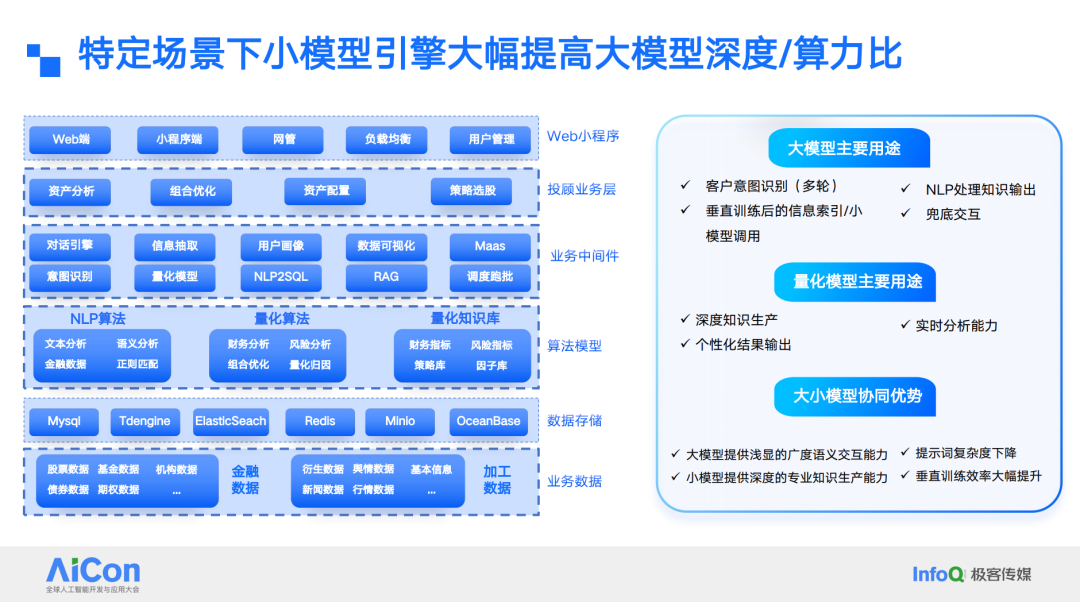
我们通过 Chatbot 方式将所有页面业务逻辑策略进行串联。目前,我们正在将这一模块应用于具体的业务调整中。我们尝试将 3 到 4 个不同的系统拆分为页面和 API,最终实现一个基于 Chatbot 的简单获取专属服务的 ToB AI 原生系统应用。
这种所谓的二段交互方式,可以植入任何原有业务系统的页面和功能。我们通过大模型模拟上线了一些角色,例如巴菲特的投顾角色、格雷厄姆的投顾角色以及某些头部大 V 的角色。我们只需将他们的文章策略上传,并搭建相应的选股或选基模型,就可以根据不同角色为用户提供服务。




