
Azure Kubernetes Service 团队分享了一份详细指南,介绍如何在 AKS 上将动态资源分配(DRA)与 NVIDIA vGPU 技术结合使用。这一更新提升了在 AI 和媒体任务中共享 GPU 的控制能力和效率。
动态资源分配(DRA)如今已成为 Kubernetes 中 GPU 资源使用的标准方式。与 nvidia.com/gpu 这类静态资源不同,GPU 现在通过 DeviceClasses 和 ResourceClaims 进行动态分配。这一变化增强了调度能力,并改善了与 NVIDIA vGPU 等虚拟化技术的集成。
将这些技术结合的原因很明确:像 NVIDIA vGPU 这样的虚拟加速器通常用于处理较小的任务。它允许将一个物理 GPU 切分给多个用户或应用。这种模式对企业级 AI/ML 开发、微调以及音视频处理非常有帮助。vGPU 在为容器化工作负载提供 CUDA 能力的同时,也能带来可预测的性能。
在基础设施层面,该功能依赖于 Azure 的 NVadsA10_v5 虚拟机系列。与将整块 GPU 分配给单个虚拟机不同,vGPU 技术在虚拟机管理程序层将其划分为多个固定大小的分片。从 Kubernetes 的视角来看,每个虚拟机只呈现出一个清晰的 GPU 设备。容量和内存限制由虚拟机管理程序设定,而非软件层控制。
该方案需要 Kubernetes 1.34 或更高版本。在这一版本中,deviceclasses 和 resourceslices 等 DRA 原语已经可用。团队需要使用 NVadsA10_v5 实例创建节点池,并为其打上标签(nvidia.com/gpu.present=true),作为 NVIDIA DRA kubelet 插件的节点选择器。随后,通过 Helm 部署 NVIDIA DRA 驱动。文章强调了三个对 vGPU 场景重要的 Helm 参数。其中,gpuResourcesEnabledOverride=true 用于跳过一项检查,该检查会因为 GPU 名称不同而阻止 NVIDIA DRA 驱动与传统设备插件同时安装。FeatureGates.IMEXDaemonsWithDNSNames=false 则用于禁用一个 IMEX 功能,因为该功能需要比 Azure 上 A10 系列所支持版本更新的 GRID 驱动。
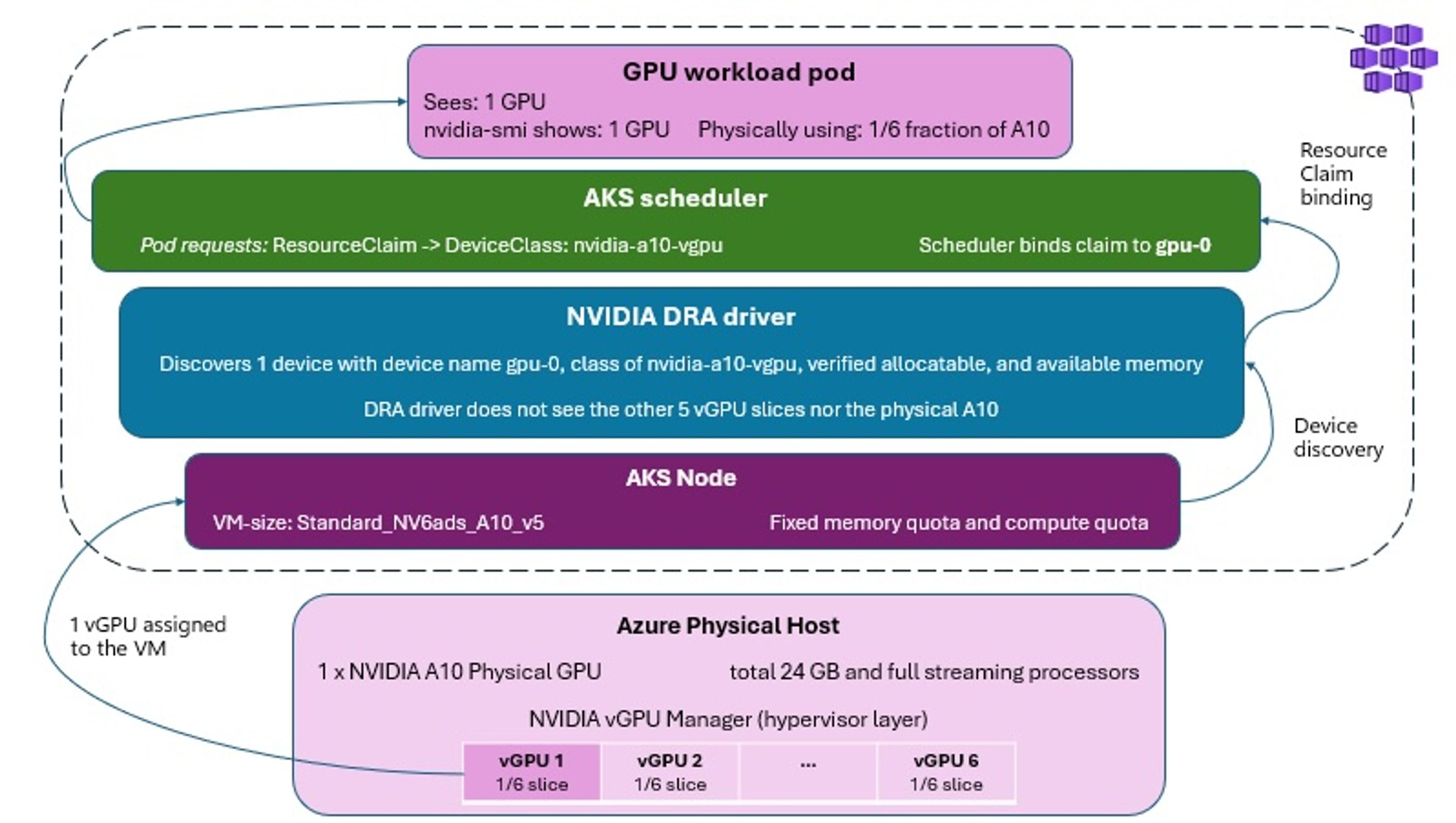
驱动激活后,它会扫描每个节点,从 Azure 虚拟机中检测到单个 vGPU 设备,并将其注册到 Kubernetes 控制平面中,作为由 DRA 管理的设备。每个节点注册一个可分配设备,因为虚拟机只呈现出这一数量。运维人员可以通过查看 gpu.nvidia.com 的 DeviceClass 和 ResourceSlices 来检查配置情况,从而确认控制平面已识别出可用硬件。
除了基础的六分之一切片(Standard_NV6ads_A10_v5)之外,该系列还提供三分之一配置(8 GB 加速器内存)和二分之一配置(12 GB)。这些限制在虚拟机管理程序层执行,因此 AKS 看到的是一个具有可预测容量的单一 GPU 设备。这使平台团队可以根据工作负载需求灵活配置 GPU 分配,而无需过度配置节点。
AKS 团队将这一进展视为一个方向性的变化。随着 GPU 成为 Kubernetes 中的一等资源,将虚拟化 GPU 与 DRA 结合,为运行共享的、生产级工作负载提供了一种务实方案。对于大规模 AKS 部署,尤其是在受监管或成本敏感的行业中,GPU 的最优放置和利用会直接影响任务吞吐量和基础设施效率。将 DRA 与 vGPU 结合,有助于组织从粗粒度的节点级分配,转向基于工作负载驱动、可控且可扩展的 GPU 使用方式。
Google Cloud 在 GKE 上也在推进类似路径,将 DRA 作为 GPU 和 TPU 的调度基础能力。GKE 的 DRA 支持允许工作负载使用 CEL 表达式筛选具有特定属性的设备。这使得同一个清单文件可以在不同集群、不同 GPU 类型下直接部署而无需修改。在 vGPU 方面,Google 最近预览了基于 RTX PRO 6000 Blackwell GPU 的 NVIDIA vGPU 技术所构建的分数化 G4 虚拟机,由 GKE 管理,并结合容器打包(binpacking)以提升利用率。当通过 Google 的动态工作负载调度器进行调度时,回退优先级机制可以改善资源获取。
Amazon EKS 则采取了不同策略,主要利用 DRA 来简化其高端 GPU 硬件的复杂性,而不是做分数化共享。Amazon EKS 从 Kubernetes 1.33 版本开始正式提供 DRA 支持。该技术对于 P6e-GB200 UltraServer 实例至关重要,因为传统的静态 GPU 调度无法描述多节点工作负载所需的 NVLink 和 IMEX 互连。对于运行较小规模工作负载、希望在 EKS 上实现 GPU 共享的团队而言,DRA 现在支持结构化的、基于属性的请求。这使调度器可以响应诸如“一个至少具备 1/7 计算能力的 10 GB MIG 分区”这样的请求,而不再只是将 GPU 视为简单的数量单位。在三大云厂商中,从静态设备插件向 DRA 的转变正在加速,这一趋势源于 AI 基础设施在复杂性和成本上的不断增长,对更具表达能力、具备拓扑感知能力的 GPU 调度提出了需求。
原文链接:




