
微软和英伟达已经发布了他们合作的第二部分,即在Azure Kubernetes Service(AKS)上运行 NVIDIA Dynamo 进行大型语言模型推理。第一个声明的目标是在分布式GPU系统上实现每秒 120 万个 token 的原始吞吐量。现在,这个最新版本专注于帮助开发人员更快地工作并提高操作效率。它通过自动化资源规划和动态扩展功能来实现这一点。
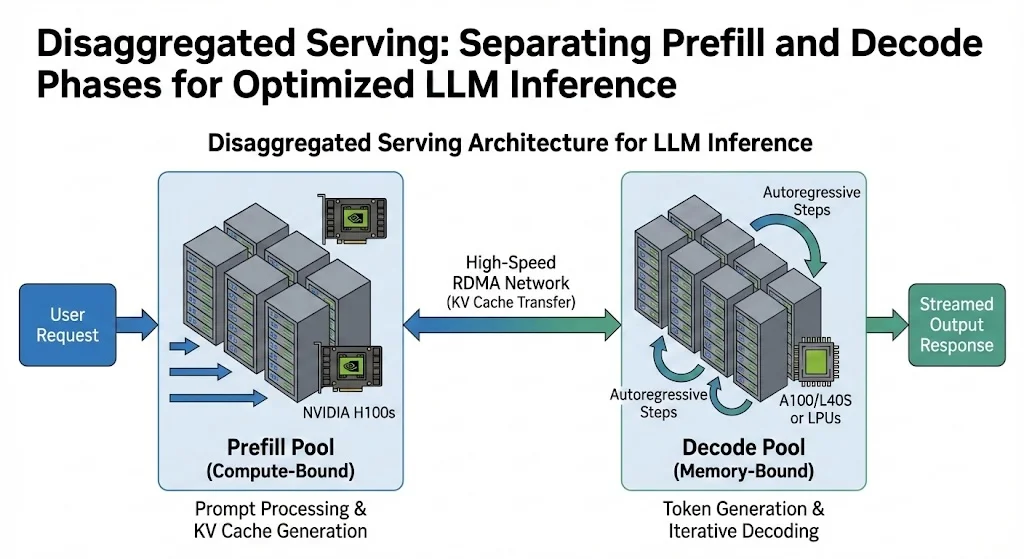
新的功能集中在两个集成组件上:Dynamo Planner Profiler和基于 SLO 的Dynamo Planner。这些工具协同工作,解决在解耦服务中的“速率匹配”挑战。团队在拆分推理工作负载时使用这个术语。它们将处理输入上下文的预填充操作与生成输出 token 的解码操作分开。这些任务运行在不同的 GPU 池上。如果没有合适的工具,开发团队需要花费大量时间来确定这些阶段的最佳 GPU 分配。
Dynamo Planner Profiler 是一个预部署模拟工具。它会自动搜索最佳配置。开发人员可以跳过手动测试各种并行化策略和 GPU 计数,节省 GPU 利用率的时间。相反,他们在 DynamoGraphDeploymentRequest (DGDR)清单中定义自己的需求。分析器会自动扫描配置空间。它测试了预填充和解码阶段的不同张量并行度大小。这有助于找到在保持延迟限制的同时提高吞吐量的设置。
分析器包括一个 AI 配置模式,可以根据预先测量的性能数据在大约 20 到 30 秒内模拟性能。这种能力允许团队在分配物理 GPU 资源之前快速迭代配置。输出提供了一个调整后的设置,以提高团队所说的“Goodput”。这是最高的吞吐量,同时保持第一个 token 的时间和 token 间的延迟在设定的限制内。
一旦系统投入生产,基于 SLO 的 Dynamo Planner 就将接管作为运行时编排引擎。这个组件是“LLM 感知的”,这意味着与传统负载均衡器不同,它会关注集群状态。。它跟踪诸如解码池中的键值缓存加载和预填充队列的深度等内容。规划器使用分析器的性能界限来扩展预填充和解码工作器。这有助于在流量模式变化时满足服务级别目标。
该公告通过一个详细的航空公司助手场景来说明这些能力。在这个场景中,Qwen3-32B-FP8模型支持一个航空公司移动应用程序。它遵循严格的服务级别协议:第一个 Token 为 500 毫秒,Token 间的延迟为 30 毫秒。在正常操作中,系统运行一个预填充工作器和一个解码工作器。当天气中断导致 200 个用户发送复杂的改道请求时,规划器注意到了峰值。然后它扩展到两个预填充工作器,但仍保持一个解码工作器。团队报告说,新工作器在几分钟内上线,允许系统在流量峰值期间维持延迟目标。
这个版本建立在原始 Dynamo 公告中引入的框架之上,InfoQ 在 2024 年 12 月报道了这一点。在上一篇文章中,Azure 和英伟达解释了 Dynamo 的设计如何将计算密集型和内存绑定任务分散到各种 GPU 上。这允许团队独立优化每个阶段,将资源与工作负载需求相匹配。例如,电子商务应用程序的预填充任务可能处理数千个 token,而其解码任务只生成简短的描述。
从手动设置转向自动化、SLO 驱动的资源管理,展示了团队如何在 Kubernetes 上更好地处理大语言模型部署。规划器组件提供了将延迟需求转化为 GPU 分配和扩展选择的工具。这旨在降低运行解耦推理架构的操作负担。自动化工具可以帮助需要推理重或长上下文 LLM 的组织。它们使管理复杂的多节点 GPU 设置变得更容易。它们还支持在变化的流量模式下满足服务级别目标。
原文链接:
https://www.infoq.com/news/2026/01/nvidia-dynamo-ai-kubernetes/




