
Airbnb 可观测性工程团队发布详细的大规模迁移方案:将原有基于 StatsD 与 Veneur 的专有聚合管道迁移至基于 OpenTelemetry Protocol (OTLP)、OpenTelemetry Collector 以及 VictoriaMetrics 的 vmagent 构建的现代化开源指标系统。目前,新系统在生产环境中每秒可处理超过 1 亿条指标样本。
团队并未采用分阶段功能迁移的方式,而是选择了前置采集策略:先将所有指标接入新系统,再基于已有的真实数据对仪表盘、告警规则及用户工具进行适配改造。主要挑战在于需要同时协调三类并存的埋点体系:StatsD 客户端库、使用量持续增长的 OTLP 埋点,以及基于 Grafana Mimir 构建的新 Prometheus 兼容存储后端。
Airbnb 约有 40% 的服务使用平台统一维护的共享指标库。可观测性团队对该库进行了升级,使其支持指标双发:一边向旧管道发送 StatsD 数据,一边向新的 OpenTelemetry Collector 发送 OTLP 数据,从而在整个服务集群中以极低的改造成本实现了大规模迁移。
转向 OTLP 带来了可量化的收益:JVM 服务中用于指标处理的 CPU 时间从总 CPU 采样的 10% 降至 1% 以下。除性能提升外,OTLP 基于 TCP 传输,消除了 StatsD 使用 UDP 固有的丢包风险;同时该协议对 Prometheus 指数直方图的原生支持也省去了采集器内部的中间转换环节。不过,基数最高的一类服务(单实例每秒发送超 10000 个样本)在启用 OTLP 后出现了内存压力增大、GC 频繁的问题。团队通过 AggregationTemporalitySelector.deltaPreferred() 将这类服务切换为增量时间序列模式,避免了在导出间隔之间保存所有指标/标签组合的完整状态。为此他们接受了折中:意外故障会表现为可见的数据缺口,而非数据异常跳变。
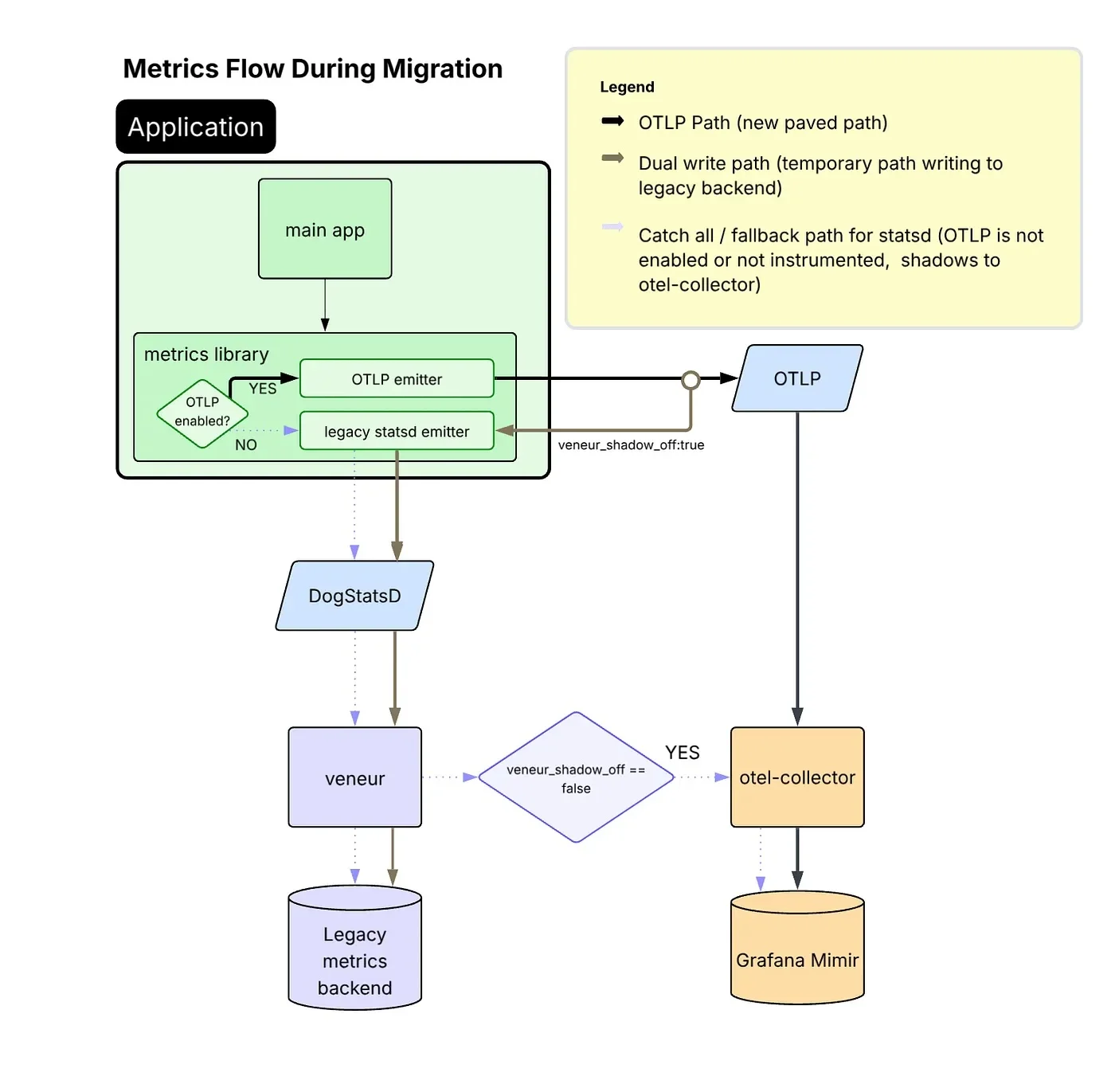
Airbnb 原有管道在将数据转发给指标服务商之前会通过 Veneur 的内部定制版本聚合剔除实例级标签(如 Pod 与主机名)。新的基于 Prometheus 的技术栈同样需要类似的聚合步骤来控制存储成本。
团队评估了多种替代方案:若继续使用 Veneur,则需要进行大量重构才能适配 Prometheus 数据模型;记录规则因需先将原始数据存入时序数据库再进行聚合,与降本目标冲突而被排除;OpenTelemetry Collector 虽已有相关公开提案,但暂未原生支持指标聚合;Vector 因缺少内置扩展能力,且 Airbnb 内部 Rust 技术栈使用较少,最终未被选用;m3aggregator 则被认为架构过于复杂。
最终,团队选择了 vmagent,原因在于它支持 Prometheus 指标流式聚合、支持水平分片、文档清晰易懂,同时代码库仅有约 10000 行,便于进行内部定制化改造。
生产架构采用两层 vmagent 部署:无状态路由 Pod 通过一致性哈希(排除需聚合的标签)对指标进行分片,有状态聚合器 Pod 在内存中维护累计数据。路由器配置了聚合器主机名的静态列表,借助 Kubernetes StatefulSet 稳定的网络标识,避免引入额外的服务发现依赖。该生产集群已扩展至数百个聚合器节点,多项通用优化改进也已回馈给 VictoriaMetrics 上游项目。
完成采集迁移后,团队发现部分计数器在使用 PromQL 查询时结果相比旧监控系统持续偏低。根本原因是 Prometheus 在低上报频率场景下处理计数器重置的边缘逻辑差异:在 StatsD 中,每个数据点均为对应刷新窗口内的增量值,而在 Prometheus 中,数据点为累计计数值,需通过 rate() 函数计算增量。如果某个计数器仅递增一次,且对应 Pod 在再次递增前就重启,该次增量就会在 rate() 计算有效增量前丢失。
在 Airbnb,这一边缘情况造成的影响远超预期。许多计数器用于跟踪高维度、低频率的事件,例如按货币、用户、区域维度划分的请求量,这类指标中任意一组标签组合每天可能仅递增数次。这些通常是关键业务指标,系统性漏报会阻碍用户侧的迁移。
团队排除了多种方案:预初始化所有计数器为零(在大规模且标签组合不可预测的场景下不切实际)、用仪表替代计数器(不符合 Prometheus 常规用法),以及让所有仪表盘与告警开发者自行适配 PromQL 变通写法。最终选定的方案是在 vmagent 聚合层内部实现透明的“零值注入”机制:当聚合计数器首次刷新时,聚合器先发送一个构造的零值,而非实际累计值;真实的累积数值会在后续刷新间隔中上报。这一做法隐式地将每个计数器初始化为零,使其符合 Prometheus 语义,同时延迟首次刷新也保证了构造零值的时间戳不会与已有样本冲突。相应的代价是首个记录增量的刷新间隔会出现一次延迟。
改造完成后的监控管道在单个生产集群中每秒可处理超过 1 亿条样本,与原有架构相比,成本降低了约一个数量级。集中式聚合层同时也成为了通用转换层:运维人员无需修改应用代码即可剔除因埋点配置不当产生的异常指标,或为调试需求临时对原始指标进行双发处理。
Flipkart 与 Shopify 从不同角度解决了相同的问题。Flipkart 的工程师需要应对来自约 2000 个 API 网关实例的 8000 万个并发时间序列,StatsD 已在高基数长查询压力下不堪重负,因此他们采用分层 Prometheus 联邦方案解决聚合问题:本地服务器通过记录规则剔除高基数实例标签,再通过 /federate 端点向上暴露汇总后的指标序列。Shopify 的动机主要源于成本控制:随着平台规模扩张,分别对接指标、日志、链路追踪三家独立供应商的成本变得极高。团队基于 Prometheus、Loki、Tempo 与 Grafana 重新构建了名为 Observe 的统一内部平台,并采用与 Airbnb 后续一致的双写模式,在正式切换前验证数据一致性。两篇文章均未像 Airbnb 那样深入剖析聚合的具体实现机制,或计数器语义正确性带来的潜在问题。但它们共同印证了一点:逐步弃用 StatsD、降低第三方服务商成本、向以 Prometheus 为核心的开源技术栈迁移,并非个例选择,而是超大规模工程组织的普遍趋势——只要传统推送式监控模型触及性能上限,这一路径就会反复出现。
【声明:本文由 InfoQ 翻译,未经许可禁止转载。】
查看英文原文:https://www.infoq.com/news/2026/04/airbnd-opentelemetry-vmagent/




