
仅仅在几年前,训练一个 AI 模型所需的时间还可能长达数周之久。
这也是过去几年间,计算行业间涌现了众多价值数十亿美元的创新初创公司的重要原因所在——这些公司包括了 Cerebras Systems、Graphcore、Habana Labs 和 SambaNova Systems 等等。此外,谷歌、英特尔、英伟达和其他老牌公司也在企业内部投入了规模相当的巨额资金(有时还会发起收购计划)来探索这一领域。最新版本的 MLPerf 训练基准结果表明,这笔钱是物有所值的。
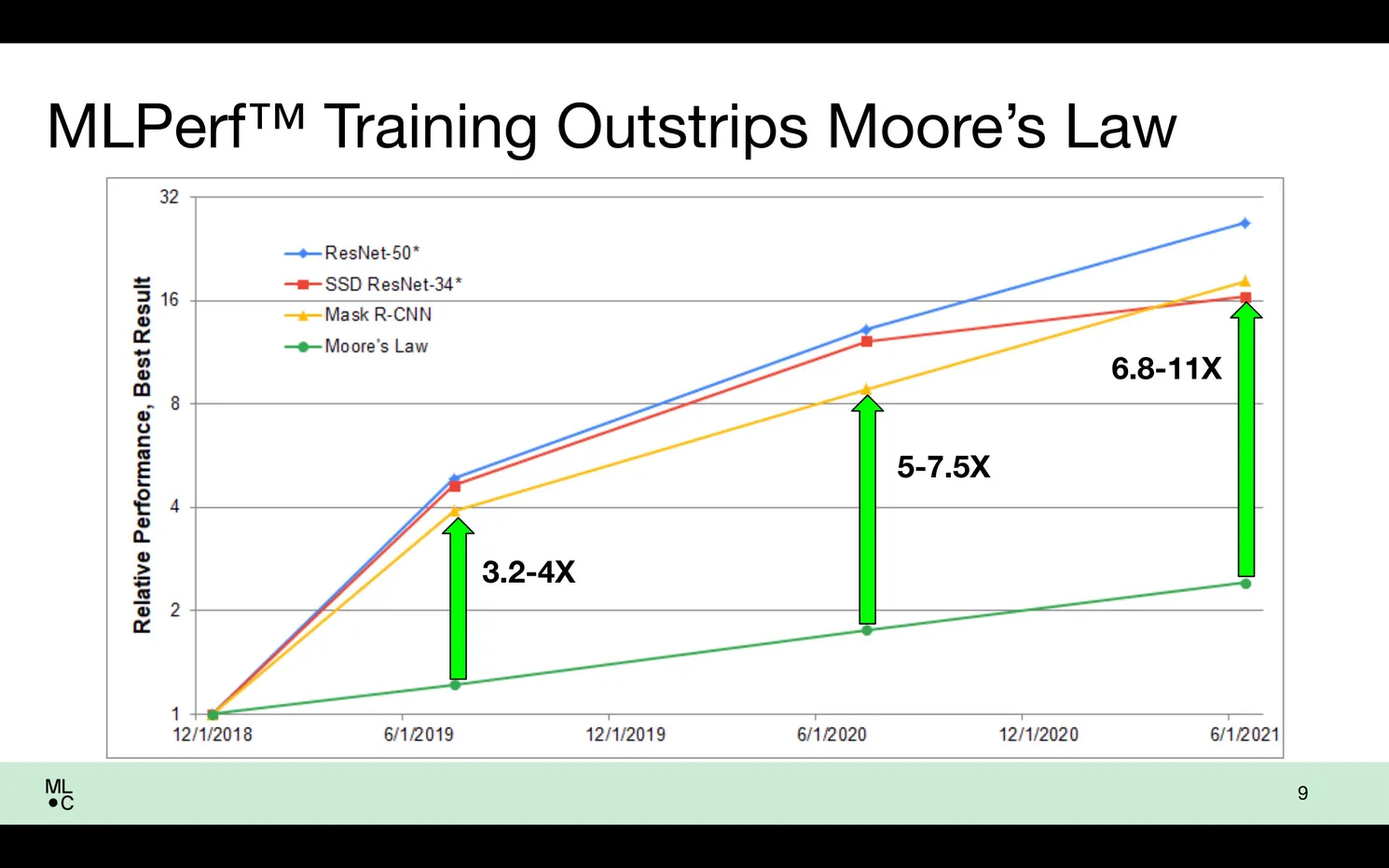
MLPerf 母公司 MLCommons 的执行董事 David Kanter 表示,自 MLPerf 基准测试开始上线以来,人工智能训练性能的提升速度“成功地大大超过了摩尔定律”。
在早期版本的 MLPerf 基准测试最佳结果与 2021 年 6 月之后的基准测试最佳结果之间,晶体管密度的增长可以解释其中一倍多的差异。但是软件以及处理器和计算机架构的改进则贡献了 6.8-11 倍的成绩增长。在最新的 1.1 版测试中,最佳结果是 6 月份最佳成绩的 2.3 倍。
根据英伟达的说法,使用 A100 GPU 的系统的性能相比 18 个月前的系统提高了 5 倍以上,相比三年前 MLPerf 基准测试成绩首次发布时的结果提高了 20 倍。
微软首次将其 Azure 云 AI 产品引入了 MLPerf,使用各种资源在所有八个测试网络中取得了极佳的成绩。它们的规模从 2 个 AMD Epyc CPU 和 8 个英伟达 A100 GPU,直到 512 个 CPU 和 2048 个 GPU 不等。规模显然很重要。顶级规格的系统在不到一分钟的时间内就训练完了 AI 模型,而二八组合通常需要 20 分钟或更长时间。
“摩尔定律只能做到这么多。软件和其他进步在 AI 训练的进化道路上发挥了重要作用。”
——MLCommons
英伟达在基准测试中与微软密切合作。并且就像之前的 MLPerf 列表中人们看到的一样,英伟达 GPU 是大多数参赛作品背后的 AI 加速器。包括戴尔、浪潮和 Supermicro 的作品都采用了他们的 GPU。
英伟达凭借其 Selene AI 超级计算机无与伦比的规模,在商用系统的所有结果中名列前茅。Selene 由商用的模块化 DGX SuperPod 系统组成。在最大规模的测试中,Selene 使用 1080 个 AMD Epyc CPU 和 4320 个 A100GPU 在不到 16 秒的时间内就训练完了自然语言处理器 BERT,大多数小型系统完成同样的壮举需要花费大约 20 分钟。
根据英伟达的说法,使用 A100 GPU 的系统的性能相比 18 个月前的行业水平提高了 5 倍以上,相比三年前首次 MLPerf 基准测试结果发布时提高了 20 倍。该公司表示,这要归功于软件创新和网络的改进成果。(有关更多信息,请参阅英伟达的博客)
鉴于英伟达在这些 AI 基准测试中的统治力和成绩表现,新生的竞争对手很自然地会将自身与它进行比较。这就是总部位于英国的 Graphcore 正在做的事情,它指出他们研发的基本计算单元 Pod16(1 个 CPU 和 16 个 IPU 加速器)比英伟达的基本单元 DGX A100(2 个 CPU 和 8 个 GPU)快了近一分钟。

Graphcore 推出了更大的系统
对于这一版本的 MLPerf,Graphcore 使用其基本单元 Pod64、Pod128 和(你肯定猜得到吧?)Pod256 的组合参加了图像分类和自然语言处理基准测试。Pod256 由 32 个 CPU 和 256 个 IPU 组成,是仅次于英伟达的 Selene 和英特尔的 Habana Gaudi 的第四快系统,以 3:48 完成了 ResNet 图像分类训练。在自然语言处理方面,Pod256 和 Pod128 在榜单上排名第三和第四,再次落后于 Selene,分别以 6:54 和 10:36 结束。(有关更多信息,请参阅 Graphcore 的博客)
你可能已经注意到了,基于英伟达的产品(大约 1 比 4)和 Graphcore 的系统(低至 1 比 32)对比,它们的 CPU 与加速器芯片的比率有很大不同。Graphcore 工程师说,这是设计理念使然。IPU 旨在让神经网络减少对 CPU 控制的依赖。
你会在 Habana Labs 系统上看到相反的情况,英特尔在 2019 年以大约 20 亿美元的价格收购了它。例如,它在图像分类方面取得了很高的排名,为此英特尔使用 64 个 Xeon CPU 和 128 个 Habana Gaudi 加速器在不到 5 分半的时间内训练完了 ResNet。它还使用 32 个 CPU 和 64 个加速器,用时 11 分 52 秒训练完了 BERT 自然语言神经网络。(更多信息请参阅 Habana 的博客 )
谷歌对这批基准分数的贡献有点不一样。谷歌工程师没有使用该公司的 TPU v4 处理器技术搭载在商业或云系统上完成测试,而是提交了两个超大自然语言处理神经网络的结果。
该公司使用其公开可用的 TPU v4 云运行了一个版本的 Lingvo,这是一种 NLP,其参数高达 4800 亿,而 BERT 的参数为 1.1 亿。云平台使用 1024 个 AMD Epyc CPU 和 2048 个 TPU,在不到 20 小时的时间内完成了训练任务。使用由 512 个 AMD Rome CPU 和 1024 个 TPU 组成的研究系统,谷歌在 13.5 小时内训练了一个 2000 亿参数版本的 Lingvo。(谷歌报告称,从头到尾完成整个过程需要 55 小时和 44 小时,包括开始训练所需的步骤。)
在结构上,Lingvo 与 BERT 非常相似,可以归入该类别,但它也类似于众多计算巨头一直在研究的其他真正巨型的对话 AI,例如 LaMDA 和 GPT-3。谷歌认为,巨大模型训练最终应该成为未来 MLPerf 商业基准测试的一部分。(有关更多信息,请参阅谷歌的博客。)
然而,MLCommons 的 Kanter 指出,训练此类系统的费用高到了足以将许多参与者排除在外。




