
整理|华卫
GPT-5.2 来了。
一共三个版本:
GPT-5.2 Instant 是一款高效实用的日常工作与学习工具,在信息检索问答、操作指引、技术文档撰写及翻译等方面均有显著优化,同时延续了 GPT-5.1 Instant 亲切自然的对话风格。
GPT-5.2 Thinking 专为深度工作场景打造,可助力用户更优质地完成复杂任务,尤其适用于编程开发、长篇文档总结、上传文件问答、数学逻辑分步推演,以及输出结构清晰、细节详实的规划与决策支持内容。
GPT-5.2 Pro 是 OpenAI 针对高难度问题推出的最智能、最可靠的选择,为获取更高质量的答案,所需等待时间会相应增加。
OpenAI 称,这是迄今为止功能最强大的专业知识工作模型系列。在涵盖 44 个职业、任务定义明确的知识型工作中,它的表现超越了行业专业人士。
总体而言,GPT-5.2 在通用智能、长上下文理解、智能体工具调用及视觉能力方面实现了大幅升级,相较以往任何一款模型,它在端到端执行复杂的现实任务时表现更为出色。在制作电子表格、搭建演示文稿、编写代码、图像识别、长文本理解、工具调用以及处理复杂多步骤项目等方面,该模型的能力均有提升。
“这是一个非常智能的模型,自 GPT-5.1 以来,我们已经取得了长足的进步。”OpenAI 的 CEO Sam Altman 在社交平台激动地表示。微软 CEO Satya Nadella 亲自祝贺,并表示“GPT-5.2 已上线到 Copilot”,还引入到 Microsoft Foundry 和 Copilot Studio。
今日起,GPT-5.2 的即时版、思考版与专业版将在 ChatGPT 平台中启动推送,优先面向付费套餐用户开放。在编程接口端,上述版本现已向所有开发者开放。GPT-5.1 将作为旧版模型,继续向付费用户开放三个月,之后便会正式下线。
能顶 11 个专业人士,经济性拉满
“我们打造 GPT-5.2 的初衷,是为人们释放更大的经济价值。”OpenAI 强调,GPT-5.2 Thinking 是迄今为止最适合实际专业应用的模型,也是其首款性能达到或超越人类专家水平的模型。
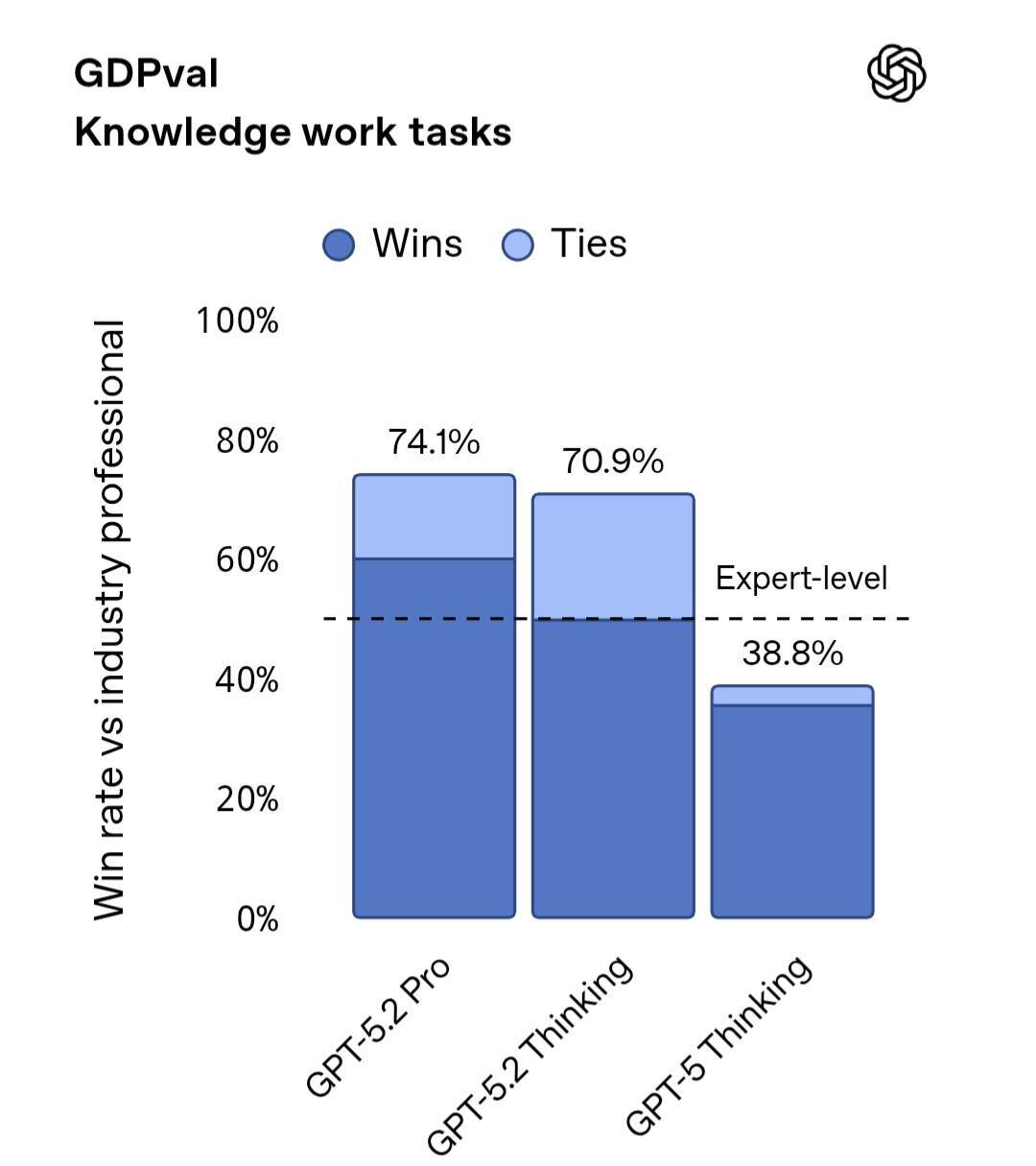
在覆盖 44 个职业的特定知识工作任务的 GDPval 评测中,GPT-5.2 Thinking 创下了新的最高分。同时根据人类专家评审结果,在 GDPval 知识型工作任务的对比测试中,GPT-5.2 Thinking 在 70.9%的项目上表现优于或与顶尖行业专业人士持平。这些任务涵盖制作演示文稿、电子表格及其他工作成果。
完成 GDPval 相关任务时,GPT-5.2 Thinking 的产出速度是专业人士的 11 倍以上,成本却不足其 1%,这意味着在人工监督配合下,GPT-5.2 能够为专业工作提供助力。
一位 GDPval 评测人员评价道:“产出质量实现了令人振奋且有目共睹的飞跃,看上去就像是由一家配备专业人员的公司完成的,两份交付成果的版式设计与建议都出人意料地精良,不过其中一份仍存在几处需要修正的小错误。”
此外,在 OpenAI 针对初级投行分析师的电子表格建模任务的内部基准测试中,GPT-5.2 Thinking 的单任务平均得分较 GPT-5.1 提升了 9.3%,从 59.1%攀升至 68.4%。对比结果显示,GPT-5.2 Thinking 生成的电子表格与幻灯片,在复杂程度与格式规范性上均有显著提升。
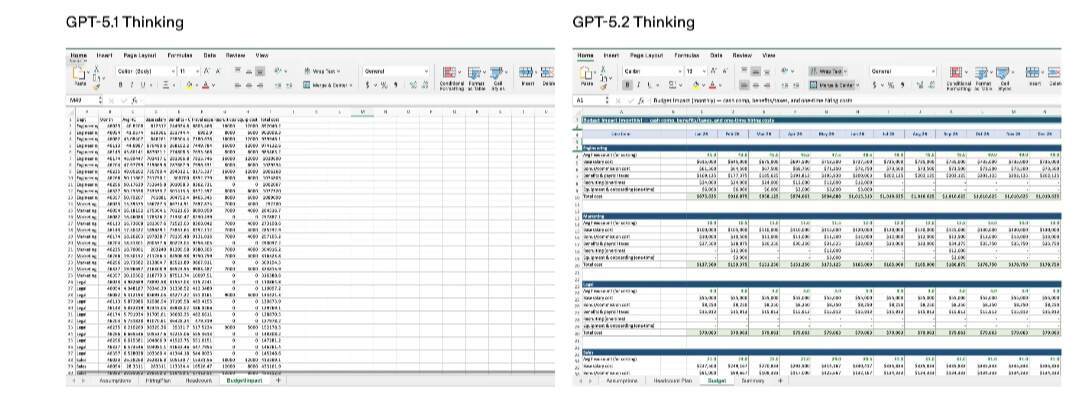
需注意的是,对于复杂内容的生成过程,GPT-5.2 Thinking 可能需要数分钟时间。并且,要在 ChatGPT 中使用全新的电子表格与演示文稿生成功能,须订阅 Plus、Pro、商业版或企业版套餐,并选择 GPT-5.2 Thinking 或 Pro 版。
“GPT-5.2 Thinking 是我们迄今为止性能最强的多模态视觉模型,将图表推理与软件界面理解任务的错误率降低了约一半。”据介绍,相较于前代模型,GPT-5.2 Thinking 对图像中各类元素的位置关系具备更强的感知能力,使其在相对布局对任务求解起关键作用的场景中表现更优。
在日常专业工作场景中,这意味着该模型能更精准地解读数据仪表盘、产品截图、技术原理图与可视化报告,为金融、运营、工程、设计及客户支持等以视觉信息为核心的工作流提供有力支撑。
另值得一提的是,GPT-5.2 Thinking 是 OpenAI 目前观测到的首款在 4-needle MRCR 变体测试(词元上限达 25.6 万)中实现近乎 100% 准确率的模型。在深度文档分析这类需要调取数十万词元跨度关联信息的现实任务中,GPT-5.2 Thinking 的准确率远超 GPT-5.1 Thinking。
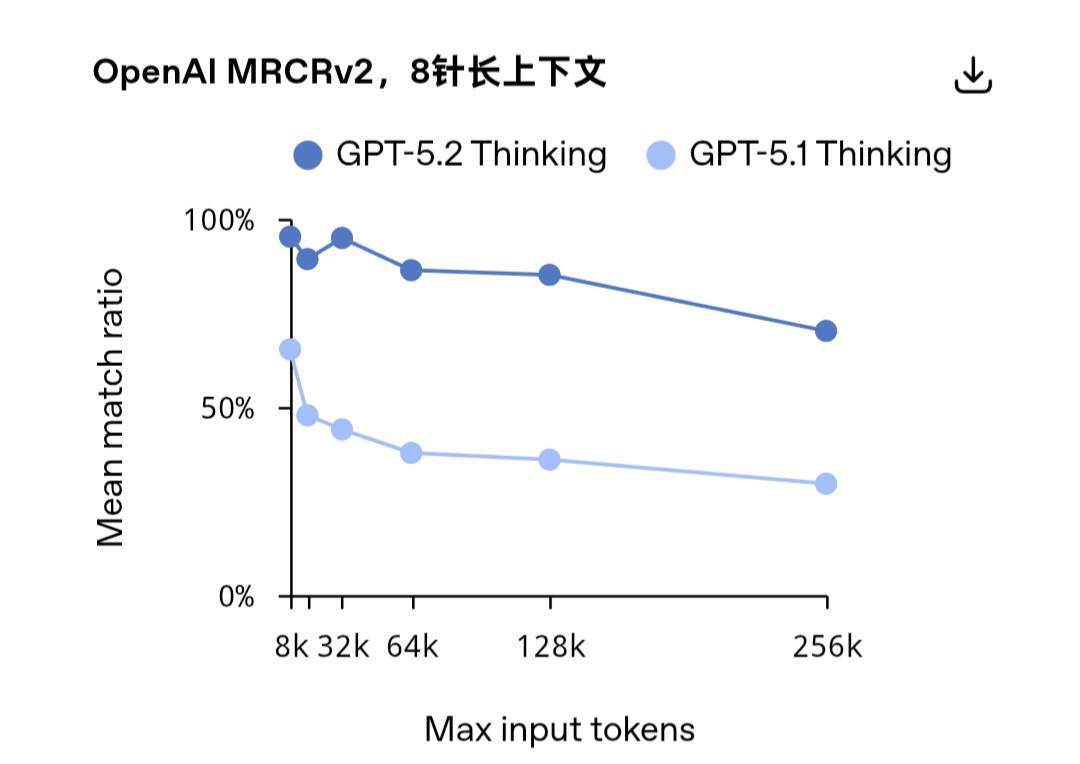
从实际应用角度来看,这一能力让专业人士可以借助 GPT-5.2 高效处理报告、合同、研究论文、会议记录以及多文件项目等长篇文档,同时在数十万词元的内容跨度下保持逻辑连贯与结果准确。这也让 GPT-5.2 特别适用于深度分析、信息整合以及复杂的多来源工作流场景。
在 Tau2-bench Telecom 基准测试中,GPT-5.2 Thinking 取得 98.7% 的成绩,充分展现了其在冗长多轮任务中稳定调用工具的能力。针对对延迟敏感的使用场景,GPT-5.2 Thinking 在零推理消耗模式下的表现同样大幅提升,性能显著优于 GPT-5.1 与 GPT-4.1。
对于专业人士而言,这意味着端到端工作流的效率与稳定性得到增强,比如处理客户支持工单、从多个系统调取数据、开展分析并生成最终成果,整个流程的步骤中断率更低。举例来说,当用户提出需要多步骤解决的复杂客服问题时,该模型能够更高效地协调多智能体完成全流程工作。
编程能力更抗打了,但产出“龟速”?
在 SWE-Bench Pro 基准测试中,GPT-5.2 Thinking 创下了 55.6%的成绩,该测试是针对现实场景软件工程能力的严苛评估。与仅支持 Python 语言测试的 SWE-Bench Verified 不同,SWE-Bench Pro 涵盖四种编程语言,且在抗数据污染性、任务挑战性、题型多样性以及行业实用性上均有显著提升。
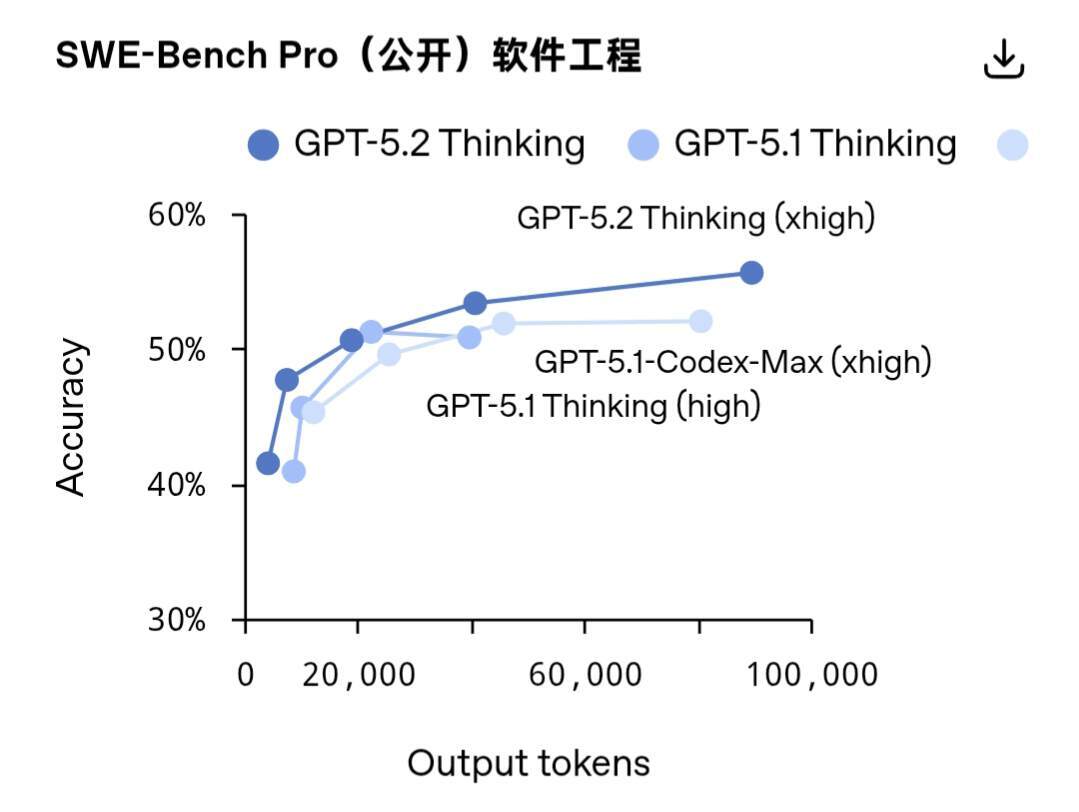
在 SWE-bench Verified 基准测试中,GPT-5.2 Thinking 取得了 80% 的全新高分。对于日常专业工作而言,这意味着 GPT-5.2 Thinking 能更稳定地调试生产环境代码、实现功能需求、重构大型代码库,并且无需大量人工干预即可端到端地完成漏洞修复并上线。
前端软件工程方面,GPT-5.2 Thinking 的表现也优于 GPT-5.1 Thinking。早期测试者发现,它在前端开发以及复杂或非标界面开发工作中表现显著更出色,尤其是涉及 3D 元素的开发场景,这使其成为全栈工程师(Full Stack Engineer)高效的日常协作工具。以下为 GPT-5.2 Thinking 仅通过单条指令即可生成的部分成果示例:
Windsurf 公司首席执行官 Jeff Wang 评价道,“GPT-5.2 代表了自 GPT-5 以来 GPT 模型在智能编码方面最大的飞跃,也是同价位产品中最先进的编码模型。版本号的提升远不足以体现其智能水平的飞跃。”据透露,GPT-5.2 Thinking 已经是 Windsurf 和多个 Devin 核心工作负载的默认版本。
Cognition、Warp、Charlie Labs、JetBrains 以及 Augment Code 表示,GPT-5.2 实现了业界顶尖的智能体编程性能,在交互式编程、代码审查及漏洞排查等领域均取得了可量化的提升。
当前,已有早期测试者分享了他们对 GPT-5.2 编码能力的反馈。HyperWriteAI 的 CEO Matt Shumer 从 11 月 25 日开始使用 GPT-5.2,经过两周在编程、研究、创意写作和日常任务等方面的全面测试,他给出了如下评价:
GPT-5.2 Thinking 在指令遵循能力与攻坚意愿上实现了实质性的进步。
其代码生成能力较 GPT-5.1 有大幅提升,不仅功能更强、自主性更高、逻辑更严谨,还能编写体量更大的代码。
视觉与长上下文处理能力也得到显著优化,在图像元素位置识别以及大型代码库处理方面的表现尤为突出。
速度问题是它的主要短板,思考模式应对大部分问题时速度都很慢。
GPT-5.2 Pro 在深度推理方面的表现堪称惊艳,但运行速度偏慢,偶尔还会陷入持续运算却最终无法得出结果的情况。
在 Codex 命令行界面中,GPT-5.2 的编程表现是其用过的最接近专业版水准的,但开启能实现该性能的超高推理模式后,耗时会十分漫长。
自评“最优科研模型”,幻觉减少 30%?
“GPT-5.2 Pro 与 GPT-5.2 Thinking 是目前全球范围内助力和加速科研工作的最优模型。”OpenAI 称。
在研究生级别的谷歌检索验证问答基准测试 GPQA Diamond 中,GPT-5.2 Pro 取得了 93.2% 的成绩,紧随其后的 GPT-5.2 Thinking 也达到了 92.4%。在专家级数学评测基准 FrontierMath(1–3 级) 中,GPT-5.2 Thinking 成功解答了 40.3% 的题目。
据介绍,在近期一项借助 GPT-5.2 Pro 开展的研究工作中,科研人员探究了统计学习理论领域的一个开放性问题。在设定明确的限定场景下,该模型提出了一个证明过程,后续经研究作者验证及外部专家评审确认有效。
在用于衡量通用推理能力的基准测试 ARC-AGI-1(验证版) 中,GPT-5.2 Pro 成为首个突破 90%得分门槛的模型,相较去年 o3-preview 版本 87%的成绩实现提升,同时将达成该性能的成本降低了约 390 倍。
在难度更高、更能精准评估流体推理能力的 ARC-AGI-2(验证版) 中,GPT-5.2 Thinking 为思维链模型取得 52.9%的得分。GPT-5.2 Pro 的表现则更为出色,得分高达 54.2%,进一步拓展了模型在全新抽象问题上的推理能力。
Triple Whale 首席执行官 AJ Orbach 评价道,“GPT-5.2 带来了架构上的彻底变革,将一个脆弱的多智能体系统简化为一个拥有 20 多个工具的超级智能体。这个超级智能体速度更快、更智能,维护起来也轻松了 100 倍。延迟显著降低,工具调用更加强大,而且不再需要冗长的系统提示符,因为 5.2 版本只需一行简单的提示符即可干净利落地执行。这简直太神奇了。”
值得注意的是,GPT-5.2 Thinking 的幻觉现象较 GPT-5.1 Thinking 有所减少。在一组来自 ChatGPT 的匿名查询中,含错误的回复相对减少了 30%。对于专业人士而言,这意味着在利用该模型开展研究、写作、分析及决策支持工作时,出错概率更低,使其在日常知识型工作中更具可靠性。
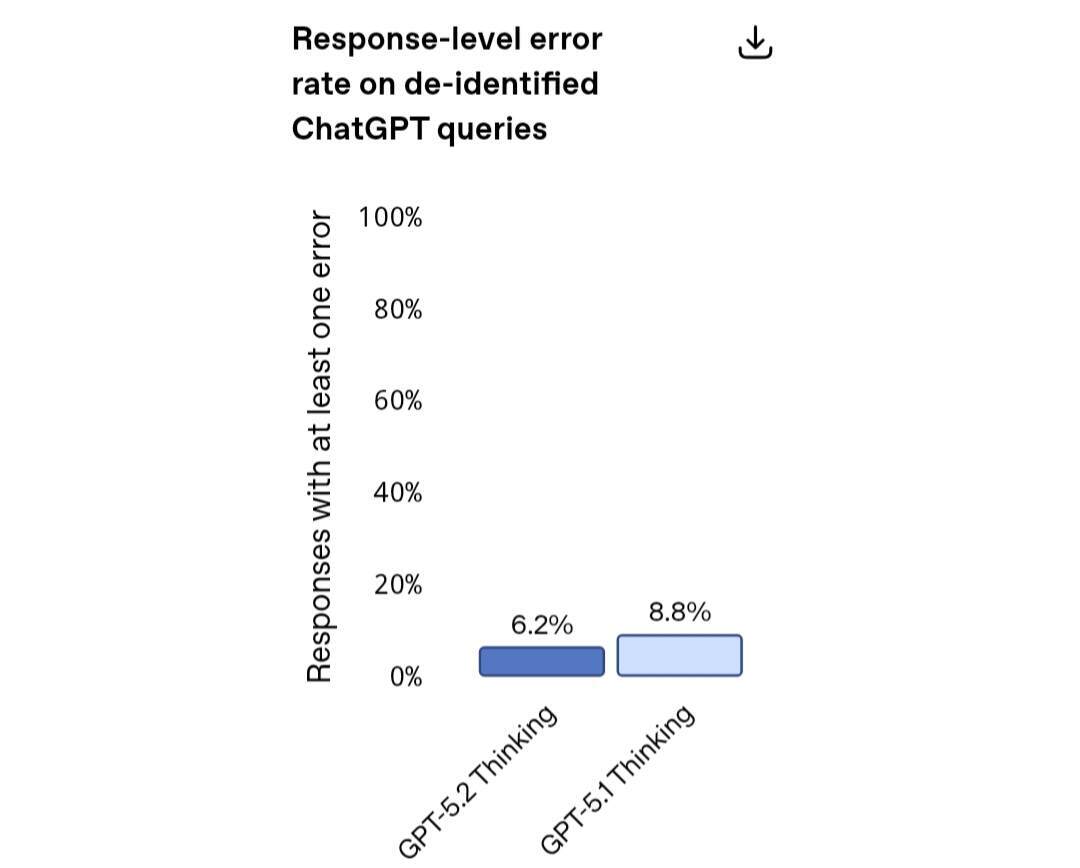
不过,OpenAI 依然强调,“与所有模型一样,GPT-5.2 Thinking 并非完美无缺。对于任何关键事务,请务必核实其给出的答案。”
价格方面,接入 GPT-5.2 后,ChatGPT 的订阅定价保持不变,而在 API 端,由于 GPT-5.2 的性能更为强大,其单词元定价高于 GPT-5.1。GPT-5.2 的定价为:每百万输入词元 1.75 美元,每百万输出词元 14 美元,缓存输入内容可享 90%的折扣优惠。

未来几周内,OpenAI 预计将再推出一款针对 Codex 优化的 GPT-5.2 版本。目前,GPT-5.2 在 Codex 平台中也可直接投入使用。
参考链接:




