
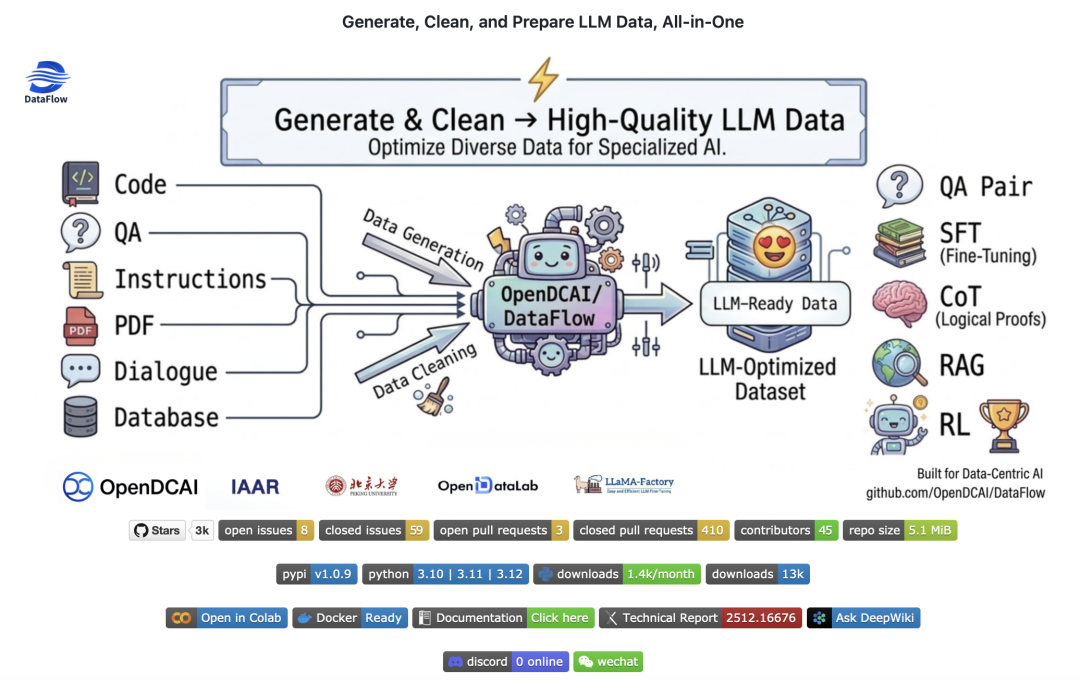
在大模型(LLM)研发进入深水区的 2026 年,行业共识正经历从“模型中心(Model-Centric)”向“数据中心(Data-Centric)”的深刻演进。随着 Scaling Law 进入平台期,开发者发现:单纯堆砌 Token 数量已边际效应递减,数据的语义密度(Semantic Density)与工程精度成为了突破模型性能上限的关键。
然而,在研发 DataFlow 的过程中,北京大学 DCAI 团队观察到一个严峻的现实:虽然模型已进入自动驾驶时代,但数据准备(Data Prep)仍处于“手工坊”阶段。碎片化的 Python 脚本、不可复用的正则表达式、缺乏观测性的黑盒流程,已成为大模型落地企业级应用的最大瓶颈。
正是基于对这一工程痛点的精准切入,DataFlow 的技术报告在发布后迅速引发了全球开发者的广泛共鸣,并成功登顶 Hugging Face Daily Papers 榜首(#1 of the Day)。这一来自开源社区的强烈反馈印证了一个事实:大模型行业急需一套具备系统化抽象与工业级可靠性的数据治理基础设施。
项目仓库:https://github.com/OpenDCAI/DataFlow
企业级 LLM 数据工程的三大技术挑战
在讨论工具能力之前,我们需要明确大模型数据工程与传统 ETL 的本质区别:
语义断层与模型在环(Model-in-the-Loop): 传统清洗依赖确定性规则,但 LLM 需要处理的是高维语义信息。要生成高质量的数学推理或复杂代码数据,必须引入模型来评估、过滤甚至生成数据,这要求系统具备极强的模型调用编排能力。
工程碎片化导致的“技术债”: 数据处理链路长、环节多,缺乏统一的抽象。不同项目间的算子难以复用,导致逻辑散落在各个独立脚本中,极大地提高了复现成本和维护难度。
黑盒处理与观测性缺失: 动辄 TB 级的文本在流水线中流转,开发者往往无法实时感知数据分布的变化。如果清洗逻辑存在隐性偏见,往往要等到模型训练数周后才能被发现,试错成本极高。
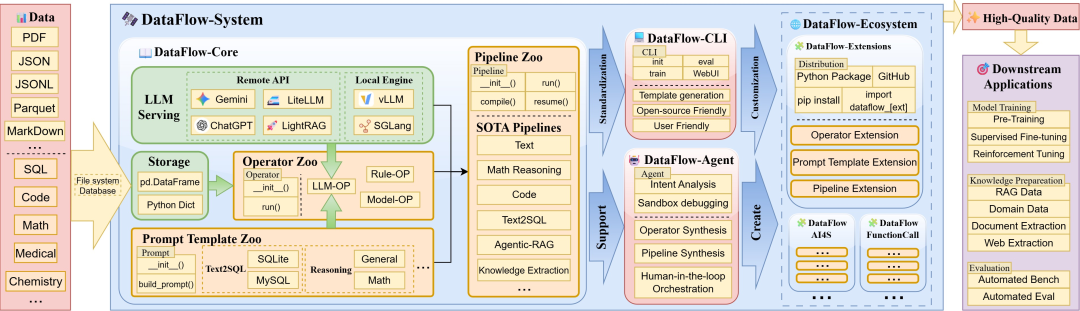
DataFlow 架构:像编写 PyTorch 模型一样定义数据流
DataFlow 的设计哲学是“系统化抽象,编程化驱动”。它不仅仅是一个库,而是一套类似于 PyTorch 的数据编程协议。
可观测性革命:DataFlow-WebUI
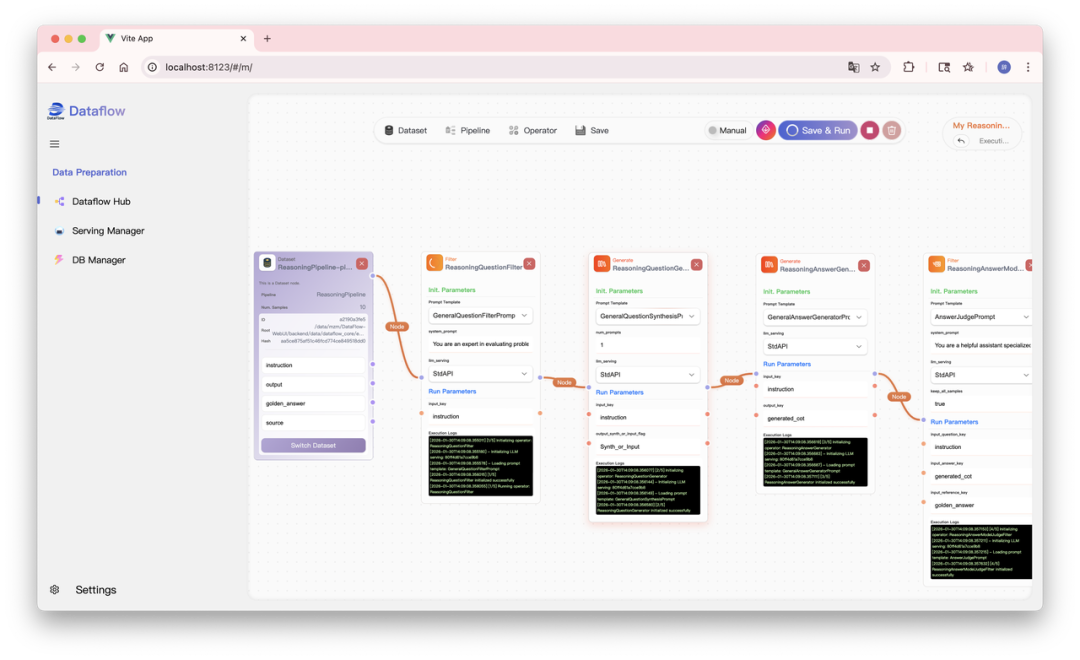
针对“黑盒清洗”的痛点,我们正式推出了 DataFlow-WebUI。它将复杂的算子库包装进图形化界面,支持:
拖拉拽编排:通过可视化画布定义数据流向,逻辑链路一目了然。
实时数据探针:支持在线预览算子输出的中间结果,开发者可以即时调整 Prompt 或过滤策略,实现数据治理的“白盒化”。
任务热监控:实时更新处理进度与运行日志,让长周期任务处于完全可控状态。
存储与服务层的解耦设计
DataFlow 引入了全局表格化存储(Global Storage)抽象。通过统一的 read() 和 write() 接口,将算子逻辑与底层存储格式解耦,每个算子基于统一 run(storage) 接口,通过 键绑定(key-based I/O)灵活适配任意数据格式。无论后端是本地 JSONL、Parquet 还是分布式数据库,算子只需关注字段操作。

同时,DataFlow 构建了统一 LLM 服务接口(Serving Interface),兼容 vLLM、SGLang 等本地推理引擎及 GPT-4 等在线 API。系统自动处理批处理(Batching)、重试及限速逻辑,使开发者能专注于 Prompt 策略而非后端工程细节。
模块化算子生态
DataFlow 将近 200 个内置算子严格划分为四类,建立了标准化的语义命名规范:

算子被设计为具备独立生命周期的原子转换单元。 在初始化阶段,算子通过声明式配置完成 LLM 服务实例与提示模板的依赖注入;在执行阶段,则通过 input_* / output_ 键名与全局存储层进行非侵入式交互。这种设计实现了计算逻辑与数据 Schema 的深度解耦,在确保状态隔离的同时,大幅提升了复杂 Pipeline 的组合灵活性与复用性。
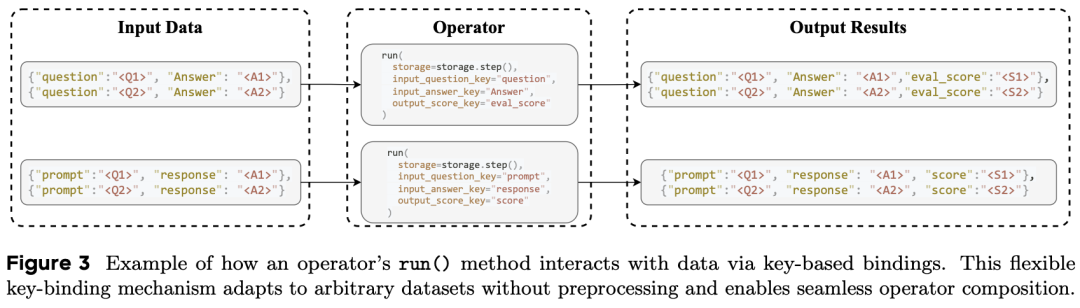
确定性流水线与静态检查
DataFlow 支持将算子组织为有序程序或 DAG。通过 compile() 机制,系统在任务运行前会对字段缺失、类型冲突进行静态检查和。配合延迟执行(Lazy Execution)和断点续传(Checkpoints),极大地提升了大规模分布式任务的可靠性。

DataFlow-Agent:从自然语言到可执行流水线的自动编排
为了解决“专家经验碎片化”的问题,DataFlow 引入了 Agentic 编排机制。用户只需输入自然语言指令(如“帮我生成高质量 Python 算法题数据”),Agent 即可完成:拆解意图 → 检索 / 合成算子 → 组装 DAG → 沙箱验证 → 输出可执行 pipeline。
这标志着 agent 首次通过“检索 - 复用 - 合成 - 验证”闭环,远超传统仅参数化配置的 agent,同时数据工程从“代码编写”向“逻辑定义”跃迁,显著降低了构建 SOTA 级领域流水线的门槛。
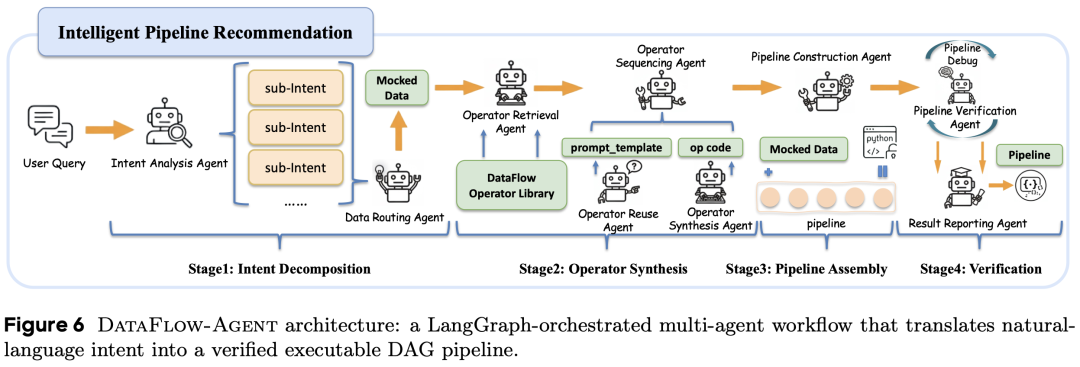
性能验证:小规模高质量数据的“杠杆效应”
为了验证 DataFlow 的系统化治理能力,我们在多个领域构建了 SOTA 级流水线。实验结果表明,通过精准的算子编排,能够以极小的数据规模实现模型性能的跨越式提升。
文本预训练与 SFT
在基础文本治理上,DataFlow 证明了语义提纯优于单纯的规模堆砌:
预训练阶段:DataFlow-30B 在 6 个通用基准上的均分为 35.69,优于 FineWeb-Edu(35.57)和 Qurating(35.02)。
指令微调 (SFT):使用 15K 高质量合成样本,模型在数学上的得分(49.3)显著高于经过过滤的 Alpaca(39.8)和 WizardLM(44.8)。
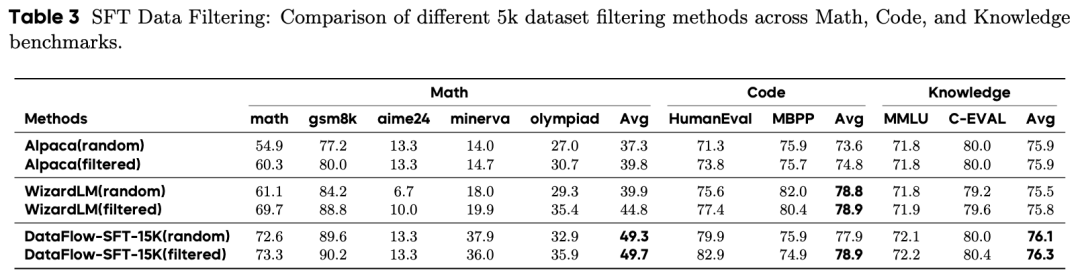
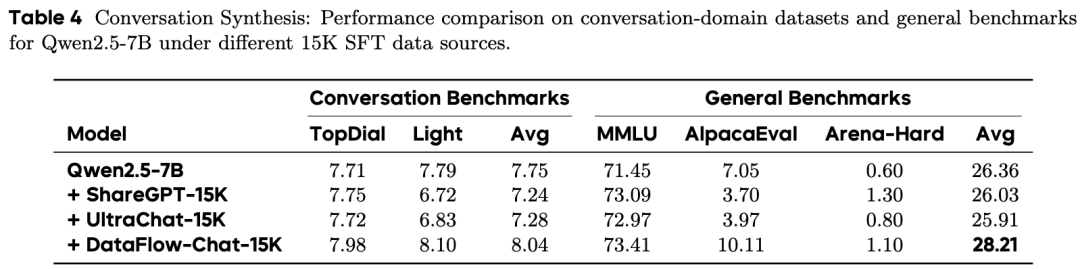
对话合成:DataFlow-Chat-15K 将 AlpacaEval 评分从 7.05 提升至 10.11,超越 ShareGPT 和 UltraChat。
数学与代码推理
在逻辑密集型任务中,DataFlow 的算子闭环展现了强大的逻辑构建能力:
数学推理:使用 DataFlow-Reasoning-10K 微调后,Qwen2.5-32B 在 8 个数学基准上平均得分为 55.7,超越了 Open-R1(54.2)和 Synthetic-1(54.0)。
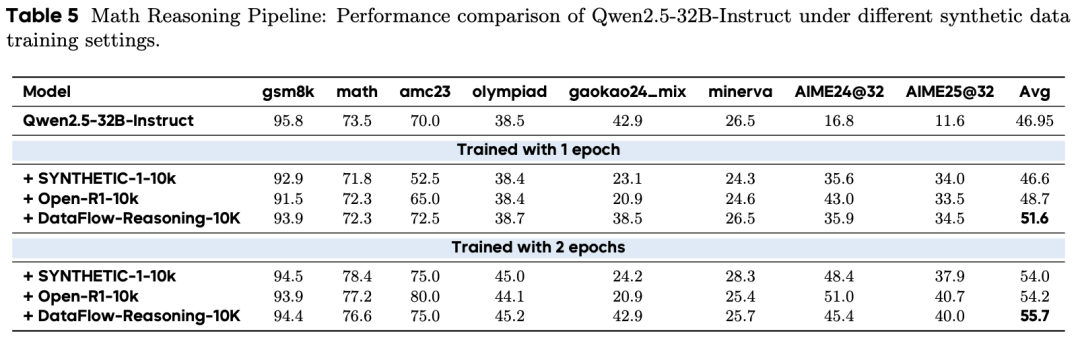
代码生成:
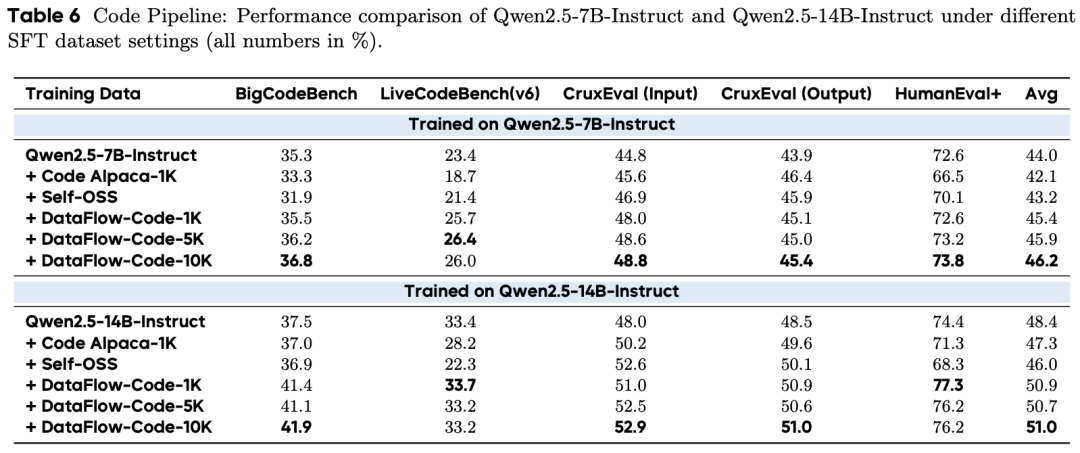
7B 模型:DataFlow-Code-10K 平均得分 46.2,优于 Code Alpaca-1K 和 SC2-Exec-Filter-1K。
14B 模型:DataFlow-Code-10K 平均得分 51.0,LiveCodeBench 从 21.9(Code Alpaca)提升至 33.2。
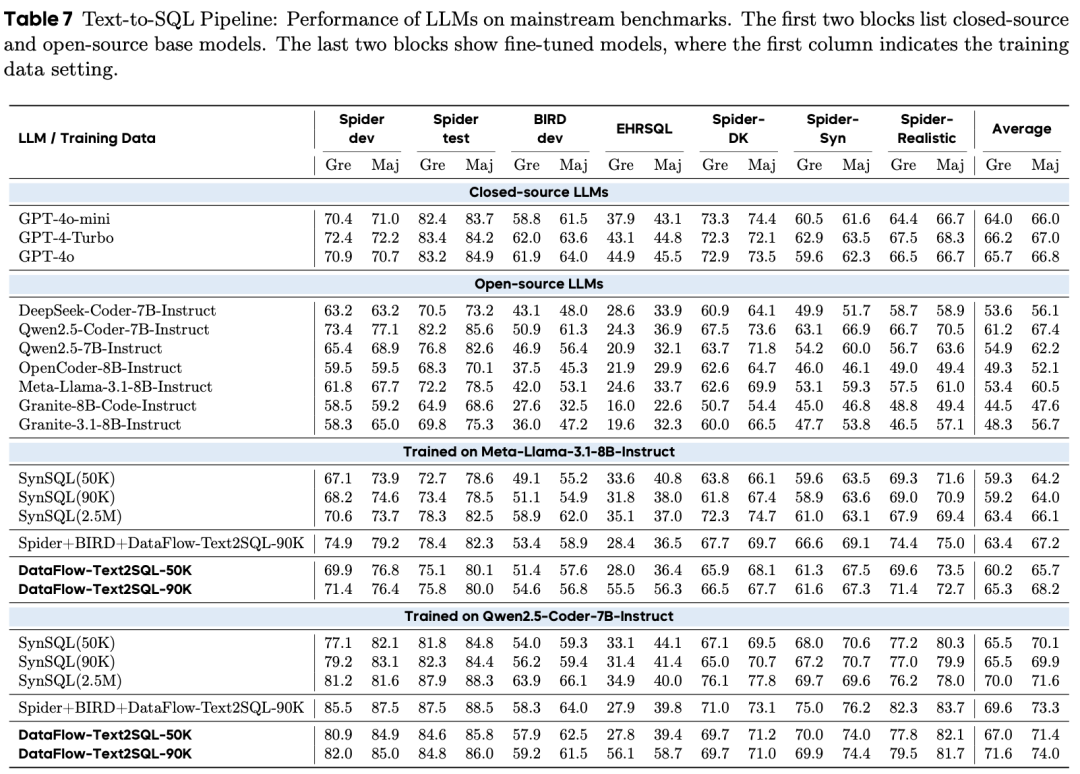
Text-to-SQL
在 Text-to-SQL 任务中,DataFlow 验证了高语义密度合成数据在特定工程场景下的极致上限。以 Qwen2.5-Coder-7B 为基座,通过在 DataFlow-Text2SQL-90K 数据集训练,模型在核心基准上均实现了跨越式增长:
核心性能跃升:Spider-dev 执行准确率从 73.4% 提升至 82.0%(+8.6%);BIRD-dev 从 50.9% 提升至 59.2%(+8.3%),在 EHRSQL 基准上,准确率由 24.3% 飙升至 56.1%,涨幅高达 31.8%。
数据经济性验证:实验结果显示,DataFlow-50K 的表现已优于同规模的 SynSQL;而 DataFlow-90K 的微调收益已逼近 SynSQL-2.5M。
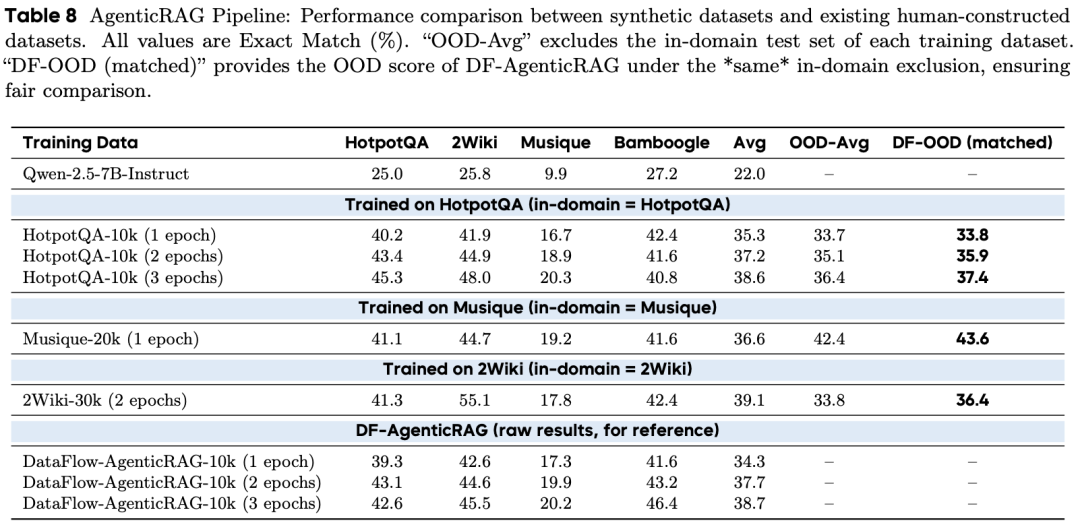
Agentic RAG
在分布外(OOD)评估中,DataFlow 产出的 DF-AgenticRAG-10k 具备更强的鲁棒性:
超过 HotpotQA-10k(37.4 vs. 36.4)
超过 Musique-20k(43.6 vs. 42.4)
知识抽取(医学 QA)
模型在 DataFlow-Knowledge 上 sft 后,PubMedQA 和 Covert 性能提升了 15–20 个百分点,PubHealth 提升 11 个百分点,显著优于传统的 Zero-shot CoT 方案。

统一多领域微调
我们验证了“小规模、高质量、领域特化”数据的核心假设:
使用仅 10K 的多领域合成样本(DataFlow-Instruct-10K),模型在数学和代码领域的表现已接近官方 Instruct 版本,且通用知识能力(MMLU)未出现退化,证明了高质量合成数据对大规模指令数据的替代潜力。
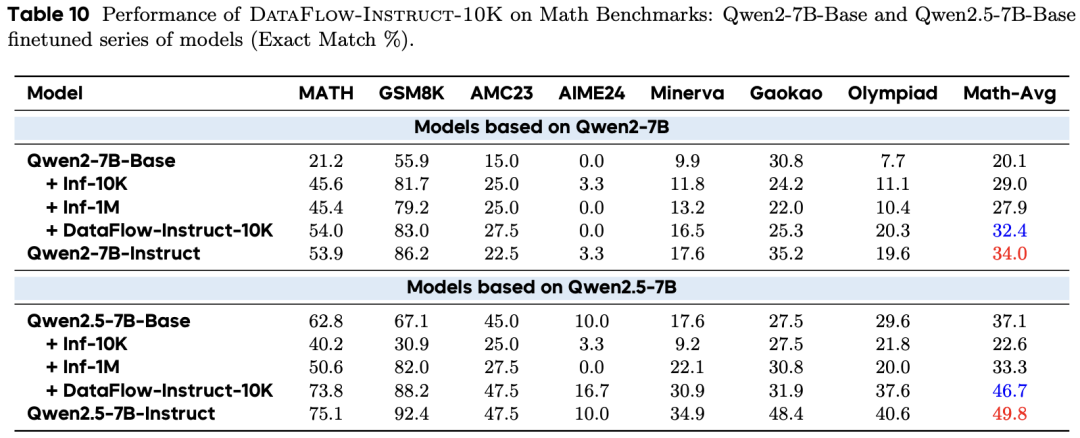
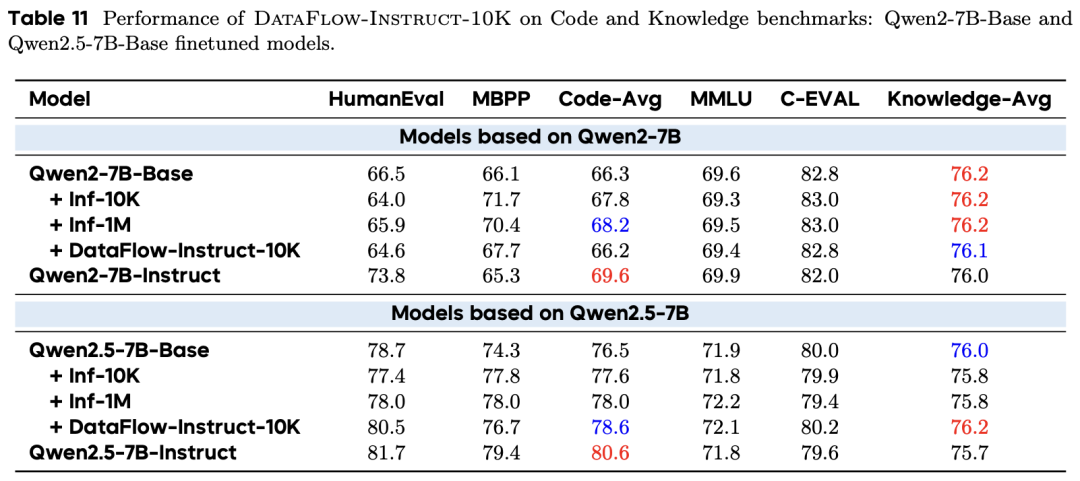
Agent 自动化性能实测
在文本规范对齐(Pipeline-level)评估中获得 0.80 的高分。
在代码实现一致性(code-level)评估中,平均得分 0.49。
在复杂代码实现(Hard 级任务)上,一致性得分仅为 0.23,这揭示了自动化治理在处理极端模糊描述时仍有技术迭代空间。
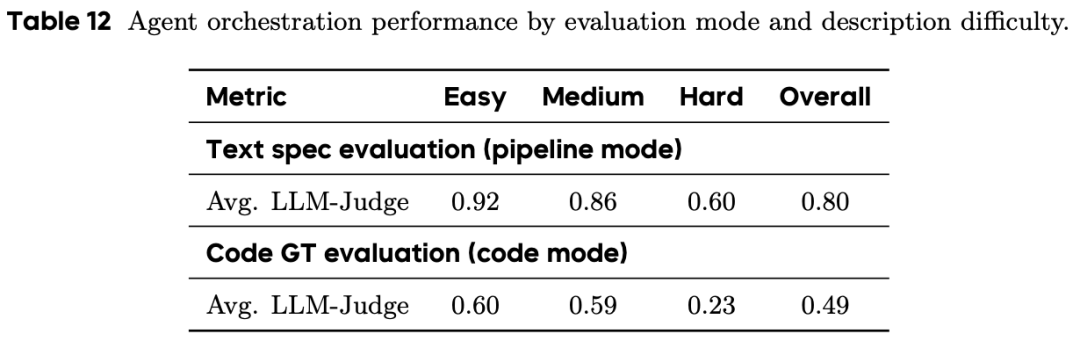
结语:迈向 Data-Centric AI 的开源生态
AI 研发的职能正在发生转型:开发者的核心工作将从“代码逻辑实现”转向“数据价值发现”与“质量红线把控”。DataFlow 团队希望通过这套开源框架,将 DCAI 的工程经验沉淀为可复用的算子与流水线协议。
目前,DataFlow 及其自动化 Agent 框架已在 GitHub 开源。我们欢迎社区开发者参与贡献,共同探索数据驱动的无限可能。
关于作者:
北京大学 DCAI 团队,专注于大模型数据系统研究与 Data-Centric AI 基础设施建设。
开源项目地址:
DataFlow (3k+ Stars): https://github.com/OpenDCAI/DataFlow
DataFlow 图文教程:https://wcny4qa9krto.feishu.cn/wiki/I9tbw2qnBi0lEakmmAGclTysnFd
DataFlow 视频教程:https://b23.tv/it5sssq
DataFlow-WebUI 用户文档(中文):https://wcny4qa9krto.feishu.cn/wiki/F4PDw76uDiOG42k76gGc6FaBnod




