
飞机上遇到的问题
在最近的一次飞行途中,我购买了机上联网服务并尝试使用 Claude Code。这个智能体需要读取多个文件、理解代码库结构、执行代码编辑并运行测试,属于典型的智能体工作流,单个流程涉及 10 至 15 次工具调用。但由于网络状况很差,到第三四轮交互时,请求就开始出现超时。每一轮交互都会重新发送完整的对话历史——包括最初的提示词、读取过的所有文件内容、提出的每一处修改以及每次测试的输出结果,数据量已膨胀至数百 KB。在带宽有限的网络环境下,这种不断增大的传输负载成了瓶颈。
这次经历凸显了一个愈发重要的问题:随着 AI 编程智能体的成熟,传输层对智能体工作流的重要性远高于简单的对话场景。单纯的聊天只需单轮发送提示词并获取响应,而编程智能体会话会涉及 10 轮、20 轮甚至 50 轮以上的连续交互,模型在这个过程中读取代码、提出修改、运行测试、查看报错、修复问题并持续迭代。每一轮对话上下文都会不断膨胀,而在 HTTP 协议下,整个持续增大的上下文每次都需要完整重新传输。
2026 年 2 月,OpenAI 在其响应 API 中推出了 WebSocket 模式,通过在服务器内存中缓存对话历史来解决这一问题。我十分期待亲自试用,对比它与 HTTP 协议的实际表现差异。
智能体编程循环
自 2025 年 12 月以来,AI 编程智能体已从一个新奇事物变成许多机构日常工作流程的一部分。Claude Code、OpenAI Codex、Cursor、Cline 等工具如今已常态化执行多文件编辑、运行测试套件,并在构建失败时进行迭代优化。OpenAI 的数据显示,Codex 每周活跃用户已超 160 万,Codex 团队的工程师通常会同时运行 4 到 8 个并行智能体。
这些智能体的核心是“智能体循环”:即模型推理与工具执行的循环,会不断重复直至任务完成:
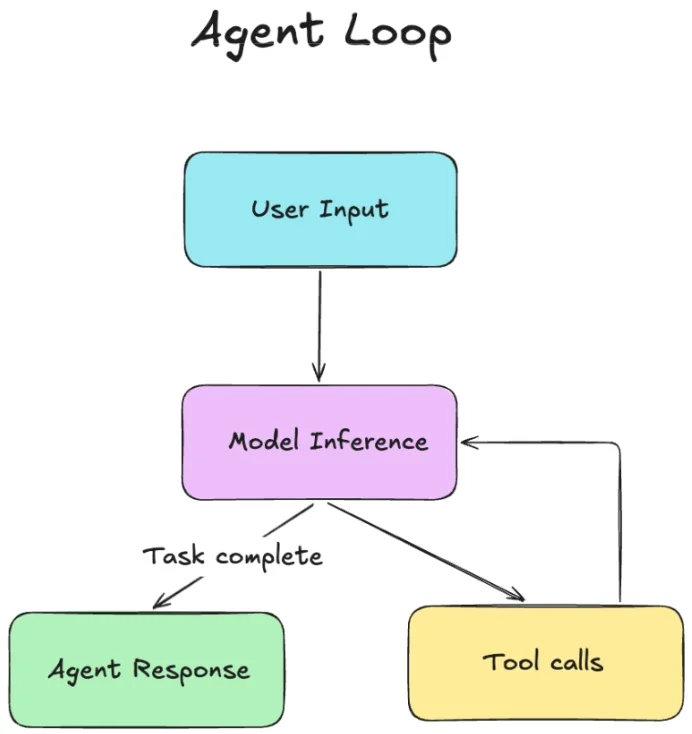
编程智能体循环:在每一轮中,模型要么返回代表任务完成的响应,要么发起工具调用,其结果会被回传给模型继续推理,直至任务完成。
智能体循环的每一轮通常需要读取多个文件,理解代码库、编辑若干文件并运行测试,这一过程会涉及 10 到 15 次工具调用,在进行复杂重构时次数往往更多。这些工具调用的结果会被发送至大语言模型推理服务器。若问题已解决,服务器会返回不再需要工具调用的响应;否则,服务器会推荐后续工具调用,从而开启智能体循环的下一轮。这一过程会持续进行,直到问题解决,且每一轮都要求模型获取截至当前的完整上下文。
HTTP 开销问题
使用基于 HTTP 的 API(包括 OpenAI 的 HTTP 响应 API 和旧版聊天补全 API)时,每一轮都是无状态请求。服务器不会记住上一轮的内容,因此客户端必须重新发送所有内容:
系统指令和工具定义(约 2 KB)
原始用户提示词
之前的每一次模型输出(包括模型编写的完整代码块)
每个工具调用结果(包括文件内容、命令输出)
这意味着请求负载会随每一轮交互线性增长。在我们的基准测试中,我们测量了客户端在使用 HTTP 与 WebSocket 时每轮实际发送的字节数:
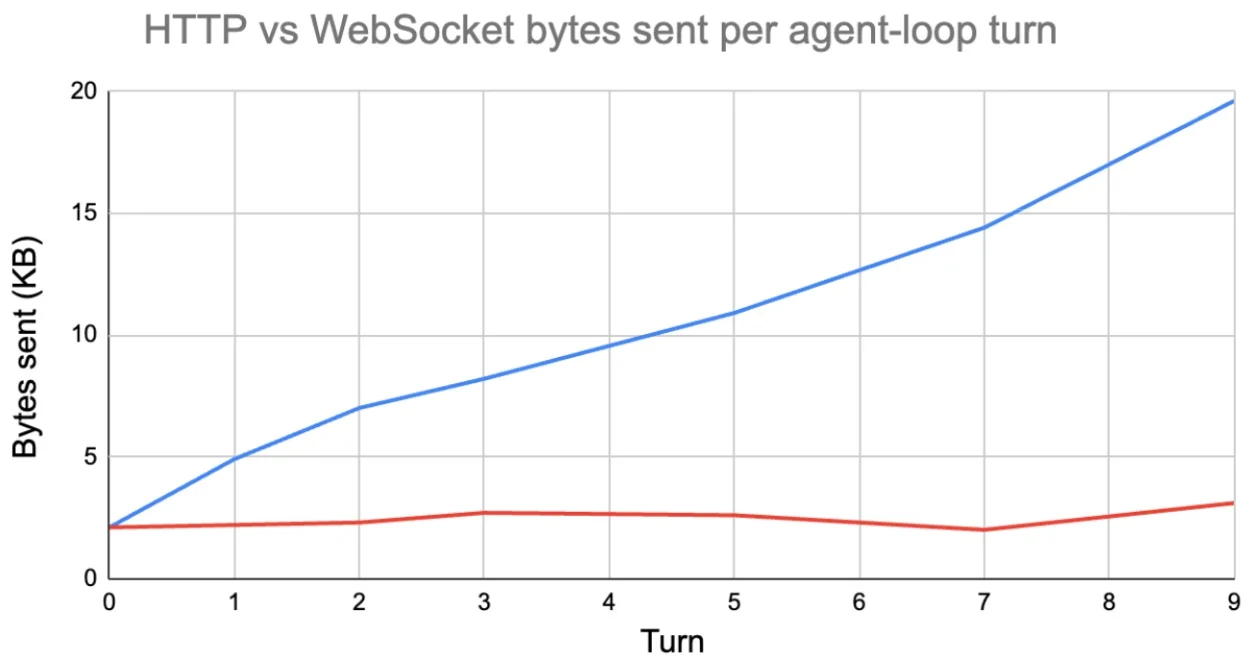
基于 gpt-4o-mini 完成 10 次任务的每轮平均发送字节数:HTTP 呈线性增长,WebSocket 则保持恒定。
到第 9 轮时,HTTP 每轮发送的数据量几乎是 WebSocket 的 10 倍。原因在于 OpenAI 响应 API 的 WebSocket 模式会维持与服务器的持久连接,并在服务器端使用内存状态。从第一轮之后,后续每一轮只需发送:
引用缓存状态的
previous_response_id(约 60 字节)新的工具调用输出(通常是 1 到 3 KB 的文件内容或命令输出)
无论进行多少轮,负载都大致保持恒定。
现有的基准测试
在构建我们自己的测试工具之前,我们查阅了公开可用的数据。
OpenAI 的声明:响应 API 的 WebSocket 模式专为需要大量工具调用、低延迟、长时间运行的智能体而设计。对于工具调用超过 20 次的工作流,该模式通过消除冗余的上下文重传,并利用服务器端内存状态实现跨轮次持久化,可使端到端执行速度提升高达 40%。
Cline 的独立验证:Cline 团队使用 GPT-5.2-codex 对 WebSocket 模式进行了测试,并与标准 HTTP API 集成做对比,结果显示:
简单任务(少量工具调用)快约 15%
复杂多文件工作流(大量工具调用)快约 39%
最佳情况下速度提升 50%
WebSocket 握手会在第一轮略微增加首词元响应时间(TTFT)开销,但这部分开销会很快被摊薄抵消
模式:速度提升与工作流复杂度成正比。仅需 1 至 2 次工具调用的简单任务收益极小,甚至会因 WebSocket 握手产生轻微开销;而需要 10 次以上工具调用的复杂任务则能获得显著优化,因为无需重复传输上下文所累积的速度提升会随轮次不断放大。
我们的基准测试
为了通过受控的测量实验来验证这些结论,我们构建了一个基准测试工具,模拟调用 OpenAI 响应 API 的真实智能体编程工作流。该工具现已开源。
方法论
我们定义了三种不同复杂度的编码任务:
修复失败的测试——读取测试文件、读取组件、修复错误、运行测试(约 10 到 15 轮,12 到 17 次工具调用)
添加搜索功能——读取现有组件、实现功能、运行测试(约 5 到 15 轮,4 到 21 次工具调用)
重构 API 层——梳理项目结构、读取相关文件、查找调用方、更新多个文件、运行测试(约 6 到 11 轮,10 到 20 次工具调用)
每个任务均采用模拟的工具响应(包含真实的文件内容、测试输出与命令执行结果)来隔离传输层所带来的差异。模型会对 OpenAI 发起真实 API 调用,并自主决定调用哪些工具、何时停止流程;不确定性仅来自模型行为,而非工具响应本身。
两种测试配置:
我们测量了:
TTFT(首词元时间):模型在每一轮开始生成内容的速度有多快?
发送的字节数:客户端每个任务上传多少数据?
接收的字节数:返回多少流事件数据?
总时间:完整智能体工作流的端到端耗时(挂钟时间)
每种配置各运行 3 次并汇总结果。我们使用了两个模型——GPT-5.4(前沿代码模型)和 GPT-4o-mini(轻量化快速模型),用以验证传输层的优化效果在不同规模模型下是否一致。
结果
所有的运行结果显示,因模型和传输模式而异,任务平均使用了约 8 到 11 轮传输,工具调用次数为 9 到 16 次。
相对性能对比(WebSocket 对比 HTTP)
GPT-5.4 详细测试结果
关键发现
WebSocket 始终能将客户端发送的数据量减少 80% 至 86%。这是最稳定的结论,不受模型、API 波动或任务复杂度影响。HTTP 每个任务发送 153 至 176 KB 数据,而 WebSocket 仅发送 21 至 32 KB,这得益于无需重复传输不断增长的对话历史。
WebSocket 可使端到端执行速度提升 15% 至 29%。使用 GPT-5.4 时,WebSocket 提速达 29%,与 Cline 团队报告的复杂工作流 39% 提升基本吻合。速度提升主要源于每轮上传数据量减少,以及服务端无需重新解析和分词完整上下文,从而实现更快处理。
第一轮 TTFT 在两种方式下表现相近。WebSocket 握手未产生明显额外开销,两种模型的首轮 TTFT 均与 HTTP 处于同一噪声区间内。优势主要体现在后续轮次,WebSocket 可避免因对话增长带来的持续上传负担。
这一效果与模型无关。我们使用 GPT-4o-mini 运行了相同基准测试(详细结果见仓库),同样实现了 86% 的发送字节节省和 15% 的端到端执行加速。GPT-5.4 的耗时优化更为显著(29% 对比 15%),原因可能是前沿模型生成的响应更长,每轮累积的上下文更多。
为什么它会更快:架构
性能差异是消除冗余数据传输的直接结果。
HTTP:无状态设计
Turn 1: Client → [system + prompt + tools] → ServerTurn 2: Client → [system + prompt + tools + turn1 + output1] → ServerTurn 3: Client → [all of the above + turn2 + output2] → Server...Turn N: Client → [system + prompt + tools + ALL prior turns] → Server每个请求都是相互独立的。服务器处理请求并返回响应后便会丢弃所有上下文信息,客户端必须从头重建完整的对话上下文。
WebSocket:有状态接续
Turn 1: Client → [system + prompt + tools] → Server (server caches response)Turn 2: Client → [prev_id + tool_output] → Server (server loads from cache)Turn 3: Client → [prev_id + tool_output] → Server (server loads from cache)...Turn N: Client → [prev_id + tool_output] → Server (constant-size payload)服务器在本地内存保留最新响应,后续调用可直接引用该缓存状态,因此客户端只需发送新增的内容。
带宽计算:来自我们的基准测试
基于我们实际的 GPT-5.4 测试数据,针对典型的 10 轮编码任务:
HTTP 总发送字节数(客户端 到服务器端):每个任务 176 KB(测量平均值)
随着上下文积累,从第 0 轮的 2 KB 增长到第 9 轮的 38 KB
WebSocket 总发送字节数:每个任务 32 KB(测量平均值)
整个过程中每轮保持在 2 至 4 KB
客户端发送字节数减少了 82%,每个任务节省 144 KB,在数千个并发会话中累积效果尤为显著。
架构经验
1. API 兼容性与性能:协议税
OpenAI 的 HTTP API(包含 /chat/completions 和响应 API)是事实上的标准,几乎所有大模型工具、SDK 与编排框架均支持它。但这种兼容性也存在代价:该 API 本质上是无状态的,要求客户端在每次请求时都重新传输完整上下文。
WebSocket 模式打破了这种兼容性,造成了碎片化。
哪些平台/产品支持 WebSocket?
编码智能体中支持 WebSocket 的有哪些?
WebSocket 目前是 OpenAI 独有的优势。如果你的智能体需要在不同服务商之间切换——例如用 Claude 处理推理密集型任务、用 GPT 追求速度——那么在每次调用非 OpenAI 服务时,都会失去 WebSocket 带来的性能优势。
谷歌的 Gemini Live API 虽采用了 WebSocket,但面向的是实时音视频流,而非文本类智能体工作流。Cloudflare AI Gateway 虽在多家服务商前端提供了 WebSocket 端点,但底层仍为 HTTP 请求,并未实现类似 OpenAI 那般能显著提升速度的服务端状态缓存。
2. 协议开销规模化影响:当每轮字节数变得重要时
对于单个对话而言,重新发送上下文的开销可以忽略不计。但从服务端视角来看,2026 年编码智能体的规模化应用使得这一问题变得不容忽视。
对单个主流服务商的并发会话量估算如下:OpenAI Codex 每周活跃用户达 160 万,GitHub Copilot 拥有 470 万付费订阅用户。Claude Code 年化收入 25 亿美元,对应活跃开发者数量超百万。Cline、Cursor、Windsurf、Roo Code、OpenCode 等产品又新增数百万用户。保守估算,每周有 500 万至 1000 万开发者在积极使用 AI 编程智能体。以 OpenAI 这类头部服务商为例,若按高峰时段 10% 至 20% 的用户活跃且会话重叠计算,其高峰期并发编码智能体会话约为 100 万。
在这种规模下,结合我们实测的单任务数据:
HTTP:100 万会话 × 单任务发送 176 KB = 每 40 秒任务产生 176 GB 的客户端到服务器上行负载
WebSocket:100 万会话 × 单任务发送 32 KB = 每 40 秒任务产生 32 GB 的客户端到服务器上行负载
这相当于在 40 秒的任务中减少 144 GB 入站流量,即降低 29 Gbps 带宽压力。对于需要处理数百万请求的服务商而言,这能减轻 API 网关、分词器(需在每次 HTTP 请求时对完整上下文重新分词)及网络基础设施的负载。服务端的节省甚至比客户端更为关键:接收、解析与分词的数据量减少,意味着所有用户都能获得更快的首词元响应时间。
3. 服务器端状态:真正的创新
关键结论是:WebSocket 更快并非源于协议本身——基于 TCP 的 WebSocket 与 HTTP/2 的帧开销相近。速度提升来自服务端状态管理:WebSocket 服务器会在连接的本地内存中缓存最新响应,实现近乎即时的会话延续,无需对完整对话重新分词。
这会对架构设计产生一系列影响:
状态是临时的:它仅存在于处理当前连接的特定服务器内存中。一旦连接断开,状态就会丢失(store=true 时除外)。
无多路复用:每个 WebSocket 连接同一时间仅处理一个响应。若要并行调用多个智能体,需建立多个连接。
60 分钟限制:连接将在 1 小时后自动断开,时长超过 1 小时的会话需要实现重连逻辑。
对于设计同类系统的架构师来说,模式十分清晰:如果协议中包含大量基于先前上下文逐步推进的顺序请求,在服务端保留该上下文(即便仅存储在易失性内存中)也能显著降低单次请求的开销。
4. 状态化程度谱系
针对上下文累积问题,不同解决方案各有优劣取舍:
对于大多数智能体工作流而言,WebSocket + store=false 是最优方案:既能实现最快的任务接续,数据也不会在服务商服务器上持久化(这对遵循零数据留存政策的企业而言至关重要);若连接断开,直接从任务起始点重新启动即可,无需尝试从中断位置恢复。
5. 并行执行:多个连接,而非多路复用
每个 WebSocket 连接同一时间仅处理一个响应,不支持多路复用。若要执行并行任务(如像 Codex 工程师那样同时运行 4 到 8 个智能体),则需要建立独立的 WebSocket 连接。每个连接依然能享受 WebSocket 带来的带宽节省,但由于执行速度更快,并发连接相比并发 HTTP 请求更容易触发 API 限流。
HTTP 依然适用的场景
WebSocket 模式并非在所有场景下都更优。以下场景建议使用 HTTP:
简单、少轮次交互:对于 1 到 2 轮的交互,上下文重传的开销可以忽略,无需为此增加系统复杂度。
多厂商支持:若需要在 OpenAI、Anthropic、Google 及本地模型之间切换,标准 HTTP API 是通用规范。WebSocket 模式目前为 OpenAI 独有,采用后会造成厂商锁定。
无状态基础设施:若后端运行在无法维持持久连接的无服务器函数(Lambda、Cloud Functions 等)上,HTTP 是唯一选择。
调试与可观测性:HTTP 请求可通过标准工具更方便地进行记录、重放与调试,而 WebSocket 则需要专用工具支持。
结论
在智能体编程工作流中,从无状态 HTTP 切换到有状态 WebSocket 连接带来了显著的性能提升:端到端执行速度加快 29%,客户端发送数据量减少 82%,并且在使用 GPT-5.4 时 TTFT 降低 11%,这一结果已通过我们针对 OpenAI 响应 API 的受控基准测试验证。
但 WebSocket 的优势也伴随着相应代价:该方案目前为 OpenAI 独有,在开发者愈发希望在不同模型间灵活切换的生态环境中,会造成厂商锁定。主要替代方案——包括 Anthropic Claude API、Google Gemini、OpenRouter 以及本地模型服务器——均未针对文本类智能体工作流提供对等的 WebSocket 支持。
对于构建智能体系统的架构师而言,不能盲目采用 WebSocket,而是要意识到:随着 AI 工作流从单轮交互转向多轮交互,对聊天机器人而言无关紧要的传输层选择对智能体来说却至关重要。任何能够避免重复传输日益增长的对话上下文的方案——无论是通过 WebSocket、服务端会话缓存,还是自定义有状态协议——都能获得类似的性能收益。问题在于,行业是否会形成一套面向有状态 LLM 接续的通用标准,还是这一特性仍将作为各厂商独有的竞争优势存在。
基准测试工具和所有结果可在此处获取。
【声明:本文由 InfoQ 翻译,未经许可禁止转载。】
查看英文原文:https://www.infoq.com/articles/ai-agent-transport-layer/




