
“把圆餐桌上的脏杯子放进洗碗机。”这句指令对 3 岁小孩都简单,但对 AI 机器人,是一场严峻的挑战。
它要先搞懂哪个是“圆餐桌”(木质的还是玻璃的?),然后判断杯子可能在桌上、柜子里还是水槽边。走到一半发现视野里根本没有杯子,它懵了:我该往哪儿找?刚才的计划还作数吗?更麻烦的是,就算找到了杯子,洗碗机的门可能是关着的——它得先开门,再放进去,再关门……
这不是段子,而是具身任务规划(Embodied Task Planning, ETP) 的真实困境。现在的视觉-语言模型(VLM)通过大规模预训练展示了卓越的多模态理解能力,但一旦被扔进真实的家庭环境,需要多轮交互、长程推理、扩展上下文分析,它们就像理论优异的学生第一次下厨房:理论全能,实操抓瞎。
如何解决这一难题?北京大学副教授穆亚东及北京大学与星源智团队共同提出了 RoboAgent 方案。该方案采用能力驱动的具身路径规划,将复杂的规划任务分解为一系列更简单的视觉语言问题;同时,设计了一个多阶段训练路径,利用中继监督(intermediate supervision)与多样化数据来源,系统性地优化 VLM 的规划能力。
值得一提的是,该核心方案相关论文《RoboAgent: Chaining Basic Capabilities for Embodied Task Planning 》成功入选全球计算机视觉顶会 CVPR 2026。本届 CVPR 投稿量高达 16092 篇,录用率仅为 25.42%,该论文入选亦彰显了团队在具身智能领域前沿创新的硬核实力。
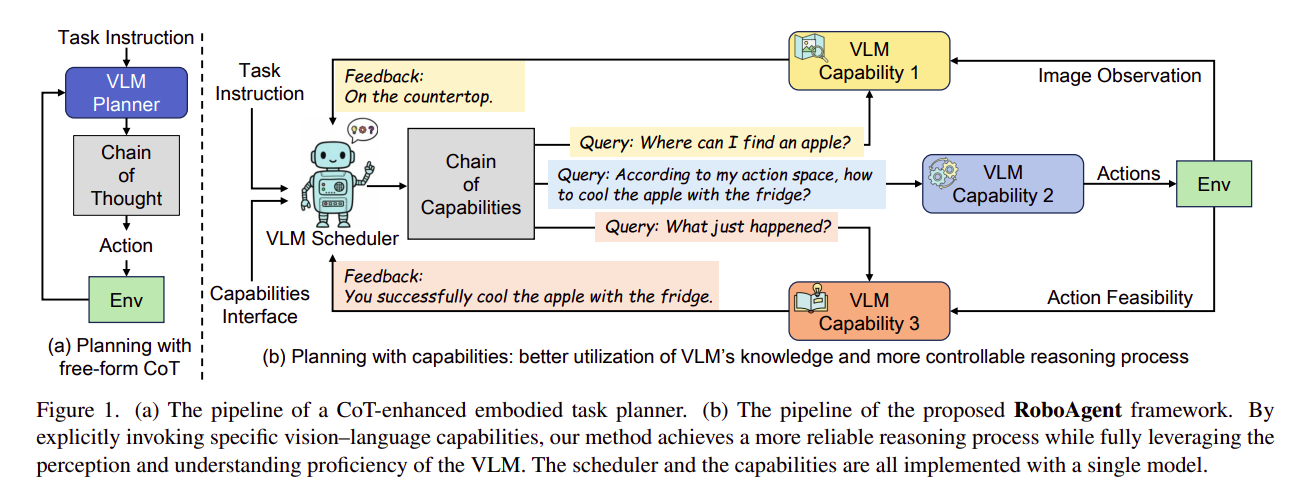
为什么 VLM 自己搞不定?
传统做法要么让 VLM 直接输出动作序列,要么加一段“思维链”(CoT)推理。但在 ALFWorld 这类需要探索+操作的仿真环境里,问题层层叠加:模型要先理解模糊指令(比如“那个圆圆的、放在厨房岛上的东西”),推测目标可能藏在哪里,导航过去,识别物体,最后执行抓取、放置等动作。任何一个子任务出错,整个任务就崩了。
更棘手的是,奖励信号极其稀疏——可能走了 20 步才判断成败。用纯强化学习(RL)训练,模型往往在无效探索中耗光步数。而单纯模仿专家轨迹,又无法泛化到没见过的新场景。
RoboAgent 的核心洞察是:把“规划”拆成一系列更小的、VLM 本来就擅长的视觉-语言子问题。 具体来说,RoboAgent 定义了 5 个能力模块:
EG(探索引导):给定目标物体,根据常识推断最可能的位置,预测最有可能的探索方向以找到该物体。
OG(物体定位):做开放词汇检测(即模型能够根据自然语言描述,在图像或场景中定位出训练阶段从未见过的物体或概念),判断当前视野里有没有目标物体。
SD(场景描述):用文字描述目标物体的当前状态。
AD(动作解码):把导航或操作指令转成具体原子动作(atomic actions)。
ES(经验总结):总结由 AD 生成的动作序列的交互结果,并在发生错误时分析失败原因。
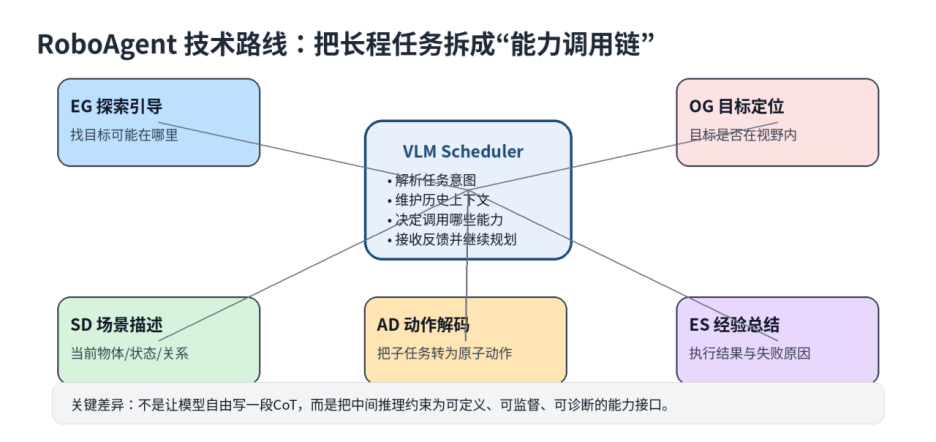
图注:Scheduler 调度五类基础能力,形成可监督的能力链
所有模块由同一个 VLM 实现,不依赖任何外部工具,端到端可训练。
三阶段训练:从模仿到自我纠错,再到专家引导
光有架构不够,怎么训练这个 VLM 让它学会“调用能力”?团队设计了一套三阶段路径规划(planning pipeline),充分利用模拟器的内部特权信息(物体位置、实例分割、动作成败反馈)——这些信息在实际推理时不可用,但训练时能提供高质量监督。
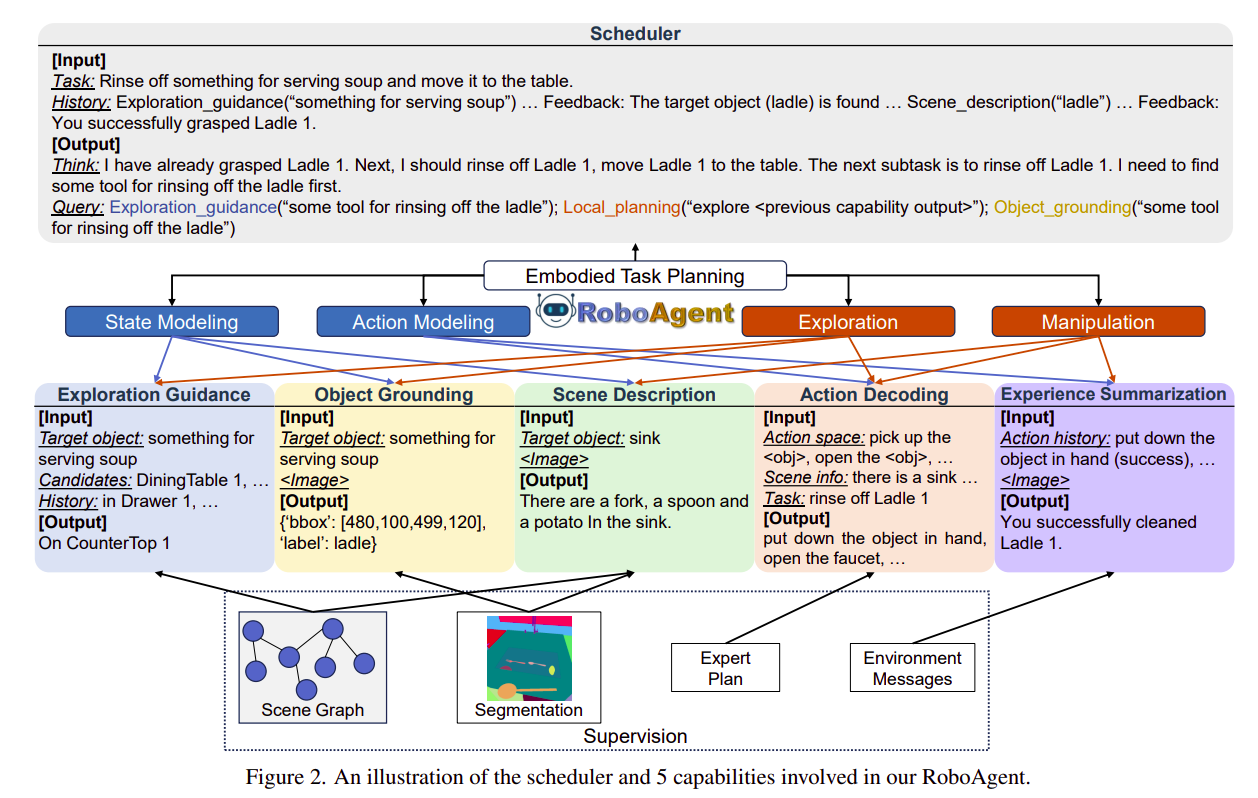
阶段一:使用专家轨迹进行训练
把 ALFRED 数据集里的专家轨迹拆成探索子目标和操作子目标,转换成能力调用序列,并自动生成思维链。用这些数据做有监督微调,共生成 640k 个训练样本。
阶段二:使用模型生成的数据进行训练
让阶段一的模型在实际训练任务上跑一遍,收集它生成的轨迹(无论成功或失败)。然后利用模拟器内部信息,为每个能力调用构建纠正性监督:比如模型说“去柜子找叉子”,但模拟器显示叉子其实在抽屉里,就纠正它的输出。这一步生成 690k 个样本,让模型学会从错误中修正。
阶段三:使用专家策略进行训练
调度员的输出是“调用哪些能力”,很难直接给奖励。团队提出 EIPO(Expert-Induced Policy Optimization) 算法:用专家调度员(知道所有子目标的完成顺序)来计算每个状态-动作对下的专家优势函数,然后像 PPO/GRPO 那样做策略优化。因为专家优势可以直接从任务结构算出,避免了传统 RL 的方差问题,训练更稳更快。这一步额外合成了 25k 条带错误恢复的轨迹。
实验结果:3B 模型性能超过 7B 和 GPT-4o
团队在多个基准上做了严格测试。训练只用 ALFRED 的训练集(6.4k 任务),但评估在 ALFWorld(视觉+文本)、EB-ALFRED,甚至跨模拟器的 EB-Habitat 和 LoTa-WAH 上——全是未见过的新场景、新指令。所有结果来自同一个微调后的 Qwen2.5-VL-3B 模型。
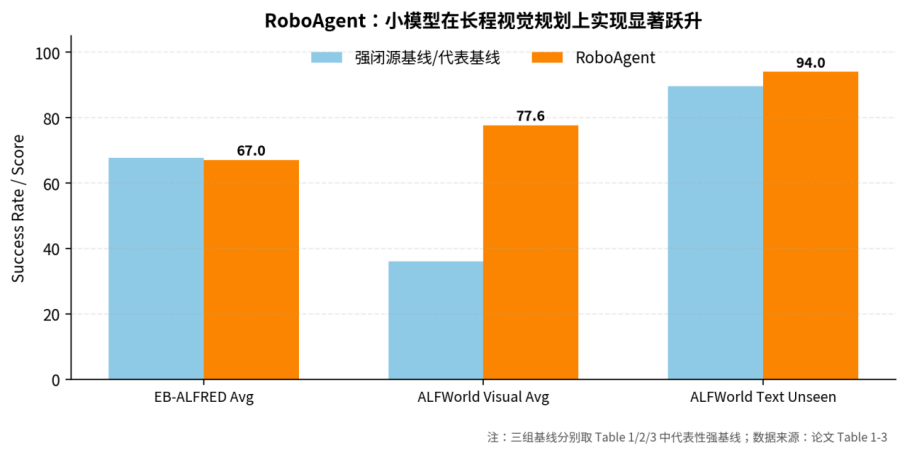
图注:RoboAgent 在主要 benchmark 上的代表性结果
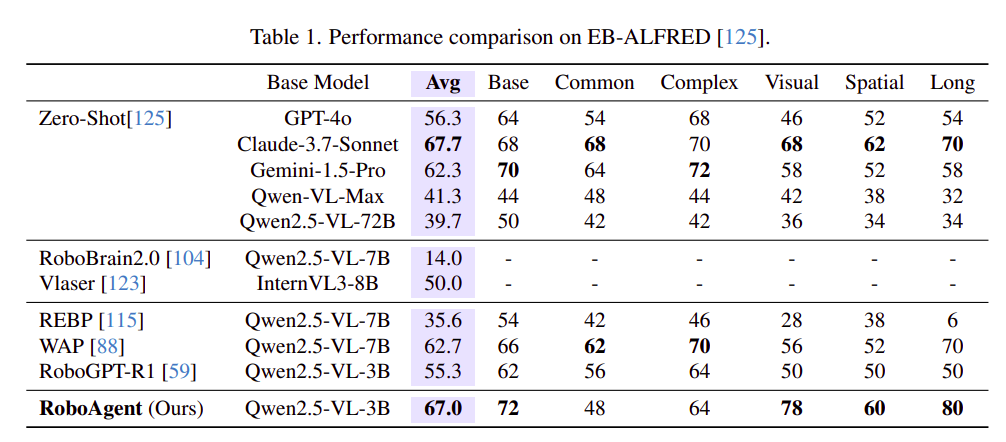
表 1(EB-ALFRED):RoboAgent 平均成功率 67.0%,超过所有微调类方法(如 REBP 的 35.6%、WAP 的 62.7%),甚至在 Visual 分项达到 78%,超过了 GPT-4o 的 46%。
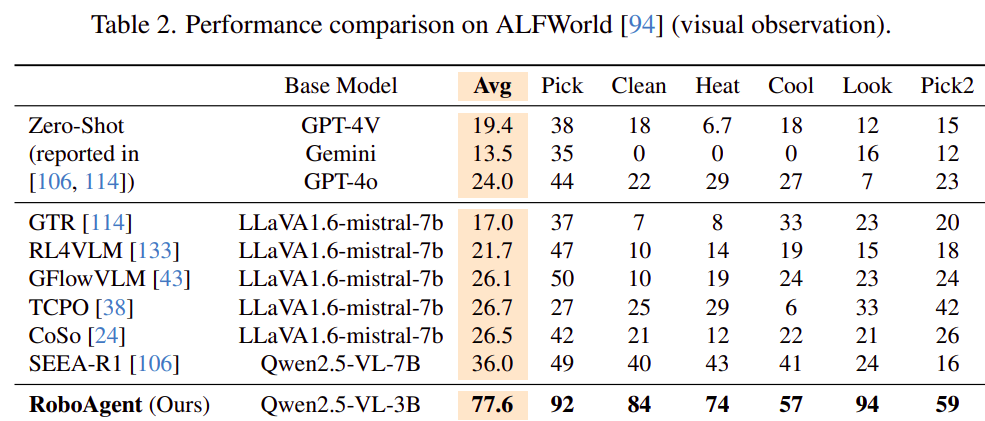
表 2(ALFWorld 视觉):RoboAgent 平均 77.6%,大幅领先此前最好的 SEEA-R1(36.0%)和 GPT-4o(24.0%)。尤其在 Pick、Clean 等类别上优势明显。这得益于 EG/OG 带来的显式探索,让模型学会优先检查最可能有物体的容器(如“杯子”大概率在“橱柜”而非“马桶”上),而非盲目乱走。
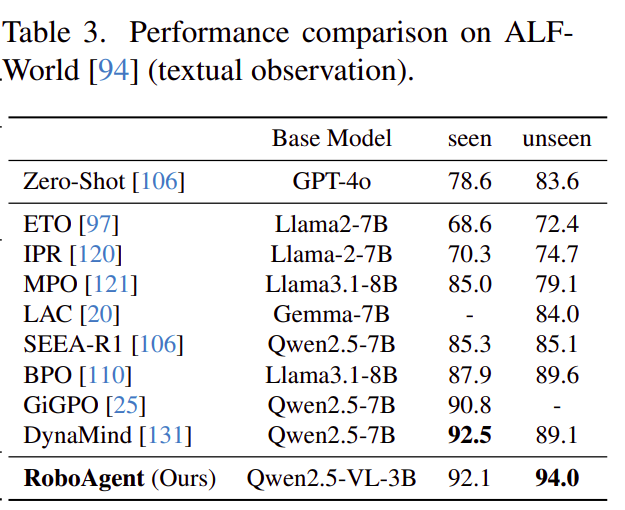
表 3(ALFWorld 文本):RoboAgent 在未见过的场景成功率达 94.0%,超过当前最顶级的 LLM 方案(DynaMind 89.1%),且用的是更小的 3B VLM——说明能力驱动的范式具备模态无关的泛化力,图像能力可以无缝迁移到文本输入。
结语
现代 VLM 本身具备处理具身推理的所有能力,缺的只是合适的调用机制。RoboAgent 提供了这样一套机制:不依赖外部工具,单一模型,端到端训练。它通过 VLM 同时担任调度器和五种特定能力,将复杂的规划过程分解为一系列基础的视觉语言理解问题 。
未来,随着能力模块的动态扩展和训练数据的规模化,这类“能力驱动”的架构很可能成为长程机器人规划的标配。毕竟,再聪明的 AI,也得学会分工协作。




