 OpenJDK 的非堆 JDK 增强提议(JDK Enhancement-Proposal,JEP)试图标准化一项基础设施,它从 Java6 开始,只能在 HotSpot 和 OpenJDK 内部使用。这种设施能够像管理堆内存那样管理非堆内存,同时避免了使用堆内存所带来的一些限制。对于上百万短期存在的对象 / 值来说,堆内存工作起来是很好的,但是如果你想要增加一些其他的需求,如几十亿的对象 / 值的话,假若你想避免持续增加的 GC 暂停,那么你需要做一些更加有创造性的工作。在有些场景下,你还需要完全避免暂停。非堆提供了构建“arenas”内存存储的功能,它遵循自己的规则,并不会影响到 GC 的暂停时间。两个很容易使用 arenas 的集合是 Queue 和 HashMap,因为它们具有很简单的对象生命周期,所以编写自己的垃圾收集并不太繁琐。这种集合所带来的好处就是它的大小能够比传统的堆集合大得多,甚至超过主存储器(main memory)的规模,而对暂停时间的影响却微乎其微。相比之下,如果你的堆大小超过了主存储器,那么你的机器就会变得不可用,可能会需要关电源重启。
OpenJDK 的非堆 JDK 增强提议(JDK Enhancement-Proposal,JEP)试图标准化一项基础设施,它从 Java6 开始,只能在 HotSpot 和 OpenJDK 内部使用。这种设施能够像管理堆内存那样管理非堆内存,同时避免了使用堆内存所带来的一些限制。对于上百万短期存在的对象 / 值来说,堆内存工作起来是很好的,但是如果你想要增加一些其他的需求,如几十亿的对象 / 值的话,假若你想避免持续增加的 GC 暂停,那么你需要做一些更加有创造性的工作。在有些场景下,你还需要完全避免暂停。非堆提供了构建“arenas”内存存储的功能,它遵循自己的规则,并不会影响到 GC 的暂停时间。两个很容易使用 arenas 的集合是 Queue 和 HashMap,因为它们具有很简单的对象生命周期,所以编写自己的垃圾收集并不太繁琐。这种集合所带来的好处就是它的大小能够比传统的堆集合大得多,甚至超过主存储器(main memory)的规模,而对暂停时间的影响却微乎其微。相比之下,如果你的堆大小超过了主存储器,那么你的机器就会变得不可用,可能会需要关电源重启。
本文将会调查这个 JEP 的影响,它会让大家熟悉的 Java HashMap 具备新的非堆功能。简而言之,这个 JEP 所具有的魔法能够“教会”HashMap(这是一个可爱的 _ 老 _ 家伙 old dog)一些 _ 新的 _ 技巧。这个 JEP 会要求将来的 OpenJDK 发布版本与传统 Java 平台的优先级产生很大的差异:
- 将 sun.misc.Unsafe 中有用的部分重构为一个新的 API 包
- 提倡使用新的 API 包在非堆的原生内存操作对象上直接进行高性能的原生内存操作。
- (通过新的 API)提供外部功能接口(Foreign Function Interface,FFI)来桥接 Java 与操作系统资源(Operating System resource)和系统调用(system call)。
- 允许 Java 运行时借助硬件事务内存(Hardware Transactional Memory)提供者的foci,将低并发的字节码重写为高并发性的 speculatively branched 机器码。
- 移除 FUD(坦率的说,这是一种技术上的偏执),它与使用非堆编程策略来实现 Java 性能的提升有关。最终,基本明确的是这个 JEP 要求 OpenJDK 平台要开放性地将其纳为主流,它曾经被视为黑暗的工艺、非堆参与者的秘密组织。
本文力图(以一种通俗和温和的方式)让所有感兴趣的 Java 开发人员都能有所收获。作者希望即使是新手也能完整地享受本文所带来的这段旅程,尽管在路途上可能会有一些不熟悉的“坑坑洼洼”,但是不要气馁——希望您在位置上安坐直到文章结束。本文会提供一个有关历史问题的上下文,这样你会对下面的问题具备足够的背景知识:
- 堆 HashMap 的问题是怎么产生的?
- 为了应对这些问题,历史上所给出方案的成功 / 失败之处是什么?
- 在堆 HashMap 的使用场景中,依然存在的未解决问题是什么?
- 新 JEP 所提供的功能能够带来什么助益(也就是将 HashMap 变为非堆的)?
- 对于非堆 JEP 所没有解决的问题,将来的 JEP 能够给我们什么期待呢?
那么,让我们开始这段旅程吧。需要记住的一点是在 Java 之前,哈希表(hash table)是在原生内存堆中实现的,比如说在 C 和 C++ 中。在一定程度上可以说,重新介绍非堆存储是“老调重弹”,这是大多数当前的开发人员所不知道的。在许多方面可以说,这是一趟“回到未来”的旅行,因此享受这个过程吧!
OpenJDK 非堆 JEP
针对非堆 JEP,已经有了几个提议(submission)。下面的样例展现了支持非堆内存的最小需求。其他的提议尝试提供 sun.misc.Unsafe 的替代品,这个类是目前的非堆功能所需要的。它们还包含了很多其他有用和有趣的功能。
_JEP 概述:_ 创建 sun.misc.Unsafe 部分功能的替代品,这样就没有必要再去直接使用这个库了。
_ 目标:_ 移除对内部类的访问。
非目标: 不支持废弃(deprecated)的方法,也不支持 Unsafe 尚未实现的方法。
_ 成功指标:_ 实现与 Unsafe 和 FileDispatcherImpl 相同的核心功能,并且性能方面要与之保持一致。
驱动力: 目前来讲,Unsafe 是构建大规模、线程安全的非堆数据结构的唯一方法。在如下的领域,这种方式会很有用,如最小化 GC 的影响、跨进程共享内存以及在不使用 C 和 JNI 的情况下实现嵌入式数据库,因为使用 C 和 JNI 的话,可能会更慢并且更加困难。FileDispatcherImpl 目前需要将内存映射为任意的大小。(标准 API 限制为小于 2GB。)
描述: 为非堆内存提供一个包装类(类似于 ByteBuffer ),但是具有如下的功能增强。
- 64 位的大小和偏移。
- 线程安全结构,如 volatile 和顺序访问、比较和交换(compare and swap,CAS)操作。
- JVM 优化的边界检查,或开发人员控制边界检查。(提供的安全设置允许这样做)
- 在一个缓冲区中,能够为不同的记录重用部分缓冲区。
- 能够将非堆的数据结构映射到这样一个缓冲区之中,在这个过程中,边界检查已经被优化掉了。
要保留的核心功能:
- 支持内存映射文件
- 支持 NIO
- 支持将写操作提交到磁盘上。
_ 替代方案:_ 直接使用 sun.misc.Unsafe。
_ 测试:_ 测试需求应该与目前的 sun.misc.Unsafe 和内存映射文件相同。还需要额外的测试来证明它与 AtomicXxxx 类一致的线程安全操作。AtomicXxxx 类可以使用这个公开 API 进行重写。
_ 风险:_ 有很多的开发人员在使用 Unsafe,他们可能并不认同合适的替代方案是什么。这意味着这个 JEP 的范围可能会扩大,或者会创建新的 JEP 来涵盖 Unsafe 中的其他功能。
其他 JDK: NIO
_ 兼容性:_ 需要保持向后兼容的库。这可以针对 Java 7 实现,如果有足够兴趣的话,也可以支持 Java 6。(当撰写本文的时候,当前的版本是 Java 7)
安全性:理想情况下,安全性的风险不应该超过当前的 ByteBuffer。
性能和可扩展性:优化边界检查会比较困难。可能需要为这个新的缓冲区添加更多的功能,通过通用的操作来减少损耗,如 writeUTF、readUTF。
HashMap 简史
“哈希码(Hash Code)”这个术语最早于 1953 年 1 月出现在 Computing 文献之中, H. P. Luhn (1896-1964)在编写 IBM 内部备忘录时,使用到了这个术语。Luhn 试图解决的问题是“给定一个文本格式的单词流,要实现 100% 完整的(单词、页集)索引,最优的算法和数据结构是什么样的?”

H.P. Luhn (1896-1964)
Luhn 写到“hashcode”是基本的运算符(operator)。
Luhn 写到“关联数组(Associative Array)”是基本的运算对象(operand)。
术语“HashMap”(亦称为 HashTable)逐渐形成了。
注意:HashMap 这个词源自出生于 1896 年的计算机科学家。HashMap 真的是个老家伙了!
让我们将 HashMap 的故事从它的起始阶段转移到早期的实际使用阶段,也就是从 1950 年代中期跳到 1970 年代中期。
在其 1976 年写成的经典著作《算法+ 数据结构= 程序》之中, Niklaus Wirth 讨论了“算法”,将其视为基本的“运算符”,并将“数据结构”视为基本的 “运算对象”,对于所有的计算机程序来讲这都是适用的。
从那时开始,数据结构领域(HashMap、堆等)的进步是很缓慢的。在 1987 年,我们确实也看到了 Tarjan _ 非常 _ 重要的 F-Heap 突破,但是除此之外,在运算对象方面确实乏善可陈。当然需要记住的是,HashMap 最早出现于 1953 年,已经有超过六十年的历史了!
然而,在算法社区( Karmakar 1984, NegaMax 1989, AKS Primality 2002, Map-Reduce 2006, Grover Quantum 搜索 - 2011)却是发展迅速,为计算机基础领域提供了新鲜和强大的运算符。
但是在 2014 年,数据结构领域可能再次会有一些重大的进展。在 OpenJDK 平台方面,非堆的 HashMap 是一个正在不断发展的数据结构。
关于HashMap 的历史,我们已经介绍了很多的内容。现在,我们开始探索一下如今的HashMap,尤其是看一下在Java 中,HashMap 当前的三个变种。

N. Wirth 1934-
java.util.HashMap(非线程安全)
在真正的多线程(Multi-Threaded,MT)并发用户场景下,它会快速失败,并且每次都是如此。所有地方的代码必须使用 Java 内存模型(Java Memory Model,JMM)的内存屏障策略(如 synchronized 或 volatile)以保证执行的顺序。
 会发生失败的简单假设场景:
会发生失败的简单假设场景:
- 同步写入
- 非同步读取
- 真正并发(2 x CPU/L1)
让我们看一下为什么会发生失败……
假设 Thread 1 往 HashMap 中进行写入,而写入的效果 _ 只 _ 存储在 CPU 1 的一级缓存之中。然后,Thread 2 几秒后得以在 CPU 2 上继续执行,它会读取来自于 CPU 2 一级缓存中的 HashMap——这并不会看到 Thread 1 的写入,这是因为写入和读取线程中的写读操作之间 **都没有内存屏障操作,而这是共享状态的 Java 内存模型所需要的。即便 Thread 1 同步写操作,写操作的效果刷新到了主内存中,Thread 2 依然看不到变化的效果,因为读取操作来自于 CPU 2 的一级缓存。所以,在写入操作上的同步只能避免 _ 写入 _ 操作的冲突。要满足所有线程的内存屏障操作,你必须还要 ** 同步读取。
thrSafeHM = Collections.synchronizedMap(hm) ;(粗粒度的锁)
要使用“synchronized”达到高性能的话,竞争出现的机率要比较低。**这种场景是非常常见的,因此在很多场景中,这并不会像听上去那么糟糕。** 但是,如果你要引入竞争的话(多个线程同时尝试操作同一个集合),就会影响到性能了。在最坏的场景下,如果有高频率的竞争,最终的结果可能是多个线程的性能甚至比不上单个线程的性能(没有任何锁定和竞争的操作)。
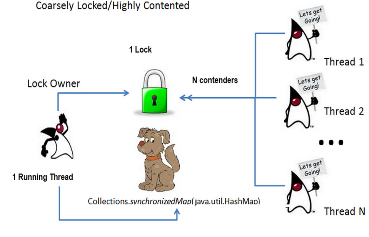
这是通过在所有的 key 上粗粒度地阻塞所有 mutate() 和 access() 操作实现的,实际上就是在所有的线程操作符上阻塞整个 Map 操作对象,只有一个线程可以对其进行访问。这导致的了零多线程并发(Zero MT-concurrency),也就是同时只有一个线程在进行访问。这种粗粒度锁的另外一个结果是我们非常不喜欢的一个场景,被称之为高度的锁竞争(High Lock Contention)(参见左图,N 个线程在竞争一个锁,但是必须要阻塞等待,因为这个锁被正在运行的一个线程所持有)。
对于这种完全同步、非并发、isolation=SERIALIZABLE(并且总体上来说令人失望)的 HashMap,幸好在我们即将到来的 OpenJDK 非堆 JEP 中有了推荐的补救措施:硬件事务性内存(Hardware Transactional Memory,HTM)。借助HTM,在Java 中编写粗粒度同步阻塞将会再次变得很酷。HTM 会帮助将零并发的代码在硬件层面转换为真正并发且100% 线程安全的。这会再次变得很酷,对吧?
java.util.concurrent.ConcurrentHashMap(线程安全、更巧妙的锁,但是依然不“完美”)
在 JDK 1.5 发布的时候,Java 程序员发现在核心 API 中包含了期待已久的 java.util.concurrent.ConcurrentHashMap。尽管 CHM 并不能成为 HashMap 统一的替代方案(CHM 使用更多的资源,在低竞争的场景下可能并不合适),但是它确实解决了其他 HashMap 所不能解决的问题:实现真正的多线程安全和真正的多线程并发。让我们画图来展现一下 CHM 能够带来什么好处 _。_
- 锁分片
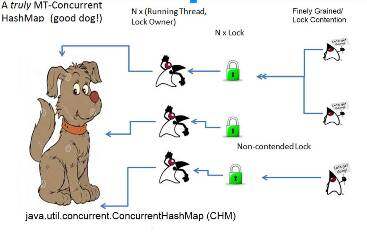
- 对于 java.util.HashMap 中独立的子集有一个锁的集合:N 个 hash 桶 /N 个分段(Segment)锁。(右侧的图中,Segments=3)
- 如果在设计时,想要将高度竞争的锁重构为多个锁,而又不损害数据完整性时,锁分段是非常有用的。
- 对于“检查并执行(check-then-act)”的竞态条件问题,它能够提供并发性更好且非同步的解决方案。
- 问题:该如何同时保护整个集合?(递归)获取所有的锁?

那么,现在你可能会问:有了 ConcurrentHashMap 和 java.uti.concurrent 包,高性能计算社区(High Performance Computing community)是否可以将Java 作为编程平台来构建方案以解决他们的问题呢?
非常遗憾的是,最为现实的答案依然是“时机尚未成熟”。那么,还存在的问题到底是什么?
CHM 有一个问题是有关扩展性和持有中等生命周期(medium-lived)对象的。如果有少量的重要集合使用 CHM 的话,那么其中有一些可能会非常大。在有些场景下,你会有大量中等存活时间的对象保存在这样的集合中。中等生命周期对象的问题在于它们占用了大部分的 GC 暂停时间,比起短期存活(short-lived)的对象,它们的成本可能会高上 20 倍。长期存活的对象会位于老年代,而短期存活的对象在新生代就会死亡,但是中等生命周期的对象会经历所有的 survivor 空间复制,然后在老年代死亡,这使得它们的复制和最终清理成本很高。理想情况下,你所需要的存储数据的集合对 GC 的影响是零。
ConcurrentHashMap 中的元素在运行时位于 Java VM 的堆中。CHM 位于堆上,因此它是造成 Stop-the-World (STW)暂停的重要因素,我们不将其称之为 _ 最重要的因素 _ 其实也差不多。当 STW GC 事件发生时,所有的应用程序线程都会经历“难堪的暂停”延迟。这种延迟,是由位于堆上的 CHM(及其所有的元素)造成的,这是一种痛苦的体验。这种体验和问题是高性能计算社区所无法忍受的。
 在高性能计算社区 _ 完全 _ 拥抱 Java 之前,_ 必须 _ 要有一种方案驯服堆GC 这个怪兽。
在高性能计算社区 _ 完全 _ 拥抱 Java 之前,_ 必须 _ 要有一种方案驯服堆GC 这个怪兽。
这个方案在理论上非常简单:将CHM 放在堆外。
当然,该方案_ 也正是_ 这个OpenJDK 非堆JEP 所要设计支持的。
在深入介绍HashMap 非堆生命周期之前,让我们看一下有关堆的细节,这些细节描述了它的不便之处。
Heap 的简史
Java 堆内存是由操作系统分配给 JVM 的。所有的 Java 对象都是通过其堆上的 JVM 地址 / 标识来进行引用的。堆上的运行时对象引用肯定会位于两个不同的堆区域中的某一个上。这些区域更为正式的叫法是 _ 代(generation)。具体来讲:(1)新生(Young)代(包括 EDEN 区和两个 SURVIVOR 子空间)以及(2)老年(Tenured)代。(注意:Oracle 宣布 **永久代** 将会从 JDK 7 开始逐渐淘汰,并会在 JDK 8 中完全消除掉)。所有的分代 _ 都会导致恐怖的“Stop-the-World”完整垃圾回收事件,除非你使用“无暂停(pause less)”的收集器,如 Azul 的 Zing 。
在垃圾收集的领域,_ 操作 _ 是由“收集器”执行的,这些收集器的 _ 操作对象 _ 就是堆中的目标分代(及其子空间)。收集器会操作在堆的目标分代 / 空间上。垃圾收集的完整内部细节是另外一个(很大的)主题,在一篇专门的文章中进行了阐述。
就现在来说,记住这一点就够了:如果(任意类型的)某个收集器在任何分代的堆空间上导致“Stop the World”事件,那么这就是一个严重的问题。
这是一个必须要有解决方案的问题。
这是非堆JEP 能够解决的一个问题。
让我们近距离地看一下。
Java 堆的布局:_ 按照分代 _ 的视角

垃圾收集使得编写程序容易了许多,但是当面临 SLA 目标时,不管是写在书面上的还是隐含的(比如 Java Applet 停止 30 秒是 _ 不能 _ 允许的),Stop-The-World 暂停时间都是一个很令人头疼的问题。这个问题非常严重,以至于对于很多 Java 开发人员来说,这是他们所面对的唯一的问题。值得一提的是,当 STW 不再是问题的时候,还有很多其他要解决的性能问题。
使用非堆存储的收益在于中等生命周期对象的数量会急剧下降。它甚至还能降低短期存活对象的数量。对于高频率的交易系统,一天之内所创建的对象可能会比 Eden 区还小,这意味着一天之内甚至不会触发一次 minor 收集。一旦内存方面的压力降低了,并且有很少的对象能够到达老年代,那么优化 GC 将会变得非常容易。通常你甚至不需要设置任何的 GC 参数(除了可能会增加 eden 的大小)。
借助转移到非堆上,Java 应用通常可以宣告完全主宰自己的命运,也就是能够满足性能的 SLA 期待和条款。
稍等。刚才最后一句话是什么意思?
注意:所有的乘客,请收起您的折叠板并将座椅调至直立状态。这是很值得重复的一句话,也是这个 OpenJDK 非堆 JEP 所解决的核心问题所在。
通过将集合(如 HashMap)实现非堆,Java 应用通常可以宣告完全主宰自己的命运(不再受 STW GC“难堪的暂停”事件的摆布),也就是能够满足性能的 SLA 期待和条款。
这是一个具备实用性的可选方案,在基于 Java 的高频率交易系统上已经得到了应用。
对于 Java 来说,如果想对高性能计算社区保持持续的吸引力,这也是一个完全必要的方案。
堆的优势
- 以熟悉的方式,很自然地编写 Java 代码。所有有经验的 Java 开发人员都能编写这样的代码。
- 安全,不必担心内存访问问题。
- 自动化的 GC 服务——没有必要自己去管理 malloc()/free() 操作。
- 对 Java 锁 API 和 JMM 的集成都完全不必再担心。
- 没有序列化 / 复制的数据要添加到结构体之中。
非堆的优势
- 能够将“Stop The World” GC 事件控制到你认为合适的级别。
- 在扩展性方面(当使用堆所造成的影响足够高的时候)要强于堆上的结构。
- 可以用做原生的 IPC 传输手段(不会有 java.net.Socket 的 IP 回路)。
- 在分配方法上的考虑因素:
- 使用 NIO DirectByteBuffer,实现到 /dev/shm (tmpfs) 的映射?
- 或者直接使用 sun.misc.Unsafe.malloc()?
HashMap 的现状……(通过使用非堆)这个“老家伙”能够解决什么新问题?
OpenHFT HugeCollections (SHM) 简介
“非堆”到底是什么?
在下面的图中,阐述了两个 JavaVM 进程(PID1 和 PID2),它们试图使用 SharedHashMap(SHM)作为进程间通信(inter-process communication,IPC)的设施。图中底部的水平轴展现了完整的 SHM OS 位置分布域。当进行操作的时候,OpenHFT 对象 _ 必须 _ 要位于 OS 物理内存的用户地址空间或者内核地址空间。继续深入研究一下,我们知道开始的时候,它们必须是“On-Process”的位置。按照 Linux OS 的视角来看,JVM 是一个 a.out (通过调用 gcc 来生成)。当这个 a.out 运行时,从 Linux 进程内部来看,这个运行的 a.out 有一个 PID。 PID 的 a.out(在运行时)有一个大家所熟知的内部构造, 包含了三个段(segment):
- 文本段(Text,低地址……代码执行的地方)
- 数据(Data,通过 sbrk(2) 实现从低地址到高地址的增长)
- 栈(从高地址向低地址增长)
这是在 OS 的角度来看 PID。PID 是一个正在执行的 JVM,这个 JVM 对其操作对象的可能位置分布有一个自己的视角。
按照 JVM 的视图,操作对象可能位于 On-PID-on-heap(正常的 Java)或者 On-PID-off-heap(通过 Unsafe 或 NIO 的 bridge 桥接到 Linux mmap(2) )之中。不管是 On-PID-on-heap 还是 On-PID-off-heap,所有的操作对象依然都还是在用户地址空间中执行。在 C/C++ 中,有 API(OS 系统调用)能够允许 C++ 操作对象位于 Off-PID-off-heap 上。这些操作对象存在于核心地址空间上。
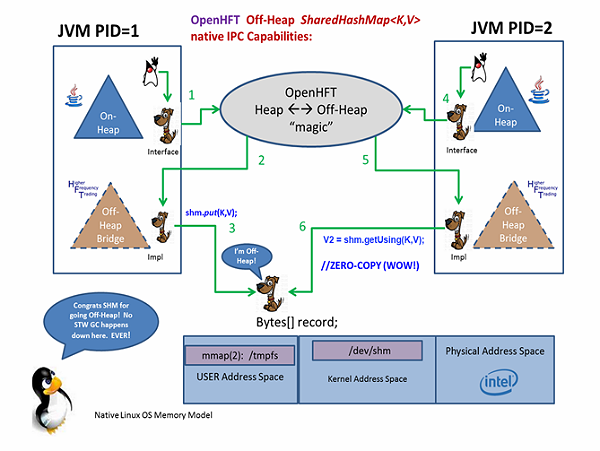
下面 6 个编号的段落对上图进行了描述。
#1. 为了更好地阐述上图中的流程,假设 PID 1 定义了一个BondVOInterface,它是符合JavaBean 约定的。我们想要阐述(按照上图中的数字顺序)如何操作 Map<String,BondVOInterface>,这种方式会着重强调非堆的优势。
public interface BondVOInterface {
/* add support for entry based locking */
void busyLockEntry() throws InterruptedException;
void unlockEntry();
long getIssueDate();
void setIssueDate(long issueDate); /* time in millis */
long getMaturityDate();
void setMaturityDate(long maturityDate); /* time in millis */
double getCoupon();
void setCoupon(double coupon);
// OpenHFT Off-Heap array[ ] processing notice ‘At’ suffix
void setMarketPxIntraDayHistoryAt(@MaxSize(7) int tradingDayHour, MarketPx mPx);
/* 7 Hours in the Trading Day:
* index_0 = 9.30am,
* index_1 = 10.30am,
…,
* index_6 = 4.30pm
*/
MarketPx getMarketPxIntraDayHistoryAt(int tradingDayHour);
/* nested interface - empowering an Off-Heap hierarchical “TIER of prices”
as array[ ] value */
interface MarketPx {
double getCallPx();
void setCallPx(double px);
double getParPx();
void setParPx(double px);
double getMaturityPx();
void setMaturityPx(double px);
double getBidPx();
void setBidPx(double px);
double getAskPx();
void setAskPx(double px);
String getSymbol();
void setSymbol(String symbol);
}
}
PID 1(在上图的步骤 1 中,使用接口)调用了一个 OpenHFT SharedHashMap工厂,代码可能会像如下所示:
SharedHashMap<string bondvointerface=""> shm = new SharedHashMapBuilder()
.generatedValueType(true)
.entrySize(512)
.create(
new File("/dev/shm/myBondPortfolioSHM"),
String.class,
BondVOInterface.class
);
BondVOInterface bondVO = DataValueClasses.newDirectReference(BondVOInterface.class);
shm.acquireUsing("369604103", bondVO);
bondVO.setIssueDate(parseYYYYMMDD("20130915"));
bondVO.setMaturityDate(parseYYYYMMDD( "20140915"));
bondVO.setCoupon(5.0 / 100); // 5.0%
BondVOInterface.MarketPx mpx930 = bondVO.getMarketPxIntraDayHistoryAt(0);
mpx930.setAskPx(109.2);
mpx930.setBidPx(106.9);
BondVOInterface.MarketPx mpx1030 = bondVO.getMarketPxIntraDayHistoryAt(1);
mpx1030.setAskPx(109.7);
mpx1030.setBidPx(107.6);</string>,>
现在,会发生一些堆 →非堆的魔法。请仔细观察……在本文所带给您的整个旅程中,将要分享给您的“魔法”是旅程中“最美的风景”:
#2.在运行时,每个进程调用上面的 OpenHFT 工厂方法时,会生成并编译一个BondVOInterface£native 内部实现,它会完全负责必要的字节位置算法(byte addressing arithmetic),从而实现充分完整的非堆 abstractAccess() / abstractMutate() 操作符集合(通过该接口的 getXX()/setXX() 方法,这些方法符合 Java Bean 的方法签名约定)。它们所造成的效果就是 OpenHFT 在运行时会使用你的接口并将其编译为实现类,这个实现类会作为具体非堆功能的桥梁。数组(array)也是类似的,会使用基于索引的 getter 和 setter。数组的接口也会像外层接口一样。数组的 setter 和 getter 方法签名格式为setXxxxAt(int index, Type t); 和getXxxxAt(int index); (注意,‘At’后缀同时适用于数组的 getter/setter 签名)。
这是都是在运行时为你生成的,借助于进程中的 OpenHFT JIT 编译器。你所要做的就是提供接口。非常酷,对吧?
#3. PID 1 然后调用 OpenHFT 的 API shm.put(K, V);,从而按照 Key (V = BondVOInterface),将数据写入到非堆的 SHM 中。我们已经跨过了在 [2] 中所构建的 OpenHFT 桥。
我们已经实现了非堆!非常有意思吧?:-)
让我们再从 PID 2 的视角看一下是怎么做到的。
#4. 只要 PID 1 完成将数据放到非堆 SHM 之中,PID 2 现在就可以调用完全相同的 OpenHFT 工厂了,如下所示:
SharedHashMap<string bondvointerface=""> shmB = new SharedHashMapBuilder()
.generatedValueType(true)
.entrySize(512)
.create(
new File("/dev/shm/myBondPortfolioSHM"),
String.class,
BondVOInterface.class
);</string>,>
以这样的方式,跨越了 OpenHFT 构造的连接桥,获得了 _ 完全相同的 _ 非堆 OpenHFT SHM 引用。当然,这假设 PID 1 和 PID 2 位于相同的本地主机上,共享通用的 **/dev/shm视图(并且有相同的权限访问同一个/dev/shm/myBondPortfolioSHM** 文件)。
#5. PID 2 然后就可以调用V = shm.get(K);(每次这都会创建一个新的非堆引用),PID 2 也可以调用V2 = shm.getUsing(K, V);,后者会重用你所选择的非堆引用(如果K不是Entry的话,会返回 NULL)。在 OpenHFT API 中,其实还有第三个可以供 PID 2 使用的get 方法签名:V2 = acquireUsing(K,V);,它的区别在于,如果K 不是一个Entry的话,你所得到的并不是 NULL,而是会 _ 返回一个引用 _,这个引用指向了一个新创建的 _ 非 NULL_ 的V2占位符。这个引用能够让 PID 2 在 _ 合适的时候 _ 操作 SHM 的非堆V2 Entry。
注意:当 PID 2 调用V = shm.get(K); 时,它会返回一个新的非堆引用。这会产生一些垃圾,但是在丢弃它之前,你能够一直持有对这个数据的引用。然而,当 PID 2 调用V2 = shm.getUsing(K, V); 或者 **V2 = shm.acquireUsing(K, V);**的时候, 非堆引用转移到了新 key 的位置上,这个操作跟 GC 是没有关系的,因为在这里你重复利用了自己的东西。
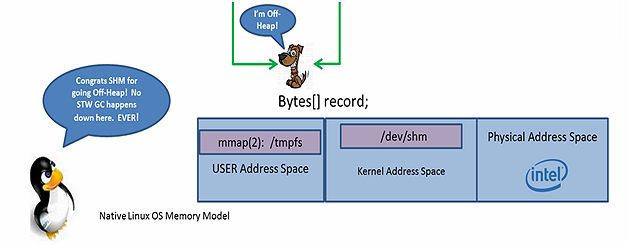
注意:在此时没有出现复制,只是对非堆空间中数据的位置进行了设置和变更。
BondVOInterface bondVOB = shmB.get("369604103");
assertEquals(5.0 / 100, bondVOB.getCoupon(), 0.0);
BondVOInterface.MarketPx mpx930B = bondVOB.getMarketPxIntraDayHistoryAt(0);
assertEquals(109.2, mpx930B.getAskPx(), 0.0);
assertEquals(106.9, mpx930B.getBidPx(), 0.0);
BondVOInterface.MarketPx mpx1030B = bondVOB.getMarketPxIntraDayHistoryAt(1);
assertEquals(109.7, mpx1030B.getAskPx(), 0.0);
assertEquals(107.6, mpx1030B.getBidPx(), 0.0);
#6. 非堆记录是一个引用,它包装了 Bytes 以用来进行非堆的操作,同时还包装了一个偏移量(offset)。通过对这两者进行变更,内存中的任何区域都能够访问到,就如同它是你所选择的接口那样。当 PID 2 操作‘shm’引用时,它要设置正确的 Bytes 和偏移量,这会通过读取存储在 /dev/shm 文件中的 hash map 来进行计算。在 getUsing() 返回后,对于偏移量的计算就会非常简单并且是内联执行的,也就是说,一旦代码被 JIT 之后,get() 和 set() 方法就会变为简单的机器码指令,以实现对这些域的访问。只有你所访问的域会被读取或写入,真正的零复制(ZERO-COPY)!太漂亮了!
//ZERO-COPY
// our reusable, mutable off heap reference, generated from the interface.
BondVOInterface bondZC = DataValueClasses.newDirectReference(BondVOInterface.class);
// lookup the key and give me my reference to the data if it exists.
if (shm.getUsing("369604103", bondZC) != null) {
// found a key and bondZC has been set
// get directly without touching the rest of the record.
long _matDate = bondZC.getMaturityDate();
// write just this field, again we need to assume we are the only writer.
bondZC.setMaturityDate(parseYYYYMMDD("20440315"));
//demo of how to do OpenHFT off-heap array[ ] processing
int tradingHour = 2; //current trading hour intra-day
BondVOInterface.MarketPx mktPx = bondZC.getMarketPxIntraDayHistoryAt(tradingHour);
if (mktPx.getCallPx() < 103.50) {
mktPx.setParPx(100.50);
mktPx.setAskPx(102.00);
mktPx.setBidPx(99.00);
// setMarketPxIntraDayHistoryAt is not needed as we are using zero copy,
// the original has been changed.
}
}
// bondZC will be full of default values and zero length string the first time.
// from this point, all operations are completely record/entry local,
// no other resource is involved.
// now perform thread safe operations on my reference
bondZC.addAtomicMaturityDate(16 * 24 * 3600 * 1000L); //20440331
bondZC.addAtomicCoupon(-1 * bondZC.getCoupon()); //MT-safe! now a Zero Coupon Bond.
// say I need to do something more complicated
// set the Threads getId() to match the process id of the thread.
AffinitySupport.setThreadId();
bondZC.busyLockEntry();
try {
String str = bondZC.getSymbol();
if (str.equals("IBM_HY_2044"))
bondZC.setSymbol("OPENHFT_IG_2044");
} finally {
bondZC.unlockEntry();
}
在上面的图中,非常重要的就是要理解完整的 OpenHFT 堆 ←→ 非堆转换是如何实现的。
事实上,OpenHFT SHM 实现在步骤#6 中,在运行时会拦截 **V2 = shm.getUsing(K, V);** 调用的第二个参数的内容。实质上,SHM 实现是这样查询的
(
( arg2 instanceof Byteable ) ?
ZERO_COPY<b> :</b>
COPY
)
并且它会以零复制的方式执行(通过引用更新),而不是完全复制(COPY)的方式来执行(通过 Externalizable)。
非堆引用功能的核心接口就是 Byteable,它使得引用能够被(重新)设置。
public interface Byteable {
void bytes(Bytes bytes, long offset);
}
如果你要实现自己的支持这个方法的类,那么你尽可以实现或生成自己的 Byteable 类。
现在,就像我们所提到的那样,你可能依然会想“所有的这一切发生地太 _ 神奇 _ 了”。这里其实会发生很多的事情以实现这个神奇的功能,并且所有事情的发生都是与外部无关的,也就是 _ 发生在正在执行的应用进程之内!_ 如果使用运行时编译器(Run-Time-Compiler)的话,它会将我们的BondVOInterface作为输入,OpenHFT 内部会确定接口的源代码并对源码进行编译(同样是在进程内),将其编译为 OpenHFT 所能理解的实现类。如果你不想让这个类在运行时生成的话,那么可以预先生成这个类,并且在构建阶段进行编译。OpenHFT 内部会将这个新生成的实现类加载到运行上下文之中。此时,运行时会物理执行所生成的BondVOInterface£native内部类的方法,这些方法也是生成的,以实现零复制操作符的功能,转换为非堆Bytes[]的记录。这项功能是零复制的,只要你在一个线程内执行了线程安全的操作,它就会对另外的线程可见,即便这个另外的线程可能位于其他的进程之中。.
现在,你已经了解了 OpenHFT SHM 魔法的本质:Java 如今有了 _ 真正 _ 零复制的 IPC。
嘛哩嘛哩哄!
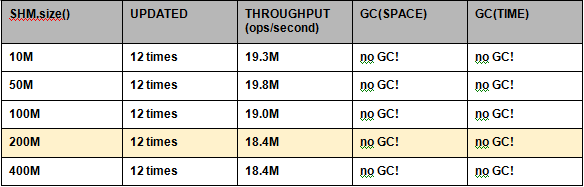
性能结果:CHM 与 SHM
Linux 13.10,i7-3970X CPU @ 3.50GHz,hex core, 32 GB 内存。
SharedHashMap -verbose:gc -Xmx****64m
And there you have the essence of the OpenHFT SHM magic: Java now has true ZERO-COPY IPC.
Abra Cadabra!
PERFORMANCE RESULTS: CHM vs.SHM
On Linux 13.10, i7-3970X CPU @ 3.50GHz, hex core, 32 GB of memory.
SharedHashMap -verbose:gc -Xmx****64m
ConcurrentHashMap -verbose:gc -Xmx****30g
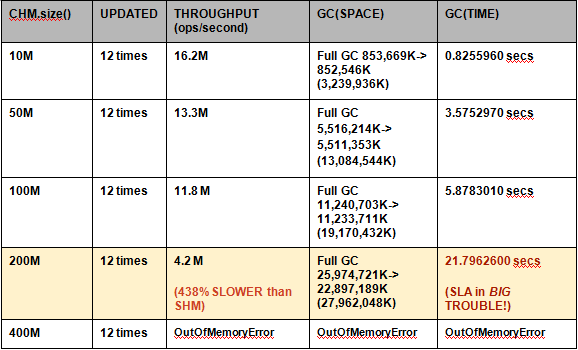
当然,CHM 比 SHM 慢 438% 的主要原因在于 CHM 会经历长达 21.8 秒的 STW GC。但是从 SLA 角度来看,问题产生的原因(对于这个诱因没有补救措施)并不重要。从 SLA 角度来看,事实上 CHM 就是要慢 438%。从 SLA 的角度来看,在这个测试中,CHM 的性能慢得 _ 让人无法接受 _。
适配 JSR-107:将 SHM 作为(100% 协作的)非堆的 JCACHE 操作对象
在 2014 年的第二季度,Java Community Process 发布了 JSR-107 EG 的 Release 版本 JCACHE——Java 缓存的标准 API/SPI。 JCACHE 对于 Java 缓存社区的作用就像 JDBC 对于 Java RDBMS 社区的作用一样。JCACHE 的核心和本质在于其基础的缓存操作对象接口: javax.cache.Cache<K,V> 。如果你仔细看一下这个 Cache APi,就会清楚地看到 Cache 完全就是 Map 的一个超集(有一些不太实用的差异)。JCACHE 的主要目标之一在于帮助交付一个可扩展的(横向扩展和纵向扩展)解决方案,以解决 Java 数据的本地化、延迟以及缓存的问题。所以,如果 JCACHE 的主要操作对象是一个 Map,并且 JCACHE 的核心目标之一在于解决数据本地化 / 延迟的问题,那么采用 OpenHFT 的非堆 SHM 作为 JCACHE 主要操作对象 _ 接口 _ 的 _ 实现 _ 会带来多大的好处呢?在很多的 Java 缓存用例之中,OpenHFT 非堆 SHM 的目标都是非常 _ 完美 _ 的方案。
我们将会用一点时间(请安坐),在本文中分享一下如何将 OpenHFT SHM 作为完整的 JSR-107 非堆 JCACHE 操作对象。在此之前,我们想要澄清一个事实,那就是 javax.cache.Cache 接口是 java.util.Map 接口功能的一个超集。我们需要精确地知道“这个超集有多大”?……这会影响到我们要做多少工作才能 100% 完整彻底地采用 SHM 作为实现。
-Cache 必须要提供而基本 HashMap 所没有提供的都有什么呢?
- 清除(Eviction)、过期(Expiration)
- 弱引用(WeakRef)、强引用(StrongRef)(其实这与非堆 Cache 实现无关)
- 本地化角色(Locality Role)(如 Hibernate L2)
- EntryProcessors
- ACID 事务
- 事件监听(Event Listener)
- “Read Through”操作(同步 / 异步)
- “Write Behind”操作(同步 / 异步)
- JGRID 相关的功能( JSR-347 )
- JPA 相关的功能
- OpenHFT+Infinispan 的“婚礼日” 计划 (JCACHE 的庆典)
下图展现了社区驱动的OpenHFT 编程人员在采用/ 贡献OpenHFT 非堆SHM 作为完整的JSR-107 协作JCACHE 操作对象时所需要的很少范围的开发工作(社区驱动的开源JCACHE 提供商= RedHat Infinispan )。

(点击图片放大)
结论:非堆HashMap 的现在和未来……“直到奶牛不干了,回家的那一天”
在这个旅程接近“最后一站”的时候,我们用一个类比的故事来向你告别,并解答你所关心的问题。
社区驱动的开源非堆HashMap 提供商以及JCACHE 提供厂商(包括商业的和开源的)之间的业务关系可以是和谐且互相协作的。在为终端用户提供更为愉悦的非堆体验方面,它们中的每一个都扮演着重要的角色。非堆HashMap 提供者可以交付核心的非堆HashMap(作为JCACHE 的)操作对象。JCACHE 厂商(包括商业的和开源的)可以采纳这个操作对象到他们的产品之中,然后提供核心的JCACHE(和基础设施)。
这种关系就类似于奶牛(也可以说是乳业农场主,核心_ 操作对象_ 即牛奶的生产者)与奶制品公司(牛奶_ 操作_ 的生产者,操作集合={巴氏杀菌、脱脂、1%、2%、各占一半等等})之间的关系。这两个组合(奶牛和乳业公司)结合起来能够生产出终端用户更为喜欢的产品,这要优于两者(奶牛和乳业公司)不进行合作的场景。终端用户对这两者都需要。
但是要给终端用户一个“购买者注意!”的提示:
如果有人遇到商业厂商有志于交付闭源的HashMap/Cache 解决方案,并且宣称他们闭源的非堆操作对象要“优于”开源社区驱动的方式,那么,只需要记住这一点:
_ 乳业公司并不制造牛奶。_只有奶牛才会制造牛奶。
奶牛会一直生产牛奶,24/7,并且完全没有其他的干扰。乳业公司能够让牛奶更加美味(各占一半、2%、1%、脱脂)……所以,他们 _ 确实 _ 有机会扮演重要的角色……但是他们并不生产牛奶。现在,开源的“奶牛”正在生产非堆 HashMap 这种“牛奶”。如果商业解决方案厂商认为他们制造的 _ 那种 _ 牛奶更加美味,那么尽可以去做,这样的努力是所有人都欢迎的。但是,这些供应商不应该宣称他们自己的牛奶是“更好”的牛奶。只有奶牛才会生产最好的牛奶。
总之,考虑到 Java 为高性能计算社区所带来的改变是很令人兴奋的。事情确实有了很多的变化,而且所有的变化都是往更好的方向发展。
从并发包之中,从不断改善的现代GC 方案之中,从非阻塞I/O 功能之中,从 Sockets Direct Protocol 的原生 RDMA, JVM intrinsics 之中,……,再到原生的 Caching 、OpenHFT 的 SHM 作为原生的IPC 通信方式以及该OpenJDK 非堆JEP 所呼吁的机器级别HTM 辅助功能(machine level HTM-assist feature),有一件事是确定的:OpenJDK 平台社区在提升性能方面_ 确实_ 有着很高的优先级。
来看一下HashMap 这个可爱的_ 老_ 家伙_ 现在_ 能够做些什么吧!借助于OpenJDK、OpenHFT 和Linux,非堆HashMap 在“较低的位置”(也就是原生OS)有了新朋友。

现在不会受到STW GC 的任何干扰了,HashMap 作为重要的HPC 数据结构操作对象,获得了重生。HashMap,保持永远_ 年青_ 吧!
感谢你们陪伴我们的旅程,希望你喜欢这个经历。下次再见。
关于作者
 Peter K. Lawrey是 Higher Frequency Trading Ltd. 的首席咨询顾问,以及 OpenHFT 项目的领导者。他是 Java Community Process 的成员,目前在活跃的 JCP 专家组参与定义分布式数据网格(Distributed Data Grids,JSR-347)的 Java 标准 API。他是具有 500 个成员的 Performance Java Users’ Group 的创建者(目前该 Google 群组已经有 1500 多位成员——译者注),以及技术博客“Vanilla Java”(230 篇文章,3 百万的站点点击)的作者。Peter 毕业于 Melbourne University,拿到了两个学位,分别是计算机科学和电气工程。Peter 在 StackOverflow 的问答响应排名中位居前三。最近的五年来,他致力于开发、支持以及提供咨询,并在欧洲和美国东部为高频率的交易系统提供培训。
Peter K. Lawrey是 Higher Frequency Trading Ltd. 的首席咨询顾问,以及 OpenHFT 项目的领导者。他是 Java Community Process 的成员,目前在活跃的 JCP 专家组参与定义分布式数据网格(Distributed Data Grids,JSR-347)的 Java 标准 API。他是具有 500 个成员的 Performance Java Users’ Group 的创建者(目前该 Google 群组已经有 1500 多位成员——译者注),以及技术博客“Vanilla Java”(230 篇文章,3 百万的站点点击)的作者。Peter 毕业于 Melbourne University,拿到了两个学位,分别是计算机科学和电气工程。Peter 在 StackOverflow 的问答响应排名中位居前三。最近的五年来,他致力于开发、支持以及提供咨询,并在欧洲和美国东部为高频率的交易系统提供培训。
 Ben D. Cotton III 是 J.P.Morgan Chase & Co. 的 IT 咨询顾问,目前在 UHPC Linux 超级计算机上使用 Java 数据网格技术,以判断和计算实时的流动资产风险。Ben 毕业于 Rutgers University,获得了计算机科学的学位。在职业生涯的最初 11 年中,他在 AT&T 贝尔实验室工作,编写 ellMac32-ASM/C/C++ 代码来支持无数的专用通信、网络分析以及提供协议,最近的 14 年中他在编写 Java 代码,实现低延迟、高吞吐、事务性、固定收益、金融衍生物、电子交易、清算、定价以及风险控制的系统。和 Peter 一样,Ben 也是 JSR-347 EG 的成员。
Ben D. Cotton III 是 J.P.Morgan Chase & Co. 的 IT 咨询顾问,目前在 UHPC Linux 超级计算机上使用 Java 数据网格技术,以判断和计算实时的流动资产风险。Ben 毕业于 Rutgers University,获得了计算机科学的学位。在职业生涯的最初 11 年中,他在 AT&T 贝尔实验室工作,编写 ellMac32-ASM/C/C++ 代码来支持无数的专用通信、网络分析以及提供协议,最近的 14 年中他在编写 Java 代码,实现低延迟、高吞吐、事务性、固定收益、金融衍生物、电子交易、清算、定价以及风险控制的系统。和 Peter 一样,Ben 也是 JSR-347 EG 的成员。
查看英文原文: OpenJDK and HashMap …. Safely Teaching an Old Dog New (Off-Heap!) Tricks





{kind=link}